
If your organization is considering using synthetic data, you might start by researching several synthetic data vendors. Vendors generally provide AI software that learns patterns from your original data and saves the patterns inside a synthesizer artifact. (Vendors may refer to this as an "ML model" or "generator".) The software can use this synthesizer to create synthetic data that matches the statistical patterns of your original data.
When evaluating vendors, it's typical to focus on the final synthetic data that is created – Is it novel? Does it contain the same patterns as the original data? But while good results are vital, they don't cover every base. At DataCebo, we're the developers of the top synthetic data platform, the Synthetic Data Vault (SDV), which is used by over 70 Fortune 500 companies. We've seen firsthand how important it is to zoom out and look at the full, end-to-end workflow that the software is using. The workflow includes the synthesizer artifact that the software produces, the process in which it creates synthetic data, and the synthetic data itself.
Some vendors may not make it easy to know what's going on inside their software, but there are certain warning signs that you can look out for — signs that can indicate critical privacy violations. In this article, we'll walk through 7 warning signs to look for when evaluating a synthetic data vendor. We hope that you can use these signs to guide conversations with the software vendors you're considering, and choose one that can give you synthetic data in a safe and efficient manner.
Warning sign #1: The software doesn't produce a synthesizer artifact for you
The first warning of a potential privacy violation is if the synthetic data software you're considering only gives you synthetic data – and doesn't provide you with a synthesizer artifact that's created along the way. Access to the synthesizer is critical because it provides an insight into how the software is working and it can give you confidence that the system is secure. Without the synthesizer, you lose an important window into which patterns the software is learning from your data, and how it's creating synthetic data from those patterns.

It's worth noting that some software vendors don't produce a synthesizer because it's part of their business model – they'd prefer to store the synthesizer themselves and charge you to create synthetic data from it. But this setup could easily hide privacy violations that would be more obvious if the synthesizer were exposed.
Warning sign #2: Your synthesizer contains original data, not just patterns
Assuming you do have access to the synthesizer artifact, it's worth inspecting it to see what it contains. A synthesizer is supposed to contain statistical patterns that were present in the original dataset. However, if it also contains the original training data itself, that's a major privacy concern. First, it means the synthesizer object is a sensitive artifact that you must treat with the same security protocols as the original data (you can forget about sharing it!). Second, it casts doubt on the software. If the synthesizer already knows the general patterns of the original data, why does it need the original data as well?
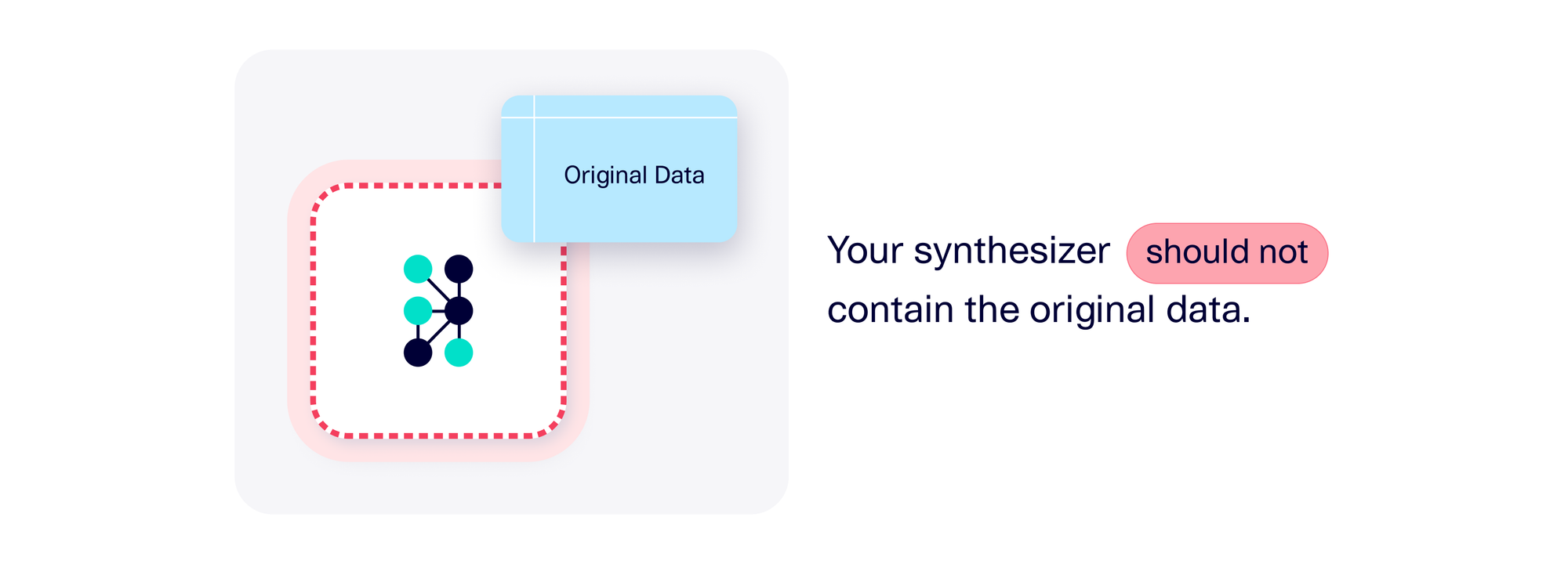
If this is happening, it may indicate that the software has failed to sufficiently learn all the patterns from the original data. During the sampling phase, the software may continue to reference the original data and extract patterns from it, blurring the definition of synthetic data and violating privacy in the process.
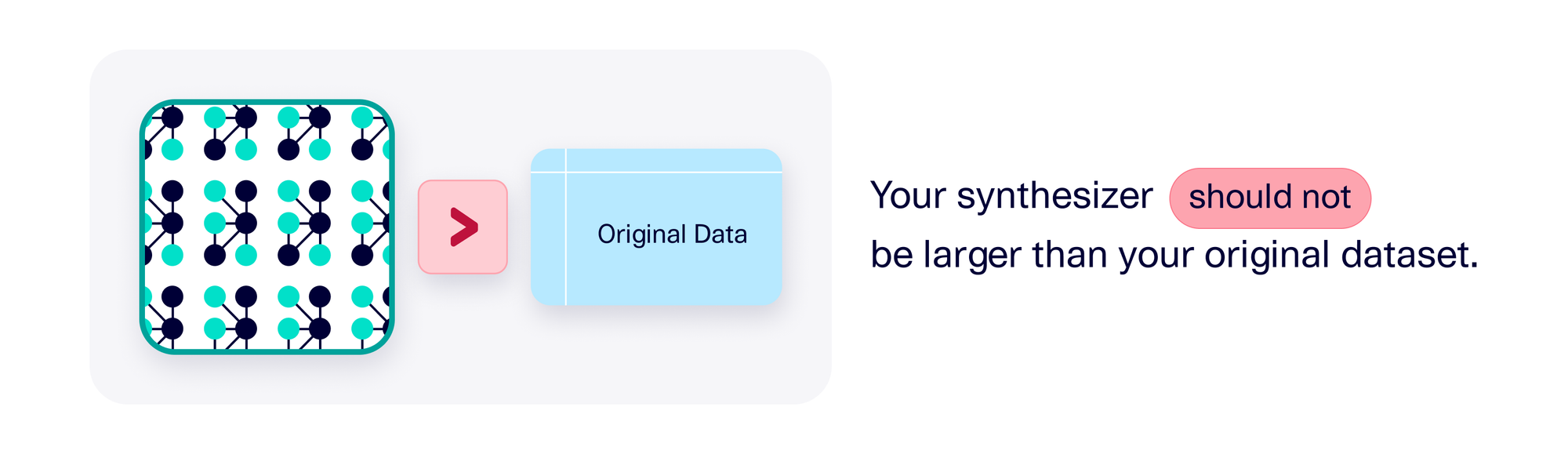
Warning sign #3: Your synthesizer object is larger than your dataset
Imagine a case where your software learns patterns from a 2.5 MB dataset … but the synthesizer object itself ends up even larger than that, sitting at 5 MB on your machine. This could happen because the dataset is saved inside the synthesizer as-is (warning sign #2). But it could also be because the synthesizer is learning too many parameters, and/or encoding the full dataset in a different format that you can't recognize, but that the AI can.
Because you can't easily access the original data using the garbled, AI-readable parameters saved in the synthesizer, the privacy violations may not seem as severe. But some damage has already been done: The original data may still exist somewhere in the synthesizer – in bits and pieces – which could lead to overfitting and poor privacy in the synthetic data.
The exception to this is if your dataset is very small, on the order of 20 rows. In this case, a synthesizer that learns 100 patterns may already be larger than your dataset. We recommend training on larger datasets, or using specialized solutions for small data, such as SDV's BootstrapSynthesizer.
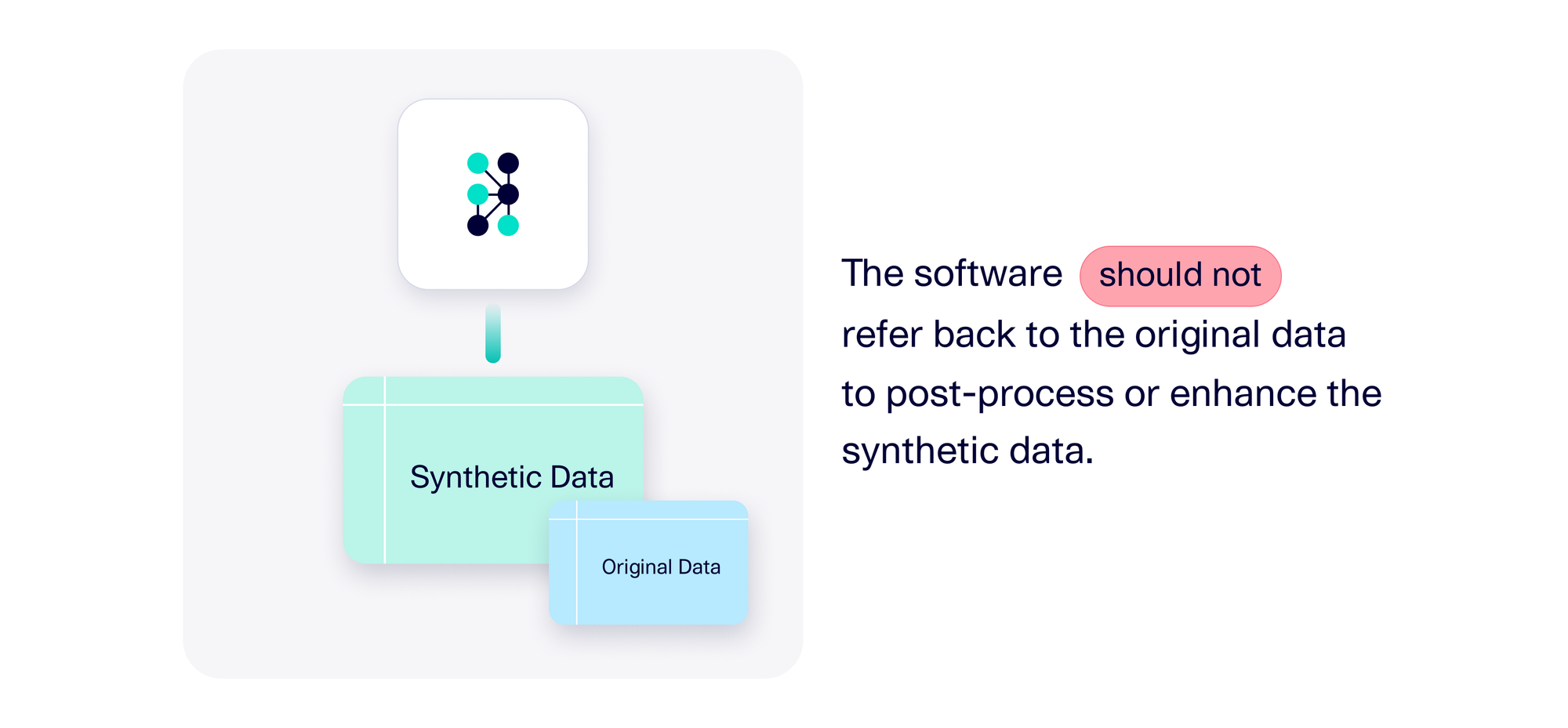
Warning sign #4: The software is post-processing the synthetic data using the original data
In this scenario, the synthesizer itself has no noticeable issues. However, before giving you synthetic data, the software performs additional post-processing on the data that the synthesizer generates – and this post-processing refers back to the original data. Now, the synthesizer is no longer sufficient for creating synthetic data, because the post-processing step uses the original data. This prevents you from sharing your synthesizer as a complete solution for creating synthetic data.
Chances are that even the synthetic data may not be private. While post-processing may be an earnest effort to improve the synthetic data in some way, even well-meaning attempts can have an impact on privacy. For example, we've seen a post-processing step that attempted to improve privacy by deleting any generated data points that were too similar to the original data. But this left the project vulnerable to a different type of privacy attack, an attack by omission: If certain values of the synthetic data were always deleted, you could conclude that the original data included those values.
Warning sign #5: You can only create a limited amount of synthetic data
If your synthesizer artifact is only capable of producing a limited amount of synthetic data, that can be a red flag. For example, imagine a scenario where, a synthesizer ingests all the original data, adds some noise, and saves it as "synthetic data." Such a synthesizer would appear to be effective while actually bypassing the crucial pattern-learning step. For all you know, it could be feeding you "synthetic data" that is based exactly on examples of the real data.

You'll ultimately feel the consequences of this because you'll be stuck using a limited amount of data – prevented from scaling or upsampling.
Warning sign #6: You can't sample 1 synthetic data point at a time
On the opposite end of the spectrum, your synthesizer shouldn't be forcing you to sample a minimum size of data either – such as a minimum of 500 data points at a time. It should allow you to sample 1 data point at a time if you request it.
Minimum requirements like this impede usage, and they can also indicate privacy violations. For example, imagine a synthesizer that forces you to sample 500 data points at once because it is internally referring back to the original data to shuffle, or otherwise transform the data. (This goes hand-in-hand with warning sign #4, post-processing the synthetic data.)

Warning sign #7: There's a real analogue for every synthetic data point
This final warning sign is about what the synthetic data ultimately represents. Every synthetic data point is supposed to represent a brand new entity that isn't necessarily representative of any one, original entity. For example, if the original data represents your customers, then the synthetic data should represent a brand new set of never-before-seen customers. If you notice that each synthetic data point has a real-life analogue, that's a problem.

For example, if each synthetic customer actually maps to an original customer (that acted as its original source), that's a problem. In this scenario, your synthesizer isn't really creating synthetic data, it's merely anonymizing your original data points. Your "synthesizer" is actually just a transformer, and the "synthetic data" is actually just an anonymized version of the same data. Be careful with this: Anonymized data is typically not considered as safe as synthetic data, because it is ultimately based on a single, original analogue.
The Bottom Line
When considering a synthetic data vendor, it's worth evaluating how their software works. Even though you may not know the entire details of the software, the ability to access and assess the synthesizer artifact can provide invaluable clues. It provides transparency into some of the inner workings of the synthetic data software, and allows you to perform independent evaluations for privacy.
Looking to create synthetic data? Check out the Synthetic Data Vault (SDV) software. SDV has a publicly-available version that offers many types of synthesizers. When using SDV, you have full access to all the synthesizer objects and can create unlimited synthetic data.


