
Last month, DataCebo announced a Differential Privacy solution that allows you to create private synthetic data. Our goal is to give you the confidence to freely use and share synthetic data when privacy is of the utmost importance.
To accompany this launch, we published the first article in a 2-part series that explains how differential privacy can be incorporated into AI-generated synthetic data. If you're new to this topic, we recommend starting there. In this article — the second part of the series — we'll explain how to verify differential privacy, and walk you through that process using our product the Synthetic Data Vault (SDV), the top platform for synthetic data.
You can trust an AI software to be private, but you should be able to verify it too
To recap: In Part 1 of our series, we explained how a data controller can use an AI software like SDV to create a differentially private synthesizer object by applying differential privacy techniques to it. A synthesizer trained in this way should be safe to disclose to others – it won't contain any sensitive information. This is a game-changer, because anyone with access to the synthesizer can use it to create infinite amounts of synthetic data and answer any number of questions.
With SDV, you can use the DPGC Synthesizer – which stands for Differentially Private Gaussian Copula – to achieve this. As its name indicates, this synthesizer applies differential privacy techniques when training a Gaussian Copula-based model. (For more information, refer to this research paper.) We also added differential privacy techniques to the data pre-processing steps, making the overall synthesizer safe to disclose. Other software (outside of SDV) may offer similar features under different names.
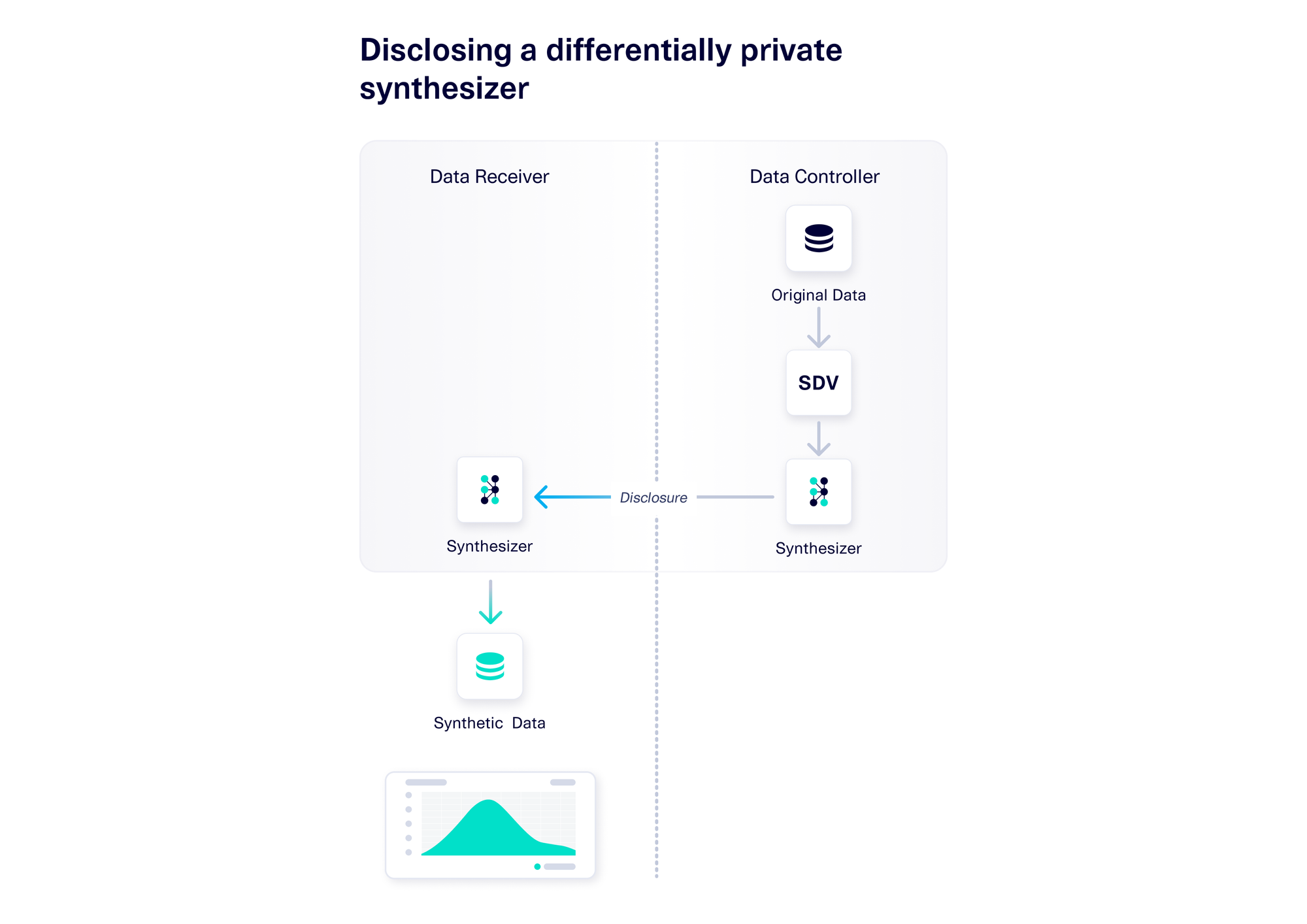
For this process to work, it is critical for the data controller to fully trust that the software is actually differentially private. The most definitive way to do this is for that data controller to be able to verify this for themselves. This forms the basis of our trust-but-verify framework. This framework allows data controllers to verify privacy themselves fully and efficiently — without going all the way back to the mathematically dense research papers the concept is based on, or blindly trusting how an AI software has implemented the concept.
We designed the trust-but-verify framework to be flexible, operating on three key principles:
- The data controller should be able to run the framework with what they have. The data controller has access to the AI software and the real data used for training. The framework requires only those two inputs, so that the data controller can verify differential privacy themselves before disclosing the synthesizer to others.
- The framework should work with any AI software – even if the data controller doesn't know how it works. Different AI softwares can vary vastly in terms of their algorithms and complexity levels. Our framework is AI software-agnostic, which means it operates the same regardless of the software specifics.
- The framework should give the data controller a score – not a decision. Ultimately, it is up to the data controller to decide whether it's safe to disclose their synthesizer to others. Ideally, the data controller will combine the framework's score with other evaluations before making a determination.
The trust-but-verify framework empirically verifies differential privacy for trusted mathematical techniques
Our trust-but-verify framework is based on the theory of differential privacy. A differentially private synthesizer must not compromise the privacy of any individual data point of the real data. When training a synthesizer with differential privacy techniques, the goal is to make sure that any single data point does not have a large influence on the parameters of the synthesizer — or, to put it another way, that the absence of any one data point does not significantly affect the contents of the synthesizer (a.k.a. the parameters it is learning from the data).
Suitable techniques range from adding noise to the learned parameters (for probabilistic generative models) to adding noise to the gradients during the training process (for neural network-based generative models). In the abstract, all these techniques have been mathematically proven to achieve the goal of differential privacy. However, is it possible to verify that their specific synthesizer achieves this goal?
Our framework verifies this empirically:
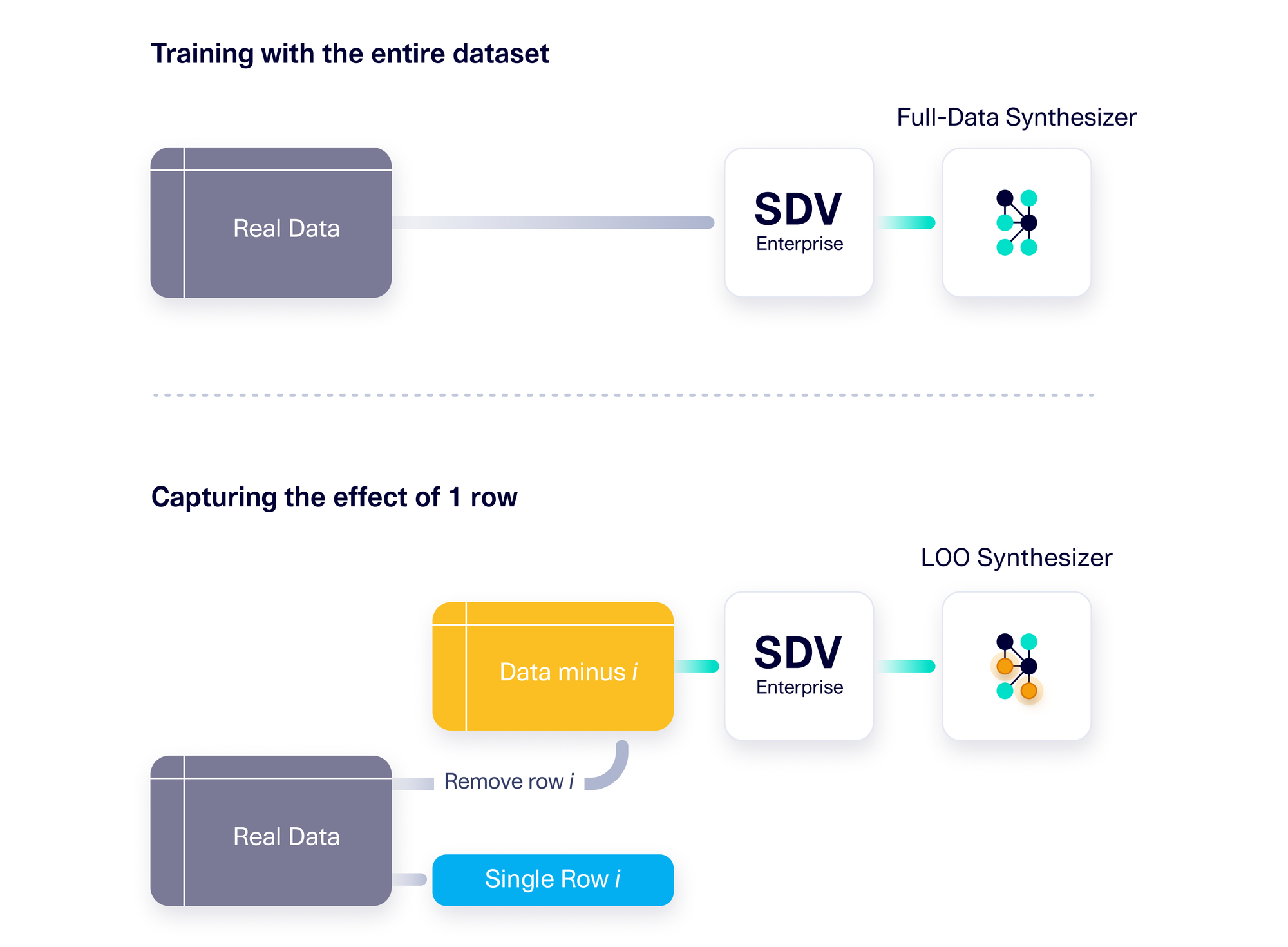
- It trains a synthesizer using the full set of real data points. Let's call this the full-data synthesizer.
- Then, it trains a number of additional synthesizers, each time leaving one row out . Let's call these the LOO synthesizers, for "Leave One Out."
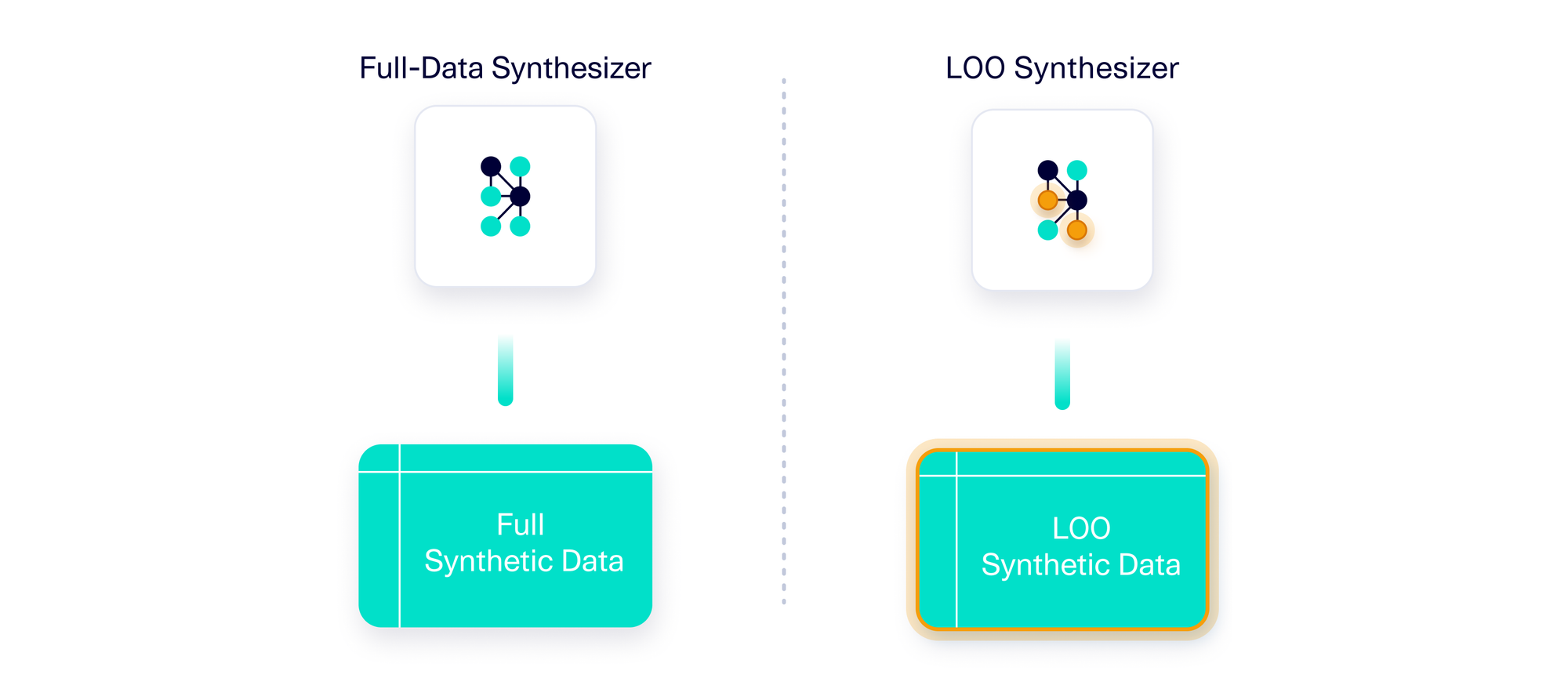
- Next, it assesses the difference between the full-data synthesizer and each of the LOO synthesizers, and identifies the LOO synthesizer that maximally differs from the full-data synthesizer.
- The difference between the full-data synthesizer and the most different LOO synthesizer is then converted into a similarity score between 0 and 1. If the synthesizers are similar, it indicates that differential privacy has been achieved.
Of course, assessing the difference between two synthesizers can be tricky. The parameters saved inside a synthesizer may not be deterministic or easily interpretable. So the framework creates synthetic data from the synthesizers, and uses it as a proxy for the synthesizers themselves. It can then compare the synthetic datasets using any number of tried-and-tested metrics. (Today, our framework uses the SDMetrics Quality Report to test for statistical differences, but this can easily be updated to any other metric.)
The resulting trust-but-verify framework can be applied to any AI software that is designed to create a synthetic data generator (synthesizer) and dataset. The framework ultimately produces a score between 0 and 1, where 1.0 is the best possible score, indicating that the software offers the best possible differential privacy protection – i.e. that omitting a single row of data has no impact on the synthesizer it produces.
Additional optimizations for the trust-but-verify framework
As described above, our framework is designed to repeat this process for all data points in the real dataset, leaving out one row at a time and calculating the difference between each LOO synthesizer and the full-data synthesizer. Training a synthesizer is a time-consuming process, so if there are n rows of data, this framework would need to train n+1 synthesizers (LOOs for each of the rows, and one for the full data).
Our first optimization reduces this computational burden by picking a subset of data points to test. For this subset, our framework chooses points that are outliers, which will more drastically impact the synthesizer if differential privacy techniques are not working.
To compare the synthesizers, the framework makes them sample a very large amount of synthetic data – 1 million data points, to be exact. Usually, synthesizers introduce randomness during the sampling process, so sampling a larger number of rows stabilizes the overall patterns in the synthetic data.
The trust-but-verify framework validates SDV's software
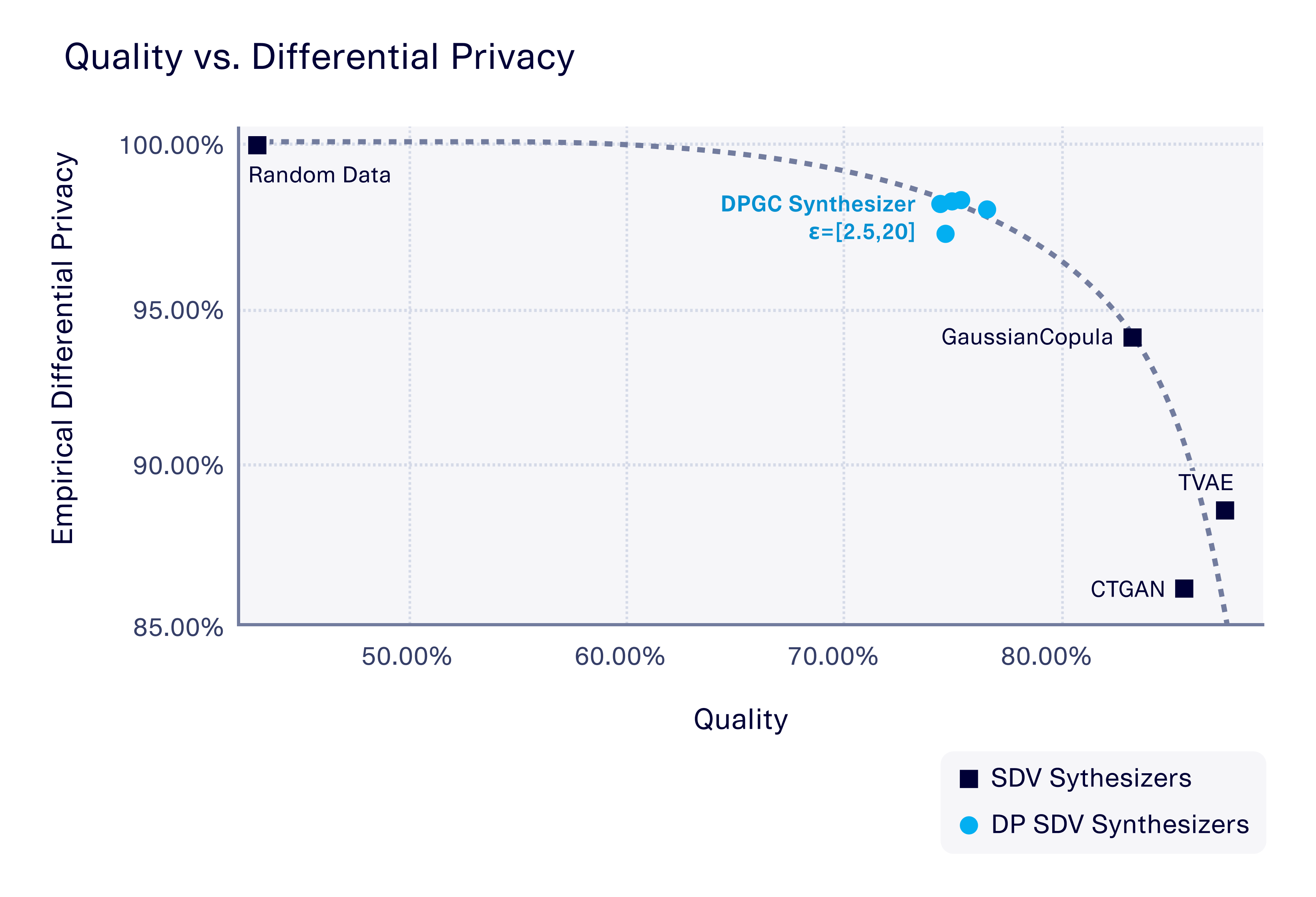
Our trust-but-verify framework is AI software-agnostic, meaning that it can be applied to any kind of AI training algorithm – not just those that advertise differential privacy. We used this framework on one of SDV's demo datasets ("adult" dataset) to verify several of the AI algorithms that SDV offers. These ranged from classical statistical algorithms like GaussianCopula, to neural network-based models such as TVAE and CTGAN, to a baseline random data generator. We compared these to the new, DPGC algorithm that is part of our differential privacy offering. (The DPGC algorithm allows you to control the amount of differential privacy using a parameter, ε, that we also varied, starting from 2.5 – the lowest, most private value we could test with this dataset – up to 20.)
The interesting part comes when we compare the differential privacy of the software with the quality of the synthetic data it produces (as measured by the SDMetrics Quality report). The graph below summarizes our results.
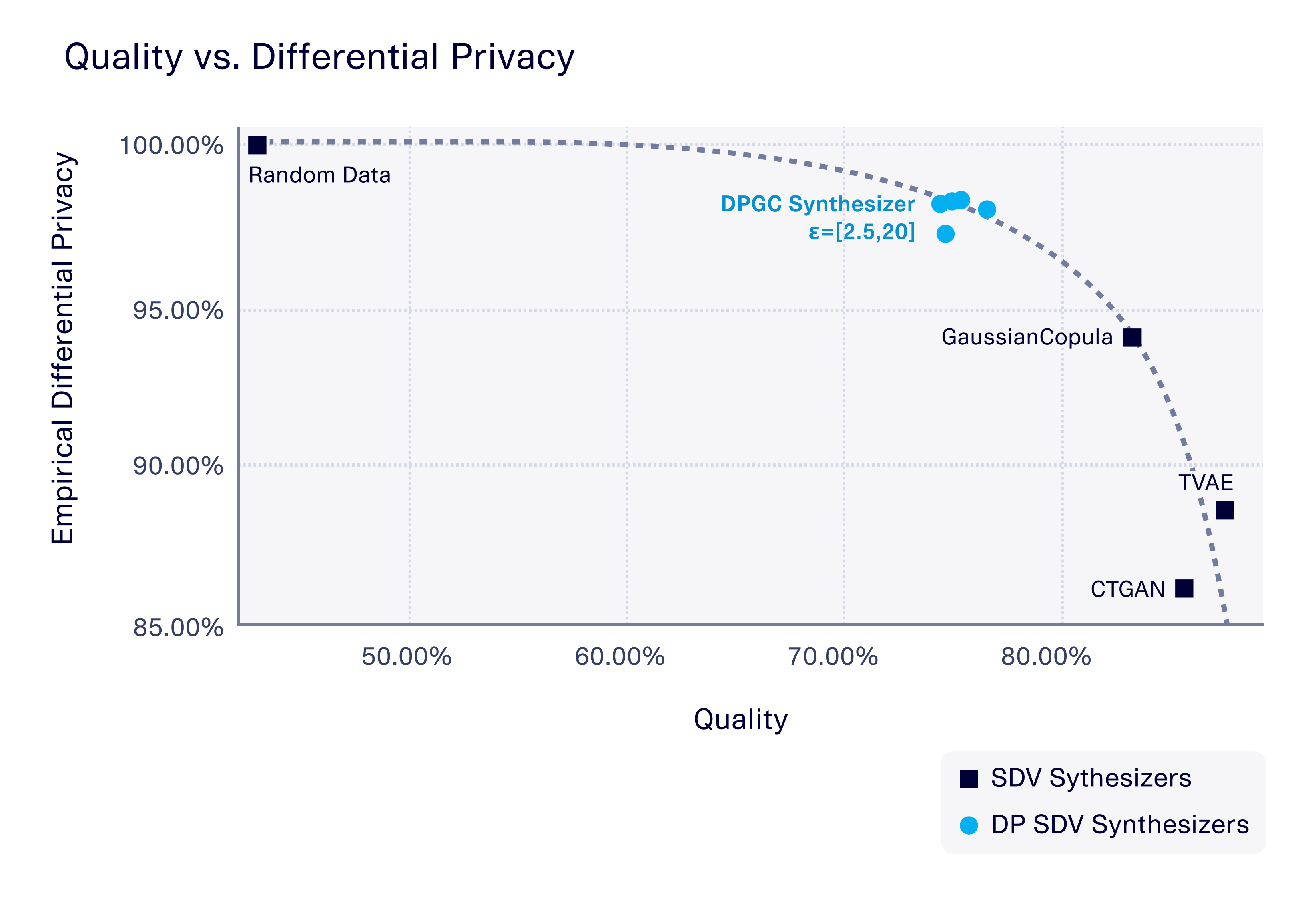
Our results clearly verify that the DPGC algorithm does indeed offer stronger differential privacy than the other synthesizers – even when we vary the ε parameter that controls the amount of differential privacy. However, the results also highlight that there is a tradeoff between the differential privacy and the quality of the synthetic data. All the other algorithms – GaussianCopula, TVAE, and CTGAN – achieved a higher quality.
The random data comparison produces results on the other extreme. This type of data generation does not depend on any individual data point, so it has the highest differential privacy of all (100%). However, its quality is lower than 50%. The result is a curve that shows the frontier of the privacy/quality tradeoff. At DataCebo, we're always trying to push this frontier through new AI algorithm innovations and features.
Apply the framework to be SDV Verified
We recommend that all data controllers use the trust-but-verify framework to measure the differential privacy of their synthesizer – especially if they plan to share it.
If you're using the DPGC algorithm, the framework is accessible directly from your synthesizer.
privacy_score = my_dpgc_synthesizer.verify_differential_privacy(
data=my_dataframe,
num_rows_test=10,
)When you run this evaluation, your synthesizer object automatically saves the fact that it has been SDV verified – which can be important down the line for audits.
my_dpgc_synthesizer.is_verified(){
'differential_privacy_verified': True
}If you're using any other kind of SDV algorithm, you can access and use the verification function too — you'll just need to supply a bit more information, including the metadata, the name of the algorithm (synthesizer_name), and the parameters that the algorithm is set to run with (synthesizer_parameters).
from sdv.evaluation.single_table import measure_differential_privacy
privacy_score = measure_differential_privacy(
data=my_dataframe,
metadata=my_metadata,
synthesizer_name='GaussianCopulaSynthesizer',
synthesizer_parameters={ 'default_distribution': 'norm' },
)As a data controller, our hope is that you can use the trust-but-verify framework to assess your synthesizer and confidently share it with others in your organization.
Ready to get started with synthetic data? Synthetic Data Vault (SDV) is the top platform for creating synthetic data. It is owned and maintained by DataCebo, and has been used by over 70 of the top Fortune 500 companies. Get started in your journey by using SDV Community. For enterprise-grade tools, contact us today.


