
Database queries power essential business operations. When these queries slow down, critical processes suffer. One effective solution for these slowdowns is to fine-tune the database configuration, which dramatically improves query performance. Unfortunately, this is often difficult to do in practice. While modern databases offer dozens of configuration options, experimenting with them in production (or on sensitive production data) introduces data access bottlenecks and carries privacy risk. As a result, many organizations are forced to tolerate slow queries because they lack a safe way to fine-tune their database config.
Epiconcept, a leading software provider specializing in healthcare and epidemiological research, faced this exact challenge. For a cancer study, their team needed to run a daily aggregate SQL query that was complex and slow. Epiconcept used MariaDB, a database provider that offers a number of different database config options that could make the query run faster, including buffer sizes, caching, and table indexing. Epiconcept even had different fine-tuning algorithms ready to test. The only problem was that underlying patient data was too sensitive to use for testing.
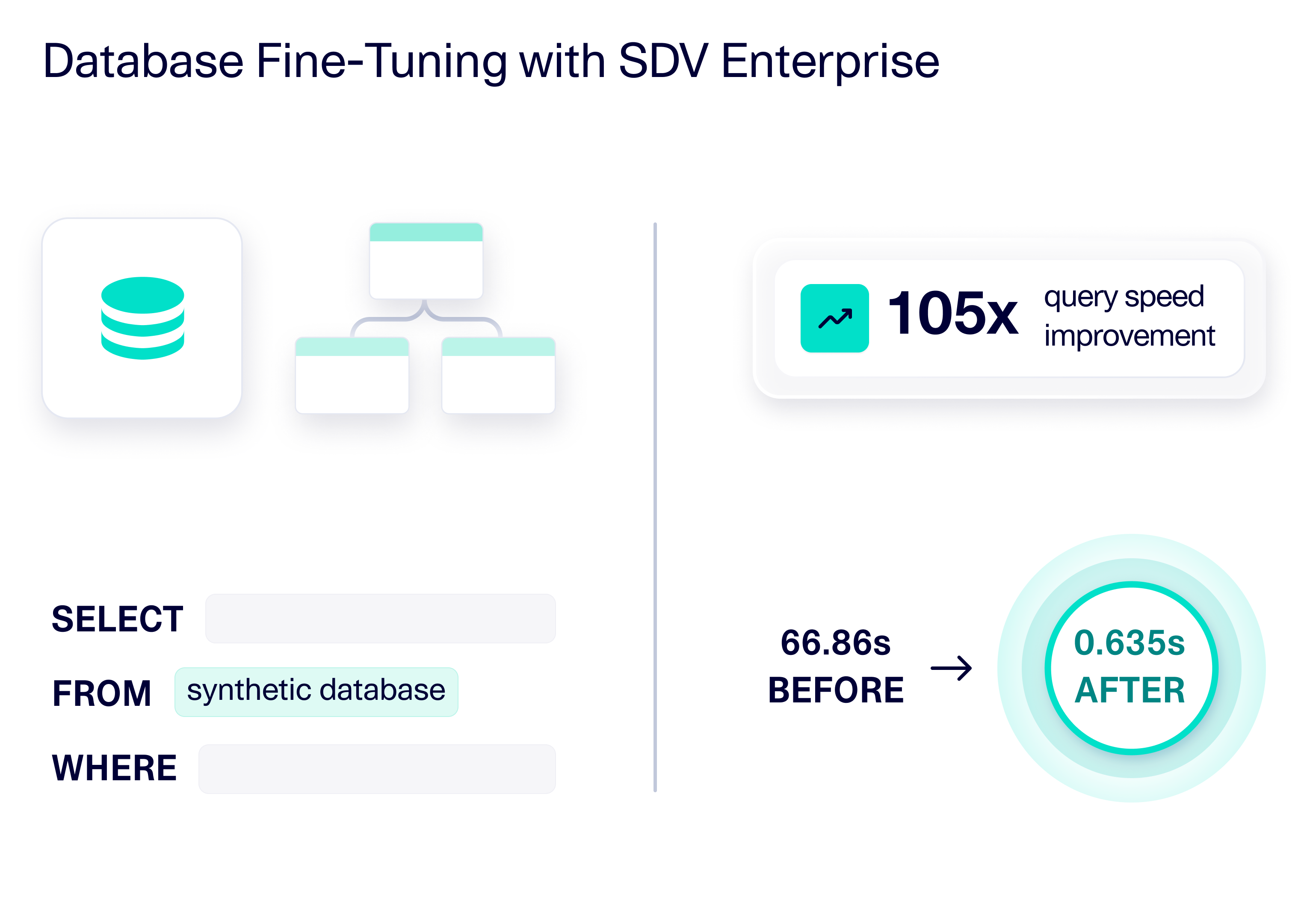
By adopting SDV Enterprise, Epiconcept unlocked a new path forward. They used SDV Enterprise to generate a complete, statistically realistic patient database–entirely synthetic and safe to use for fine-tuning the database config. With this synthetic environment, their engineers were finally able to analyze the query, adjust database parameters, and experiment freely without privacy concerns or operational risk. The results were transformative: They achieved a 105x improvement in query performance and came away with a scalable framework that they can apply to future initiatives that require database fine-tuning.
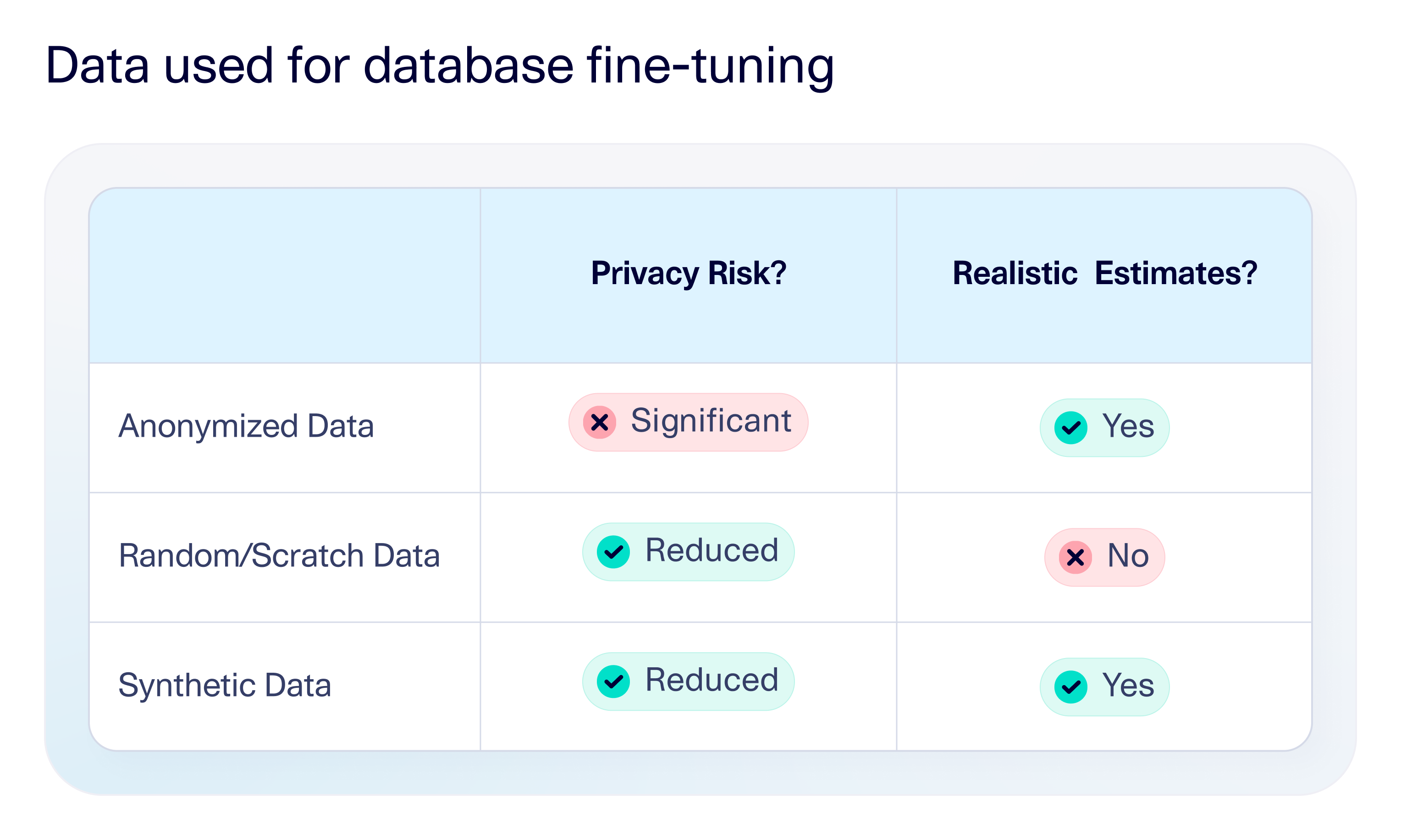
Synthetic data—not anonymized or random data—is the best solution for fine-tuning database configs
Synthetic data was a critical piece of the solution for Epiconcept. Alternative solutions included anonymized data or randomly generated data, but these had their own issues. Anonymizing the production data would require the team to maintain a separate anonymization script and review process. Even then, anonymization always carries extra privacy risk because it's based on the original patients. Creating a random dataset from scratch with manual or rule-based creation would alleviate these privacy concerns, but the resulting data would not have the same properties as the original data. Therefore, the estimated query speeds would not be accurate.
For more perspective, consider the complexity of Epiconcept's SQL query: It touched 37 tables with over 20 joins and 10 subqueries. Some of the logic also filtered and joined data according to specific rules; for example, choosing subsets of data that were not null, or joining data only under specific conditions. Since the goal was to improve the query speed on the real data, their test data needed to have similar characteristics so that it would produce realistic performance estimates. Synthetic data was uniquely suited to this goal, as it represented entirely new patients (allowing for higher privacy) but kept the same data characteristics as the original patients (allowing for realistic estimates). The table below summarizes the query logic and how it relates to requirements for synthetic test data.

Based on SDV Enterprise's capabilities, the team was confident that optimizing the database config on the synthetic data would translate to real results. This testing showed that the original query took 66.86 seconds on average when run on multi-core machines. After database optimization, the query took only 0.635 seconds on the same machines–an improvement of 105x.
SDV Enterprise created synthetic data for a 37-table database in 55 min
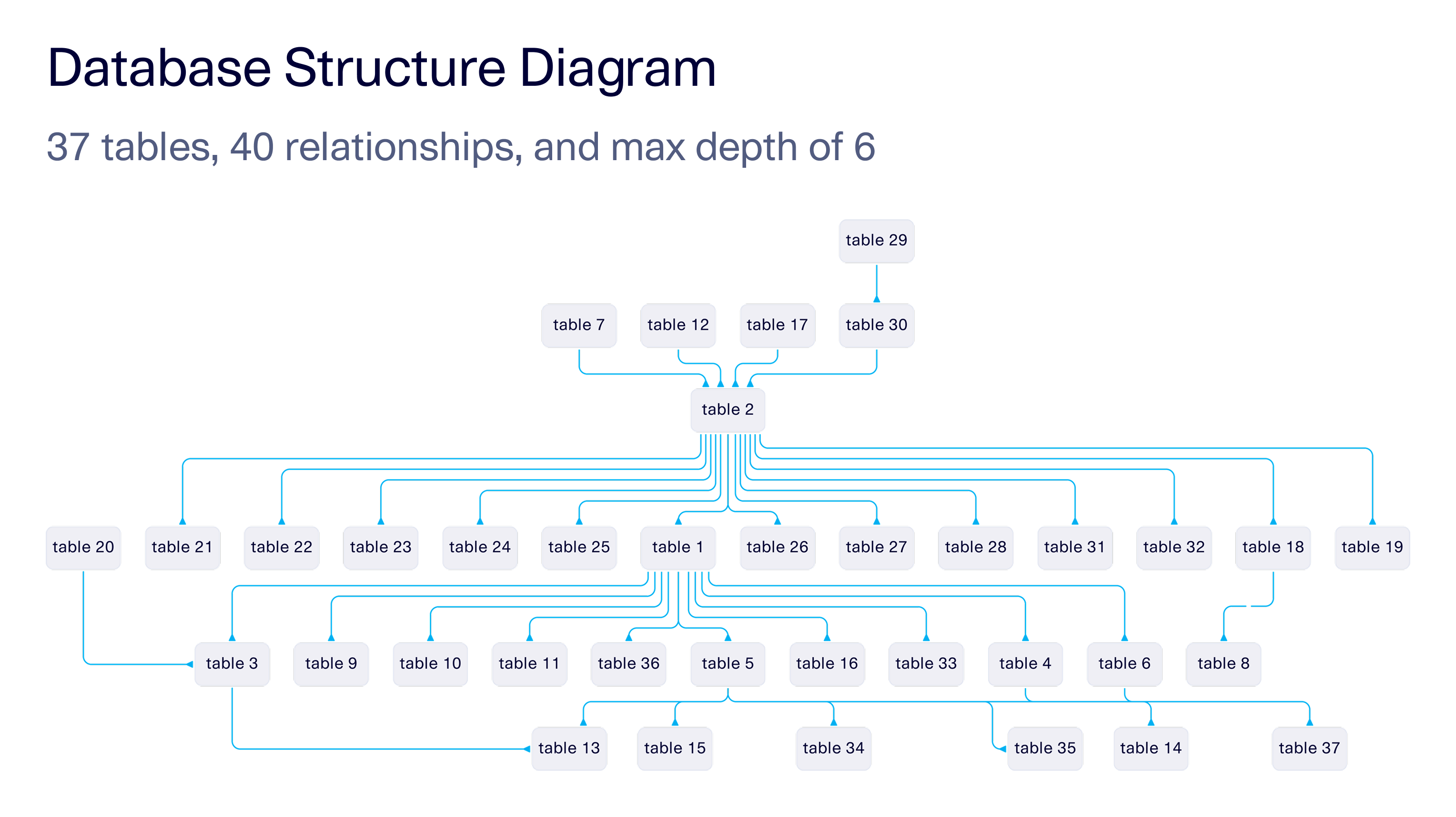
Creating synthetic data with SDV Enterprise was fast and straightforward. Epiconcept began by identifying the database–a complex schema containing more than 100GB of data. The team then narrowed the scope to only the tables required for the query, removing system tables, logs, and other nonessential data. This produced a focused dataset of 3GB spanning 37 interconnected tables, with 40 relationships and a schema depth of six. The image below shows the structure of the database schema, with the table names anonymized.
To meet security requirements, Epiconcept followed best privacy practices and deployed SDV Enterprise in a fully isolated environment. In 45 minutes, SDV Enterprise learned the structure and patterns of the 3GB dataset and saved the resulting model in a file. Then, at any point, Epiconcept could use the model to generate synthetic data. The model generated an equal sized, fully synthetic dataset in 10 minutes. The synthetic data was exported as CSV files and used to populate a brand-new MariaDB database. SDV's synthetic data was fully compatible out-of-the-box, with no additional post-processing required.
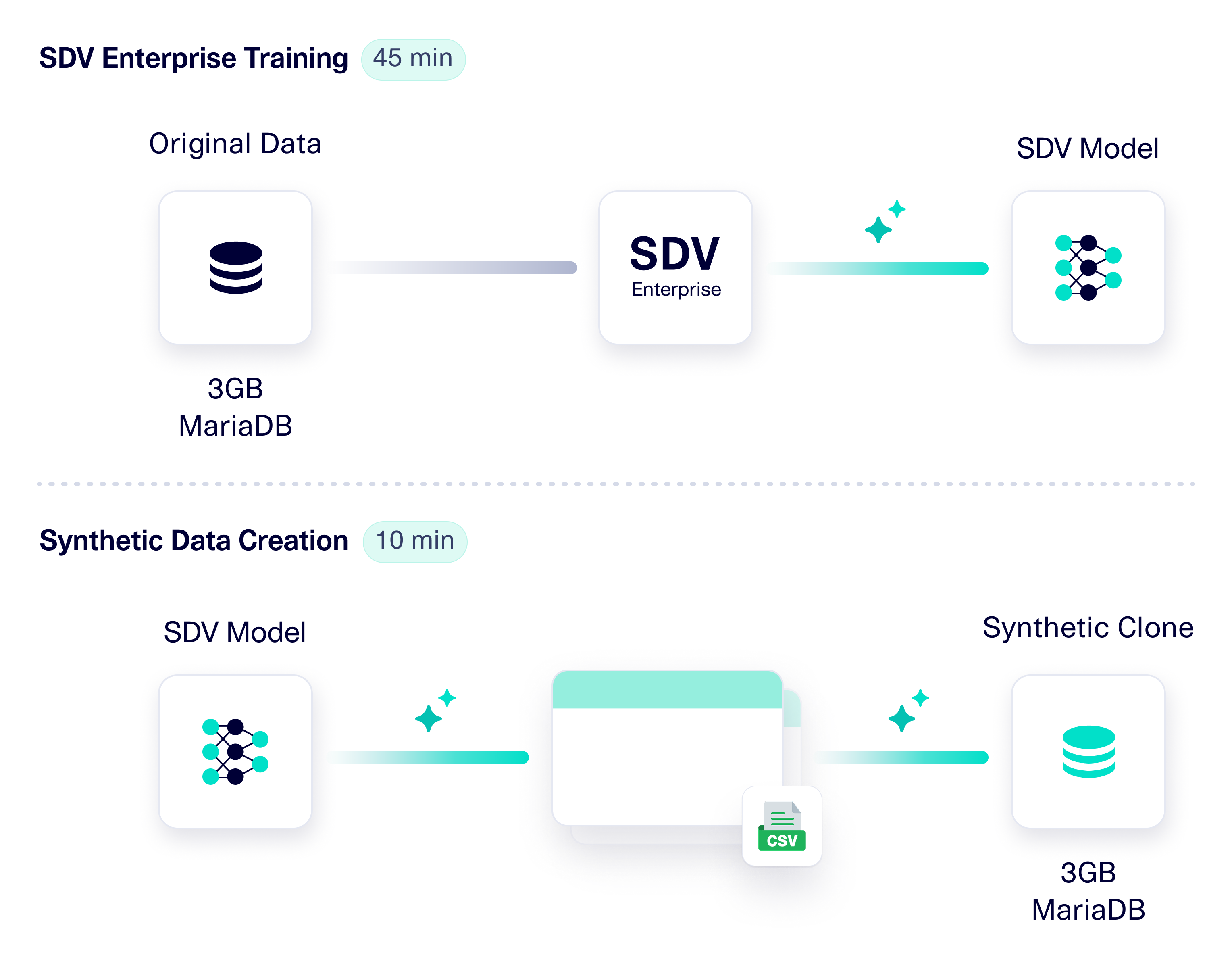
The result was a fully synthetic, production-like clone of the original database–with realistic patients and records, but no real patient data. With this safe database in place, Epiconcept could confidently fine-tune database parameters and improve query performance, eliminating both privacy risk and operational friction.
Thanks to SDV's synthetic data, Epiconcept created a structured approach to fine-tuning database configs
For the first time, Epiconcept could safely and systematically experiment with database config parameters to improve SQL query performance. Synthetic data makes it possible to adopt a structured, repeatable approach for database fine-tuning, including:
Testing different database fine-tuning algorithms
Running queries repeatedly on the same database to evaluate caching behavior
Executing multiple queries in parallel to simulate high-load, high-concurrency conditions
Benchmarking performance across machines with varying RAM sizes and CPU cores
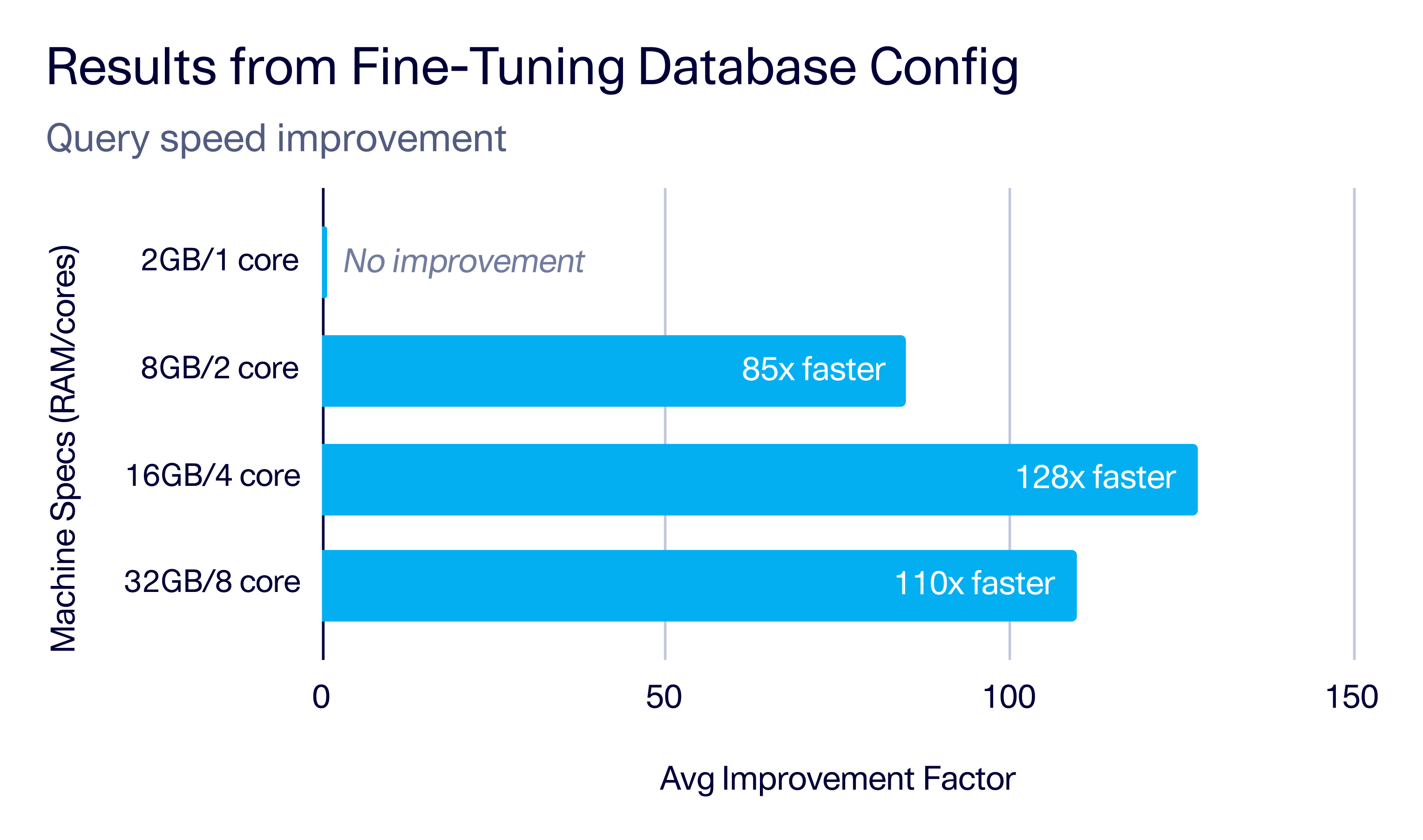
With this setup in place, Epiconcept executed the problematic query across all experimental database configs. The results were clear: Query performance improved dramatically on multi-core machines. As shown in the graph below, multi-core machines with higher RAM achieved speedups averaging 105x while the single-core machine showed no improvement. Just as importantly, the analysis highlighted diminishing returns when it comes to hardware. While multi-core, high-RAM machines are essential for unlocking performance gains, further scale-ups don't make a difference after about 16GB RAM/4 cores. At this point, the database config is what matters most. This insight allowed Epiconcept to make informed, cost-effective decisions about infrastructure as well as their database fine-tuning strategy.
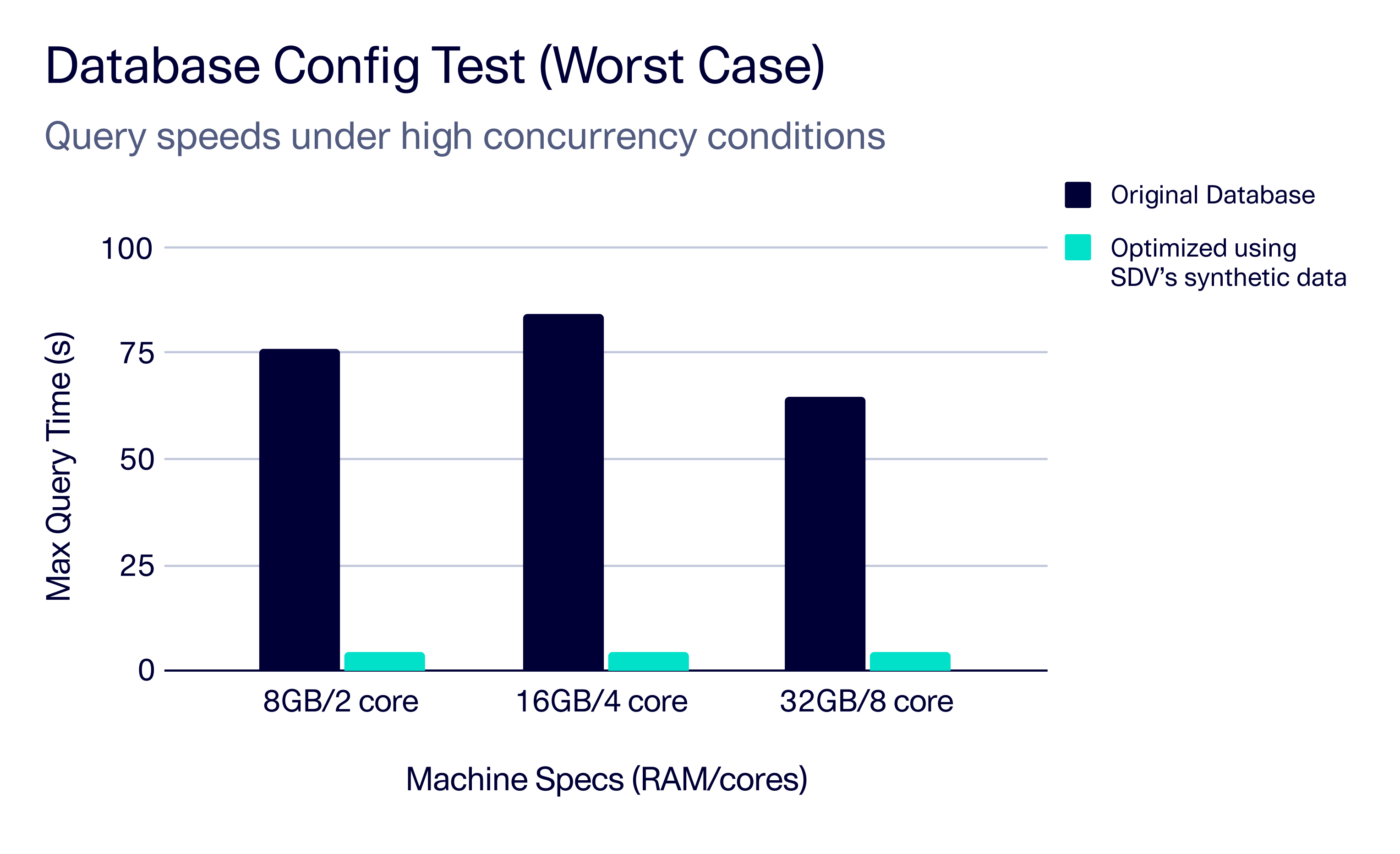
Epiconcept also confirmed that the optimized database config performed reliably under worst-case, high-concurrency conditions. Even when multiple queries ran simultaneously on the same machine, performance gains held steady, giving the team strong confidence in the robustness and production readiness of their database configuration.
With these results powered by SDV’s synthetic data, Epiconcept has now updated the database config in production, reducing both query runtimes and compute costs. Just as importantly, the team has established a systematic, repeatable framework for database configuration, which they plan to apply to other databases to eliminate performance bottlenecks organization-wide.
As a parting thought, Epiconcept has this to say:
