Blog
Synthetic Data: Insights, updates and more
Learn more about synthetic data, our product and successful use cases

How to generate synthetic survey responses for market research
Trained AI models do what LLMs cannot: Generate survey responses with the statistical variety and demographic accuracy your analysis depends on.
How to generate synthetic survey responses for market research
Trained AI models do what LLMs cannot: Generate survey responses with the statistical variety and demographic accuracy your analysis depends on.

Why synthetic data is not the same as data masking with ETL
Synthetic data does what ETL pipelines cannot: Create unlimited test data with low infrastructure, storage, and system complexity.
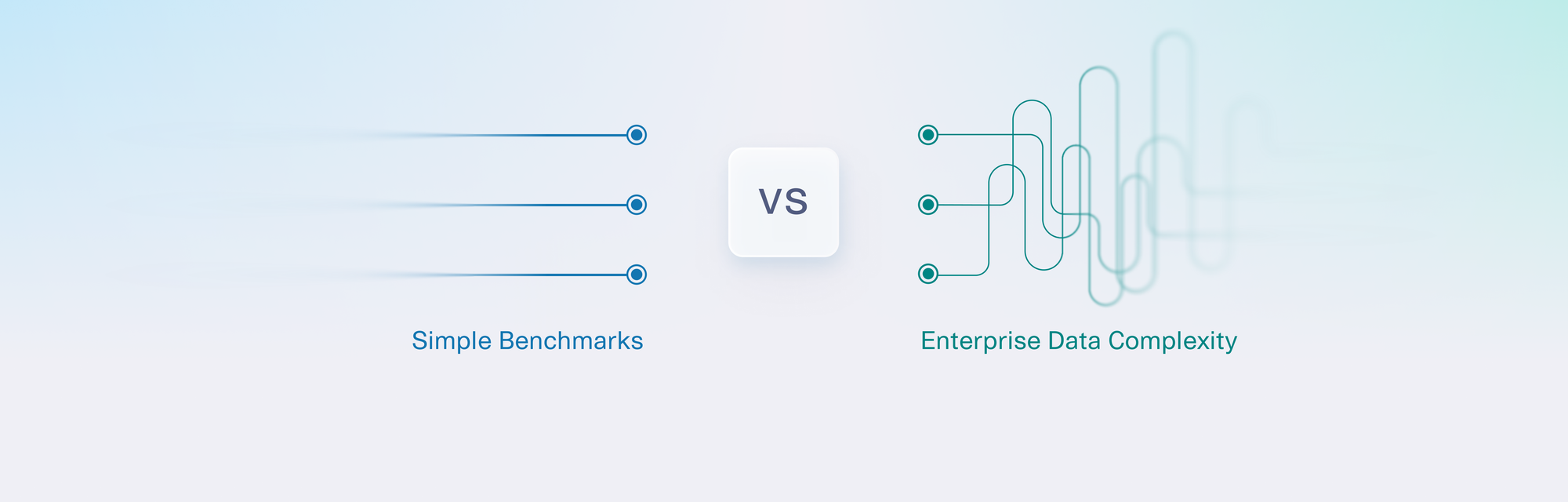
Why are comparisons to SDV Community misleading for enterprise evaluation?
Many vendors compare against SDV Community to signal enterprise readiness—but those comparisons often hide critical gaps. In real enterprise environments, these shortcuts break down. Here’s how to evaluate solutions the right way.

How DataCebo Supports Enterprises: Fast, Safe, and Effective
See how DataCebo enables enterprises to create generative AI models without needing to access their data. With fast debugging, seamless integration, and robust testing, it makes scalable adoption possible.

Differential Privacy for Synthetic Data (Part II): Trust-but-Verify
You can trust that your software is applying differential privacy, but can you verify it for yourself? Use our framework to measure privacy for any synthesizer.

7 signs a synthetic data software violates privacy
Are you evaluating synthetic data vendors? Look out for these signs that their software might be violating privacy.

Differential Privacy for Synthetic Data (Part I): Synthesizer Disclosure
Synthesizers are game-changers for data disclosure and differential privacy. Use them to create unlimited, differentially private synthetic data.

Introducing AI Connectors: Database Integration for Synthetic Data
AI Connectors allow users to create robust, referentially sound synthetic data by connecting to an existing database and automatically creating highly accurate metadata, regardless of the underlying database technology.

Synthetic Data in 2024: The Year In Review
Check out how 2024 has been the biggest year for synthetic data. Google, Apple, Meta, OpenAI all emphasized the importance of using synthetic data in their AI model development. While Snowflake, Databricks, DataCebo and several others released new tooling required to create synthetic data.

Synthesizers are data diversification engines – embrace them!
Synthesizers can create diverse data that is also high quality. Check out how these two vital traits inform each other and drive great business outcomes.
Join the DataCebo Forum
Discuss SDV features, ask questions, and receive help.
Visit the DataCebo ForumExplore our blog
Read our newest insights about synthetic data, updates on our products, and successful use cases.
Read our blog