
Today we are announcing a Differential Privacy bundle that allows you to create private synthetic data using AI. Our goal is to give you the confidence to freely use and share synthetic data when privacy is of the utmost importance.
This blog post is Part 1 of a 2-part series exploring differential privacy. In this article, we'll define differential privacy and how it applies to creating synthetic data. We'll explain why the concept of a synthesizer fundamentally changes the data disclosure paradigm, and provide some of our requirements for setting it up.
Differential privacy was originally defined for data disclosure
At its core, differential privacy is a framework that was created for data disclosure, which happens when data is shared between two parties. To better understand data disclosure, it's helpful to define the key players:
- A data controller is a trusted person who has access to the unaltered, real data. They have the authority to disclose this data to other parties or systems; in doing so, they must consider the overall sensitivity of the data, privacy needs, and security.
- A data receiver is anyone (or anything) consuming the data provided by the data controller. The receiver could be a software that ingests data to perform calculations, or a human who is completing a task such as data analysis.
In a typical data disclosure setup, the data receiver queries the data controller for some information. The data controller then answers the query by disclosing some data. Within the differential privacy framework, the data controller only discloses data in a way that protects the privacy of every record. Put another way: The data receiver should not be able to back-calculate anything about an original record.
For example, imagine that the real dataset records students' grades on a final exam. The data receiver may query the data controller for some information – say "what is the average grade?" Within the differential privacy framework, the data controller must provide this information in such a way that the data receiver cannot learn anything about individual records.
This can be more complicated than it seems. For instance, imagine an extreme scenario in which the data receiver already has access to every student's grade except for one. If they then ask for the average grade, they can back-calculate the missing student's grade. Under the differential privacy framework, this is a violation of privacy.
Differential privacy offers mechanisms for a data controller to disclose data in a way that does not violate privacy. This is done by providing an approximate answer rather than the actual answer. (The approximation formula is determined by mathematically rigorous proofs that are described in research papers.) Going back to our example, a data controller may answer the query for the average grade by removing outliers and adding noise to the final answer. This way, even if the data receiver did have most students' grade information, they wouldn't be able to accurately back-calculate the missing student's grade.
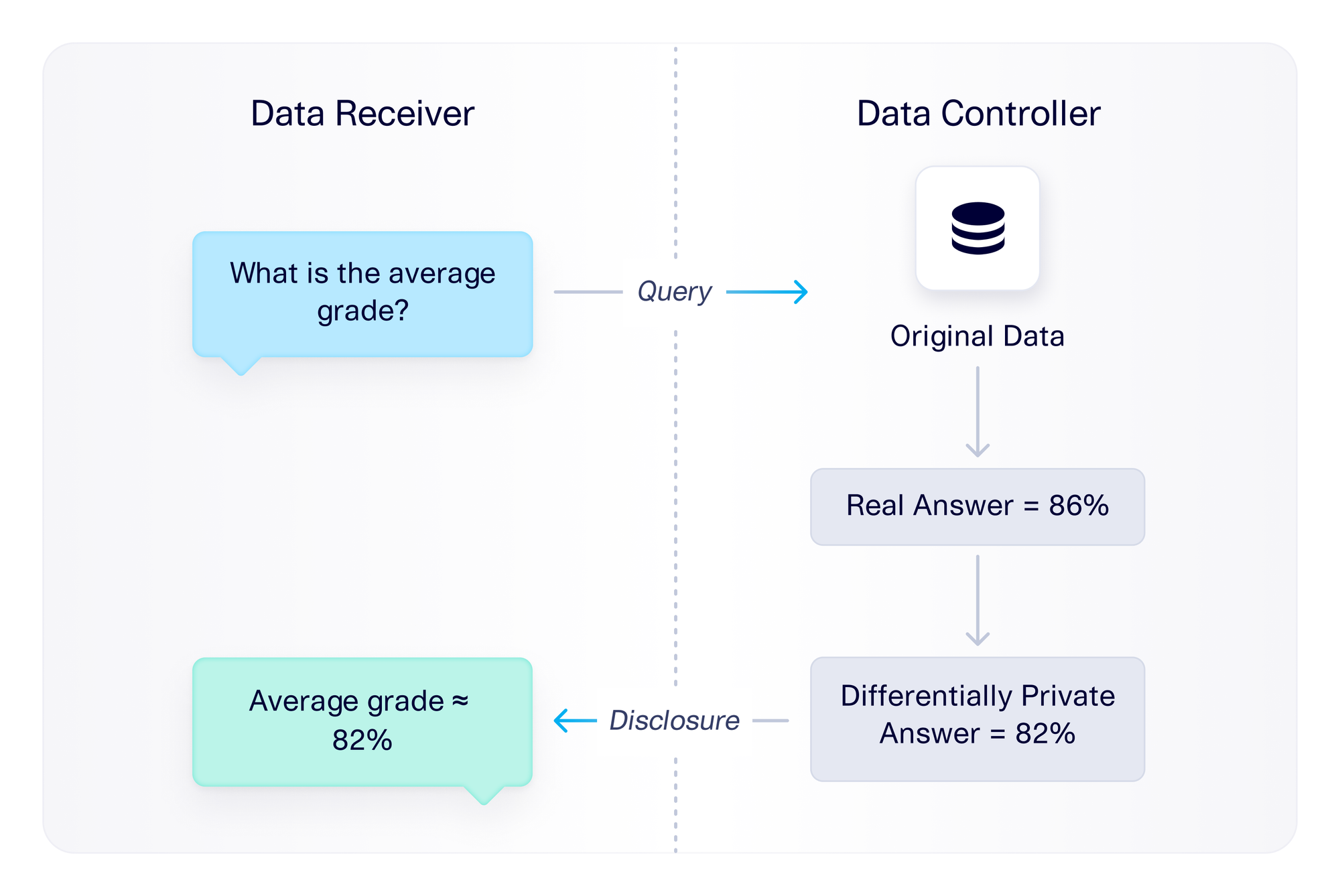
Differential privacy is particularly useful when the exact value of the data is not critical for the data receiver. For example, if the data receiver is an external web developer who is using the data for testing, is it not critical to know what the actual answer to a query is. An approximation will do just fine.
When it comes to differential privacy, the number of interactions between the data controller and the data receiver is an important consideration. There is a theoretical limit to the amount of queries that a data receiver can make, because with enough information, the data receiver may piece together the original data. Therefore, the data receiver must be judicious with the queries that it asks.
Synthesizers are game-changers for the data disclosure paradigm
The field of synthetic data is separate from but related to data disclosure. A synthetic dataset has the same overall properties as the real data, but represents completely new records – for example, completely new students and a set of grades for each. In many cases, it is possible for a data receiver to use synthetic data instead of real data to accomplish a task.
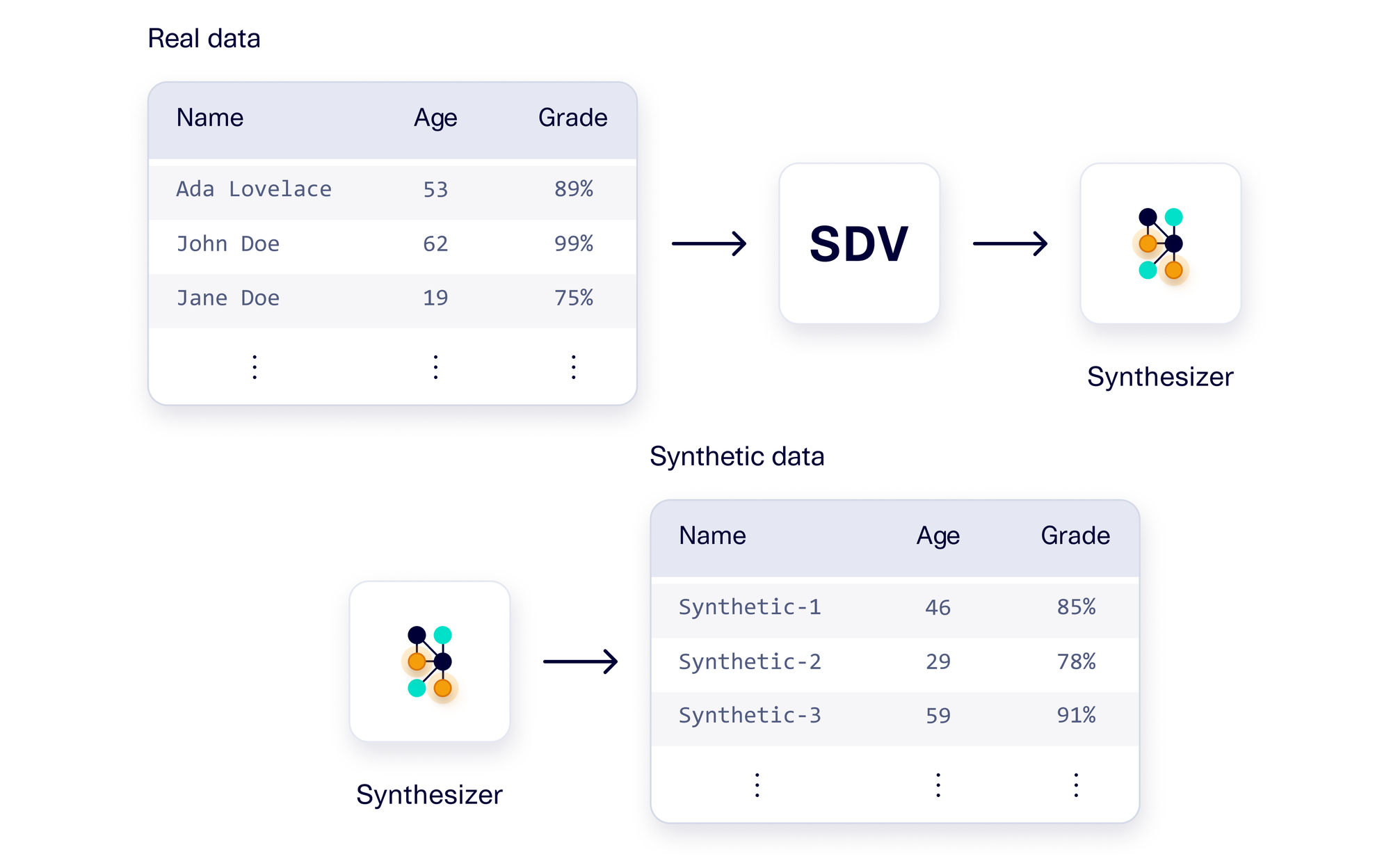
To create synthetic data, the data controller can use a generative AI software like SDV. SDV learns overall patterns from the real data, and saves the patterns inside of a synthesizer object. Then, that synthesizer can be used to create synthetic data on-demand. We can think of the synthesizer as a compressed representation of the entire database.
While synthesizers are broadly useful, they have an especially profound impact on data disclosure because they change the way that a data controller operates. A data controller can now choose to disclose a synthesizer instead of disclosing data. The data receiver can then do numerous things with this synthesizer, including generating synthetic data that is similar to the real data and answering specific questions about that data. This shifts the entire data disclosure paradigm: There is no longer a need for continuous, query-based interaction between a data controller and data receiver. Simply sharing a synthesizer will suffice.
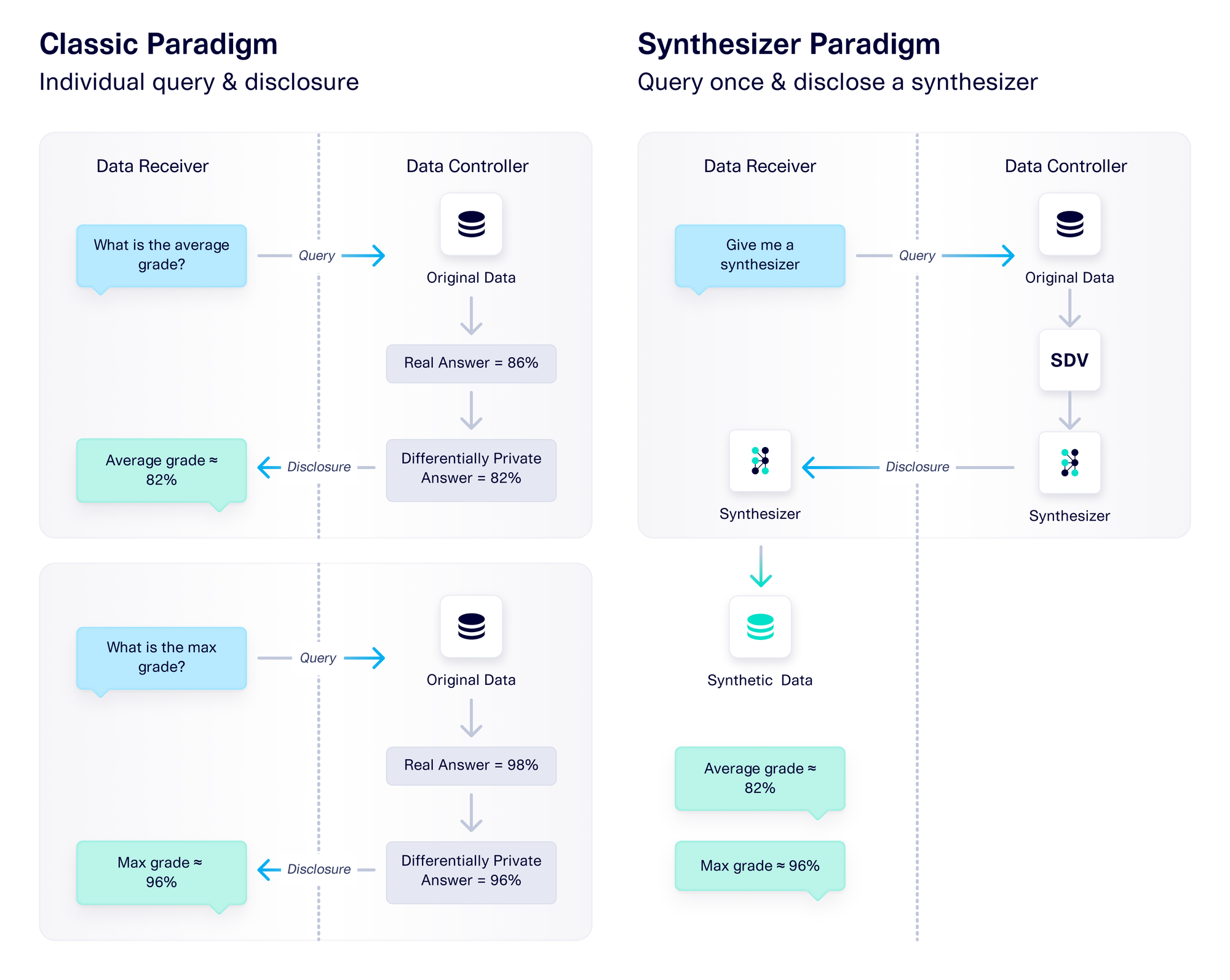
This paradigm has many practical applications, as well as many advantages over the classical paradigm:
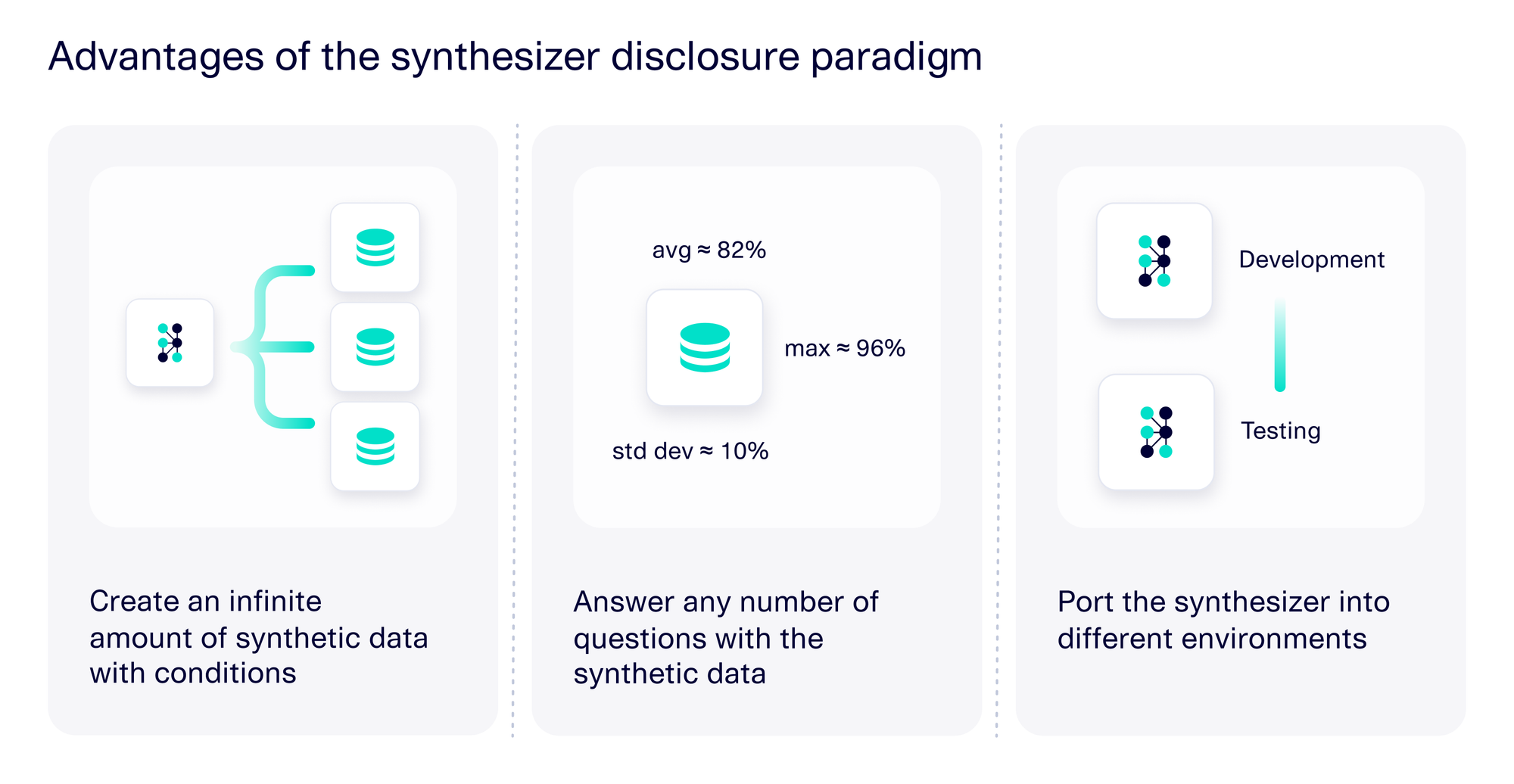
- The data receiver can answer any number of questions using the synthetic data. In the classical paradigm, the data receiver has a limited number of queries it can make to the data controller. Now, the data receiver makes only one query – to get a synthesizer. They can then get additional answers from the synthesizer itself by creating synthetic data.
- The data receiver can create an infinite amount of synthetic data (including conditional data) on demand. A generative model offers the ability to sample as much data as a user wants. This enables a broad set of use cases where a limited dataset wouldn't suffice, such as performance testing. For some use cases, such as creating training data for AI models or debiasing data, the data receiver can also provide conditions for the synthetic data. A differentially private synthesizer should be able to support this functionality, generating infinite amounts of conditional synthetic data.
- The data receiver can port the synthesizer into many environments to sample synthetic data on demand. The synthesizer is usually present as a single file. Our users find this aspect incredibly powerful because it allows the data receiver to apply synthetic data in a broad range of situations, from testing software applications to cloud migration applications.
These advantages are summarized in the diagram below.
DataCebo's requirements for a synthesizer disclosure system
Disclosing the synthesizer is the core tenet of the new paradigm. Of course, this can come with risks, as anyone with access to the synthesizer can create synthetic data and glean information. Creating a system that supports differential privacy requires careful attention.
At DataCebo, we came up with three basic requirements for a synthesizer disclosure system. The goal is to prevent accidental leakage of information between the data controller and data receiver, while still enabling the new paradigm.
1. The synthesizer should be created with differential privacy in mind.
For the new paradigm to work, it is critical that the synthesizer object itself is safe to disclose — meaning that it has to be differentially private. To achieve this, it is critical that a generative AI software (like SDV) incorporates differential privacy from the very beginning, when the synthesizer is being created. As the AI calculates each of the parameters, it should add differential privacy to each one. This process is similar to approximating the answer to a query, such as the average or max of a column.
If each parameter is differentially private, then the synthesizer as a whole becomes differentially private too. At this point, all the synthetic data it generates will be safe to share.
Thanks to the differential privacy community, many algorithms for calculating differentially private parameters have been tested and reviewed. There have been efforts to make a differentially private CTGAN as well as a differentially private copula method. We researched several methods and identified a best approach. Most methods only attempt to add differential privacy to the modeling step, but there are parameters in preprocessing that can leak privacy. To enable sharing a synthesizer, we create a differentially private approach for the end-to-end processing so the entire synthesizer is private.
2. Trust but verify the differential privacy of the synthesizer.
The field of differential privacy has made many amazing contributions, from protecting the privacy of individually-disclosed statistics (the classical data disclosure paradigm) to creating differentially private synthesizers. However, before a data controller discloses the synthesizer, we recommend being absolutely sure that the data generated by the synthesizer is private. This is especially important because once someone has access to the synthesizer, they can sample an infinite amount of synthetic data, answer arbitrary queries, and conditionally sample synthetic data.
We call this process trust but verify, and it's something that we'll cover in Part II of this blog series. For now, suffice to say that the data controller is responsible for performing this verification before deciding to share the synthesizer. Once the synthesizer has been shared, it cannot be retracted.
3. Design your process in a way that is robust against "frivolous loops"
In the new synthesizer paradigm, the data receiver can use the synthesizer to create any amount of synthetic data, and to answer any questions about that data. Because the synthesizer itself is such a powerful tool, it is important to have guardrails around any other interactions that the data receiver and controller may have.
Many times, we find that these additional queries form "frivolous loops" that (a) are not necessary for usage, and (b) can accidentally leak more information if they are answered. Researchers have sometimes used frivolous loops to prove a point, but they are not reflective of how a product is meant to be used. For example, one such loop would happen if, after receiving the synthesizer, the data receiver goes back to ask the data controller for additional information about the privacy of the data. This is a frivolous loop because the data controller should have already verified the privacy of the synthetic data; the data receiver's job is to use the synthetic data, not to go back and verify its privacy. More importantly, if the data controller actually answers this query, the data receiver may be able to back-calculate some of the details about the original data.
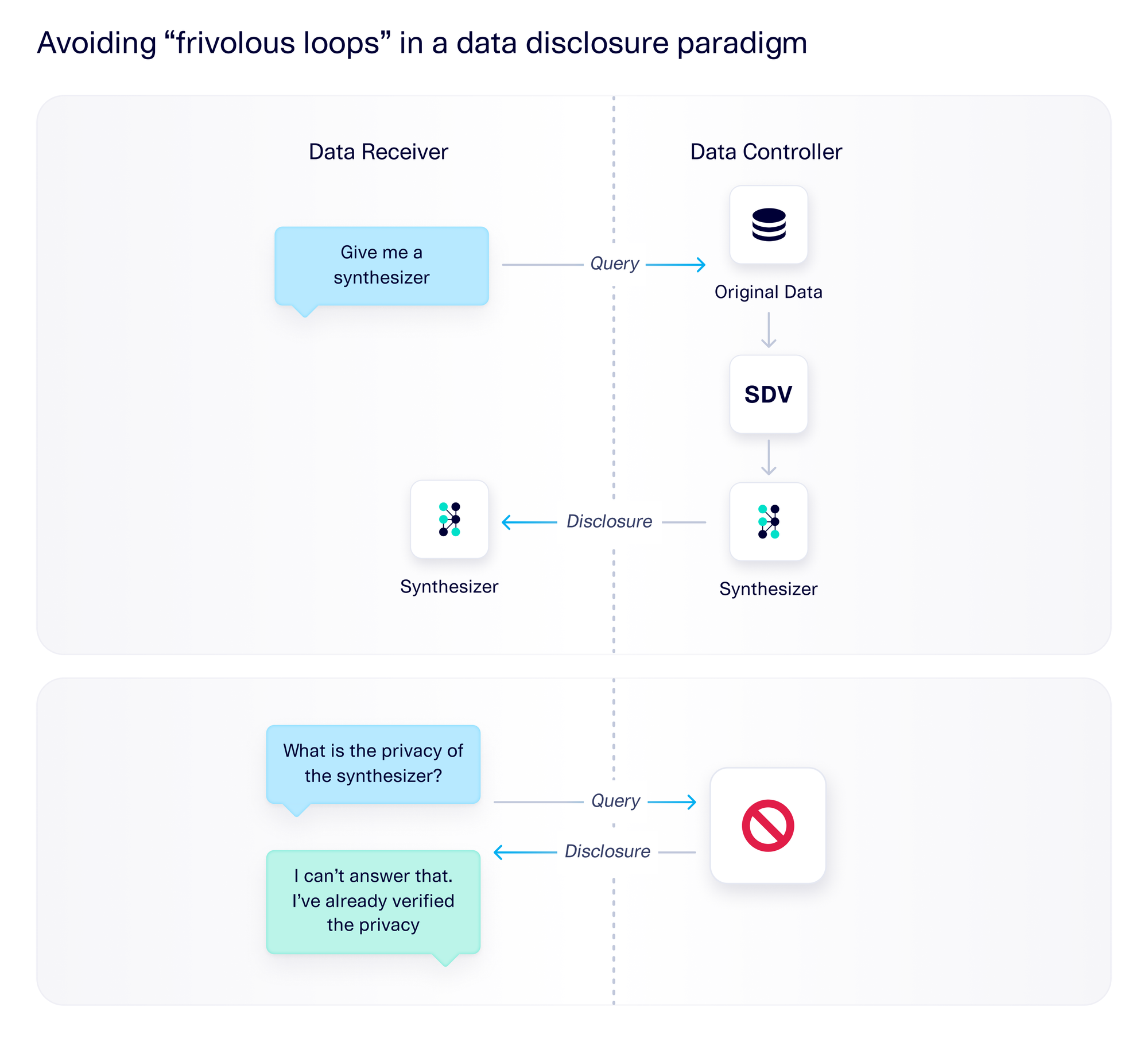
One way to avoid frivolous loops is to provide guidance to the data controller. For example, the data controller can be instructed not to answer any more questions about the data or data privacy after disclosing the synthesizer. Another way is to design the system in a way that removes the need for these loops. For example, if the synthesizer already comes with a privacy guarantee, the data receiver need not ask for one.
This way, it's possible to use the new synthesizer paradigm without leaking information between the data controller and data receiver.
Takeaways
In this article, we explored the concept of data disclosure and how it relates to differential privacy. We've seen how the concept of a generative AI synthesizer can fundamentally shift the paradigm of data disclosure, turning it from a query-based system into a single disclosure of a synthesizer.
A synthesizer is an extremely powerful tool, so it's important to create it with differential privacy in mind and to protect against "frivolous loops" that may unintentionally leak data. In the next article of this series, we'll explore what it means to verify that the synthesizer has differential privacy and go through some of our verification results for SDV synthesizers.



