This article was researched by Arnav Modi, a community user. Arnav is a high school student and aspiring data scientist who spent his summer learning about the SDV and how synthetic data is used to perform ML tasks.
One potential use for synthetic data is to replace real data in the development of new machine learning (ML) models. Imagine a scenario where you need to build a predictive ML model – perhaps for a function critical to your business, like predicting customer satisfaction or sales success – with one important consideration: The data is sensitive, so only trusted employees can access it with specific credentials.
Access to sensitive data may create a barrier for a variety of reasons:
- You might not have ML expertise in your organization, which means you need to use external software or contractors to complete the task. However, you are unable to share the data with them.
- Your data is available on a secure, cloud-based platform for trusted employees to access remotely. They work on this data using interactive notebooks. Every time they lose their connection – due to WiFi outages, their laptops falling asleep, etc. – they may lose their work or have to reconnect.
- You have a robust authentication system that your team uses. However, it creates a barrier to entry for rapid, iterative collaboration between members, sharing work and debugging data pipelines. As a result, your collaboration is much slower than it would be if your team could access the data without the need to authenticate.
In cases like this, synthetic data can be an ideal solution: You can create synthetic data based on the original, sensitive data set, and use it more freely during ML development.
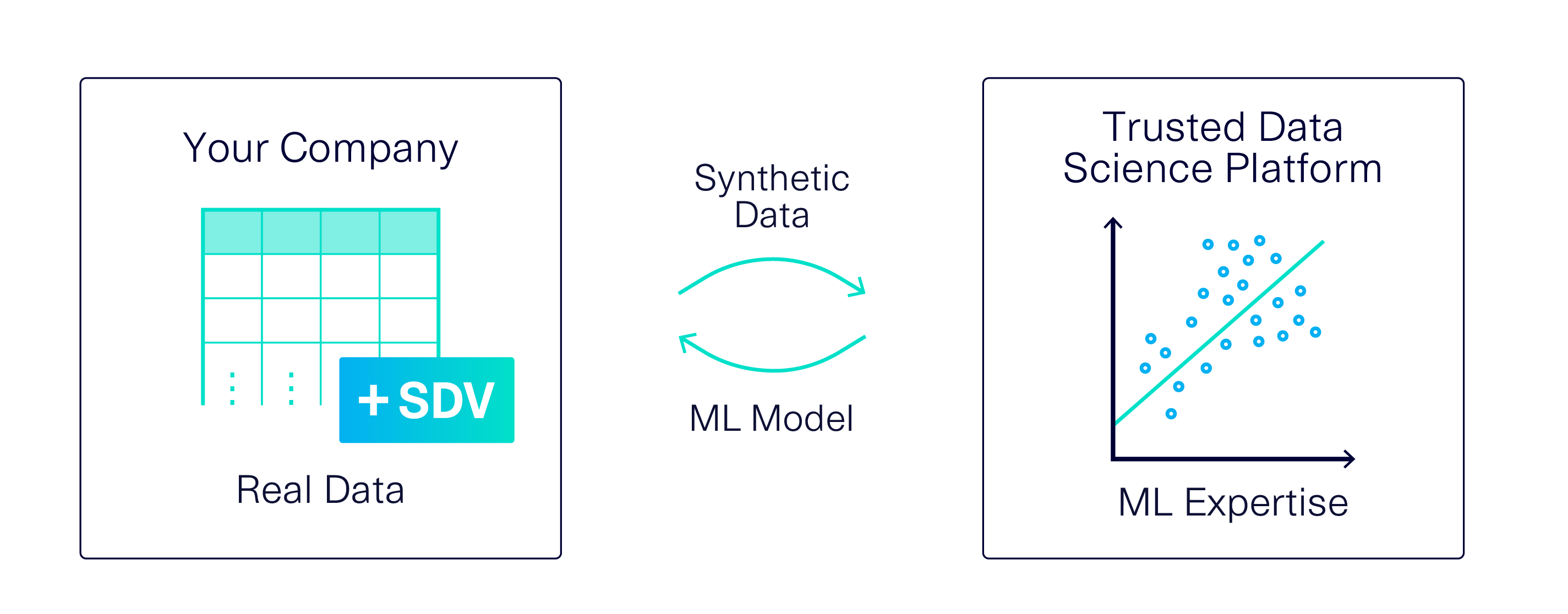
One key question will determine if this method succeeds: Is the synthetic data actually useful for your ML task? We performed an experiment to find out.
In the rest of this article, we'll describe our experimental setup and findings. (You can double-check our work in this Colab Notebook.)
Experimental Setup
If an ML model is trained using synthetic data instead of real data, what happens to the model's performance? To answer this question, we identified 3 publicly available datasets (Income, Bank and Airline) that are associated with particular ML prediction tasks. The datasets and tasks are summarized below.

Our experiment compared the performance of an ML model trained on the original data, vs. one trained on the synthetic data provided by the SDV.
- Control (Original data): How successfully can we complete the ML prediction task if we use the real data? Because some predictions are harder than others, this control helped us identify the overall difficulty of these specific tasks.
- Experiment (Synthetic data): How successfully can we complete the ML prediction task if we use synthetic data instead? We used the SDV's CopulaGAN to generate synthetic data from the three original datasets.
In order to develop and test the ML model, we turned to the SDMetrics library — specifically the ML Efficacy metrics, which build an ML model and evaluate its performance. We used the Binary Decision Tree Classifier and Binary Logistic Regression models. The overall experimental setup is illustrated below.
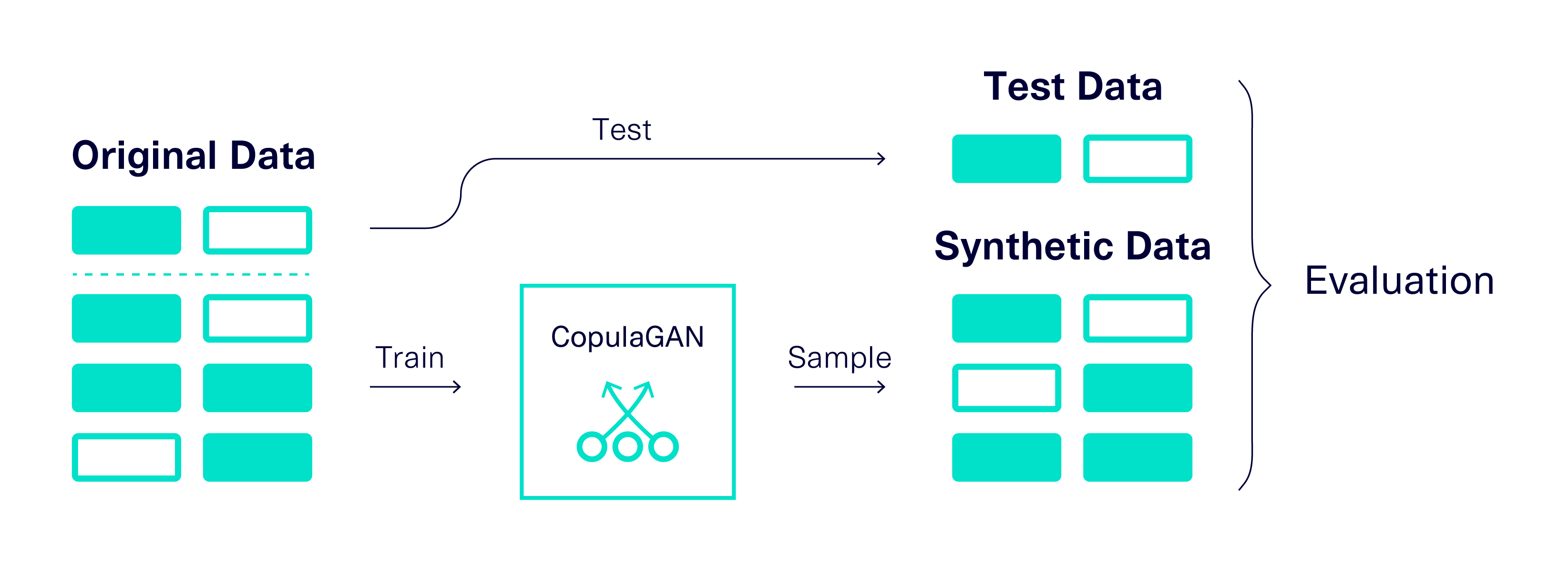
To obtain reliable findings, we ran 3 iterations and averaged the results.
Results
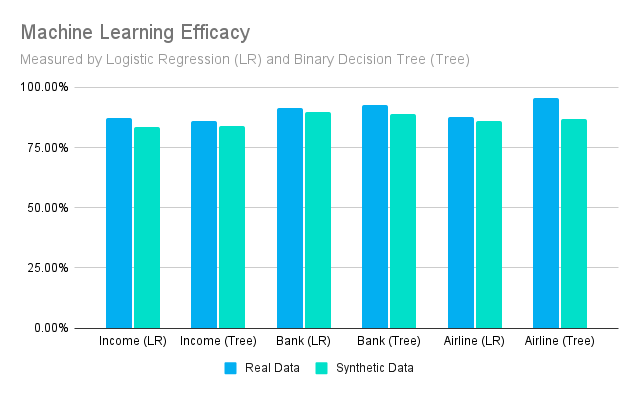
The graph below shows how well we are able to perform an ML task using the original vs the synthetic data.
Discussion
The original data quantifies the general difficulty of the ML task. Looking at these values, we can see that the Income Dataset is the hardest task, as neither of our methods were able to get above 90% accuracy using the original data.
Comparing the datasets allows us to quantify the suitability of synthetic data for ML development. Our results show a loss of between 1 and 9% of the original efficacy value for all comparisons, with a median loss of roughly 2.5%.
It's important to note that the simplifications we've made for this experiment may be resulting in worse accuracy than we would see in real-world use.
- Applying CopulaGAN out-of-the-box to each dataset is simplistic. In a real-world scenario, the model's parameters would likely be explicitly tuned and constraints would be used to improve synthetic data quality.
- The Decision Tree and Logistic Regression evaluators are relatively simplistic ML classifiers. An ML expert (or ML software) might use more advanced techniques.
- In our scenario, the 3rd party delivers a fully trained, ready-to-go ML model. Another approach is to ask them to use the synthetic data to deliver an untrained model – so that you can train it yourself on the real dataset. This alternative setup, which should increase the prediction accuracy, will be a topic for a future article.
In summary, the accuracy loss we observe represents the worst case scenario. In a production environment, higher-quality ML models and more careful tuning of the SDV will likely minimize performance differences between original and synthetic data.
Takeaways
In this article, we quantified the effect of replacing real data with a synthetic data clone for ML development. Our results show a loss of 2.5% accuracy when using synthetic data. Considering these results, we assess that it is reasonable to explore the use of synthetic data for the purpose of ML development.
In order to maximize the utility of the synthetic data, we recommend tuning the SDV model and using constraints to improve the data quality. In future articles, we'll explore more details about using synthetic data for ML.
Are you using the SDV to solve your ML business needs? Publish your findings on the SDV blog as a guest author! Contact us at info@sdv.dev.