This case study was written by Wim Blommaert, Head of Test Data Management at ING Belgium, and Neha Patki, Co-founder and Head of Product at DataCebo.
ING Belgium is using SDV Enterprise to adopt synthetic data into its software development practices. In this case study, we'll focus on how ING realized productivity gains for a payment service called SEPA. The measurable ROI shows that incorporating synthetic data from SDV Enterprise allowed for 100x the test coverage in 1/10th the amount of time, leading to a safer and more robust payment processing experience for millions of ING customers.
What is SEPA?: The cashless EU standard
In 2008, the European Central Bank introduced SEPA as a new standard for making cashless payments. SEPA, which stands for Single Euro Payments Area, is a structure that simplifies payment transfers made in euros. Banks implement SEPA by ensuring that they can ingest, process and export payments that follow the structure. A partial example is shown below.
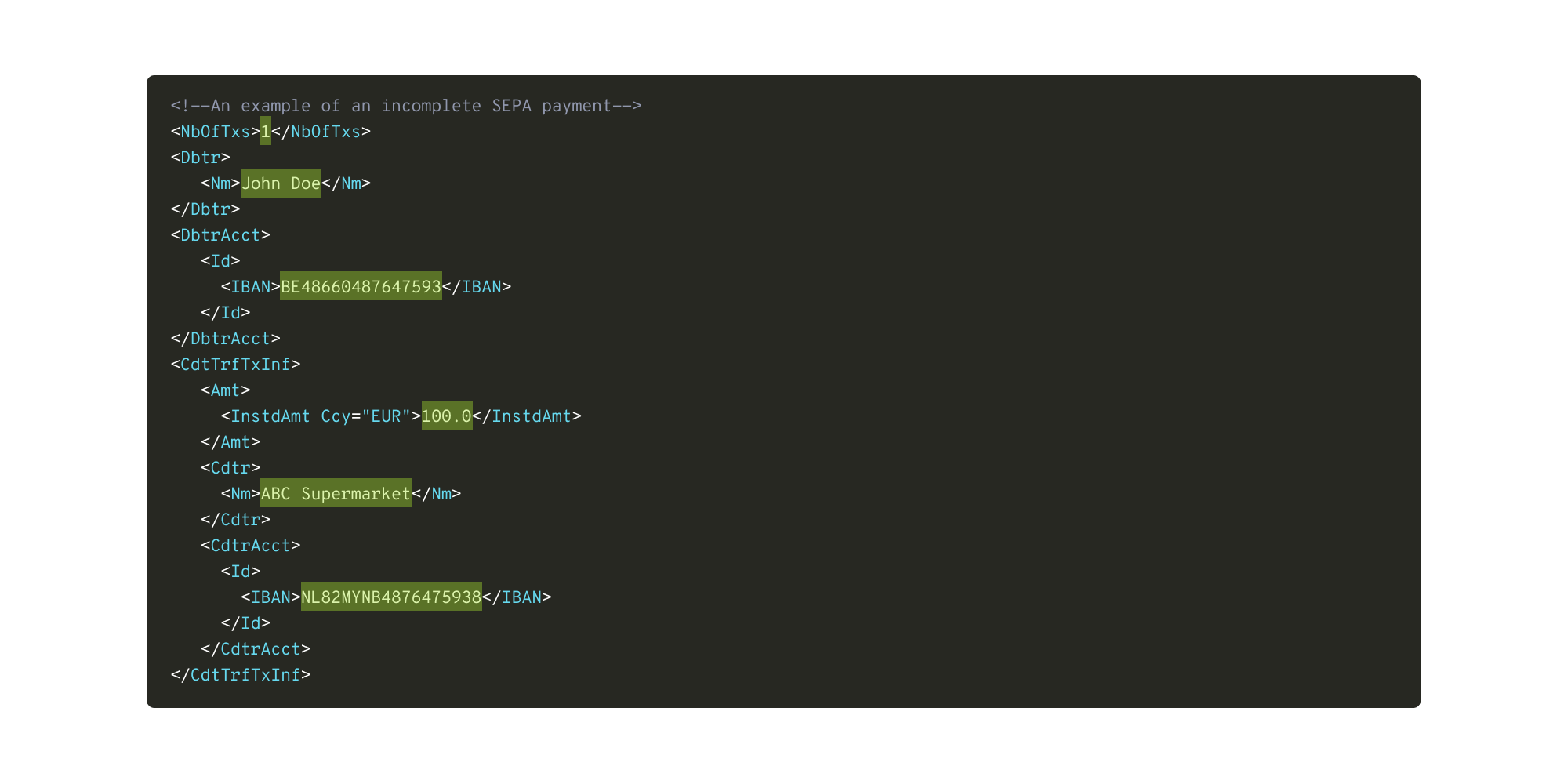
The structure includes a variety of elements, such as debtor and creditor information and payment amounts. Pre-determined XML tags are shown in blue. Each represents a concept in a credit transfer; for example, IBAN refers to the International Bank Account Number and InstdAmt refers to the transfer amount. Meanwhile the data, highlighted in green, changes based on each payment. In our example, the green values indicate that John Doe used their credit card to pay 100 euros to ABC Supermarket.
For a multinational bank such as ING, being able to send and receive SEPA payments is table stakes, and testing this functionality becomes critical to the success of millions of payments.
Testing Requirements
Testing SEPA allows ING to be confident that they can process payments without issue. Because SEPA is such a foundational component of banking, it is subject to frequent modifications and requires comprehensive test coverage. The more the application changes, the more frequently the ING team needs to perform thorough testing.
Significant Changes to SEPA
Within the past year, the SEPA application has already seen many significant changes that motivated the project.
In some cases, governmental authorities have added legal stipulations around who is allowed to use SEPA. In response, ING has updated the internal logic of their payment processing to ensure compliance. A recent example of this was when the EU enacted sanctions in Feb 2022, which meant that banks must exclude a set of accounts from receiving payments.
In other cases, the SEPA specification itself has changed. For example, in October 2022, the European Payments Council approved a change that required supplying address information using more precise components. This meant that banks must be prepared to process different types of formats in the XML.

SEPA Requires High Coverage of Key Usages.
Because SEPA is a complex application with many moving pieces, the ING team needs test payments that cover a wide variety of scenarios. For this case study, they were particularly interested in testing an assortment of:
- Payment amounts. A small payment transfer from an established account is much less risky for a bank — and therefore much easier to approve — than a larger sum from an untrusted source.
- Accounts (i.e. the sender and receiver). Based on legal requirements, accounts with specific backgrounds may be denied payment service.
- Payment types. These may affect the guaranteed transaction time; for example, an instant credit transfer is supposed to take less than 10 seconds.
These requirements highlight the complexity of SEPA, and the need to create a variety of diverse payments and accounts to thoroughly test the logic. For the ING team, this complexity is compounded by an additional challenge: the sensitivity of SEPA data.
Testing Challenges
Most of the information in a SEPA payment is considered sensitive, and many of the tags contain PII. Banks are bound by regulations that limit access to this type of data. An example of this is GDPR, a set of regulations made in 2016 that limit how a company like ING is allowed to use private data. Even outside the context of legal regulations, it's important for banks to enact good data practices to maintain high user trust. These data privacy practices are specially enforced internally: An employee should not be able to accidentally send or receive actual payments!
A best practice is to use software environments, or data silos, to keep the sensitive data contained. ING uses 4 separate environments: Development, Testing, Acceptance and Production – a setup commonly referred to as DTAP. An overview of DTAP is shown below.
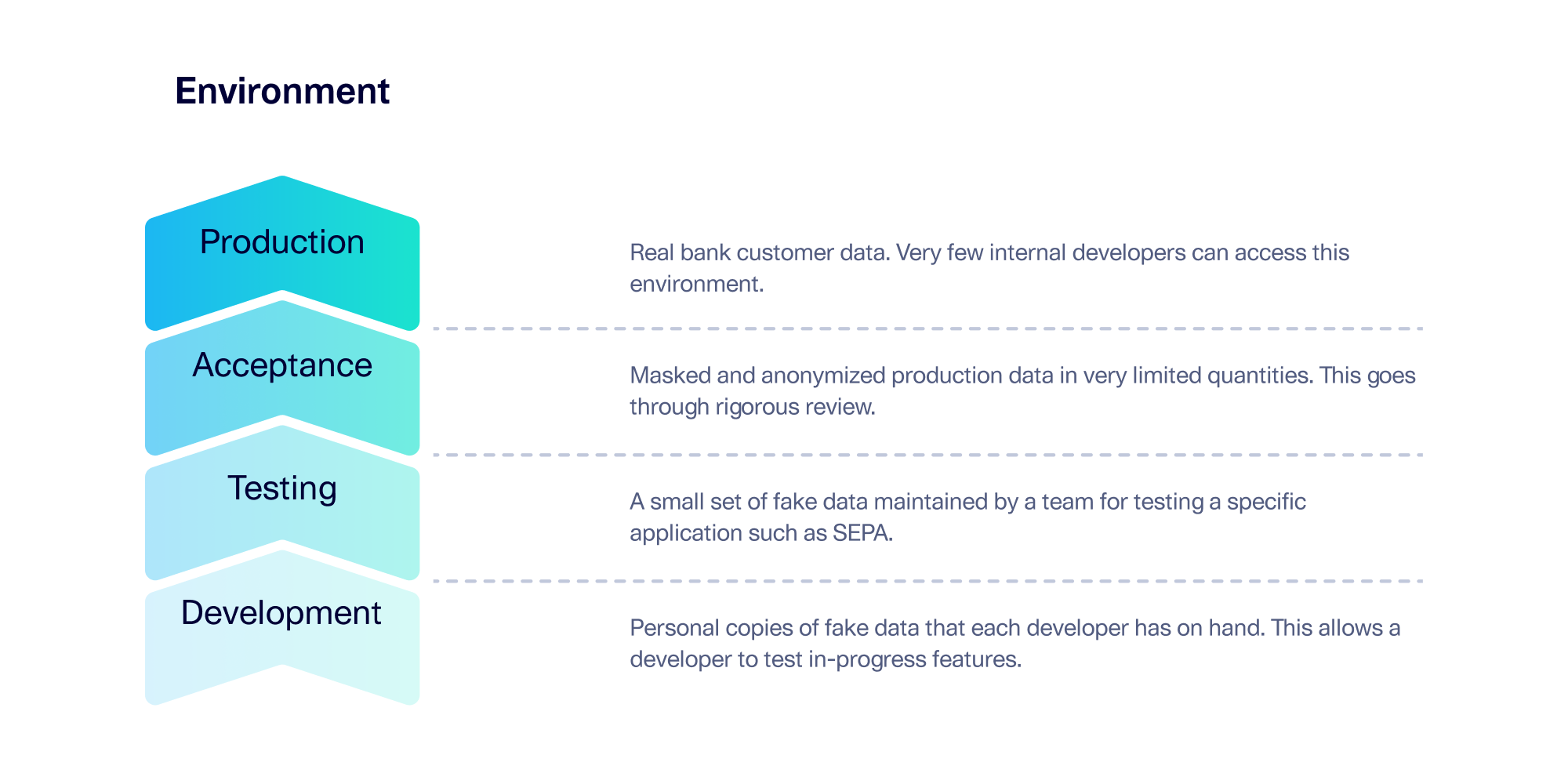
In this case study, the main challenge facing the ING team was that SEPA payment data is only available in the production environment — but it's needed in lower environments. Access to production data is limited to a subset of developers, but the larger team needed to be able to use SEPA data in the testing and development environments as well.
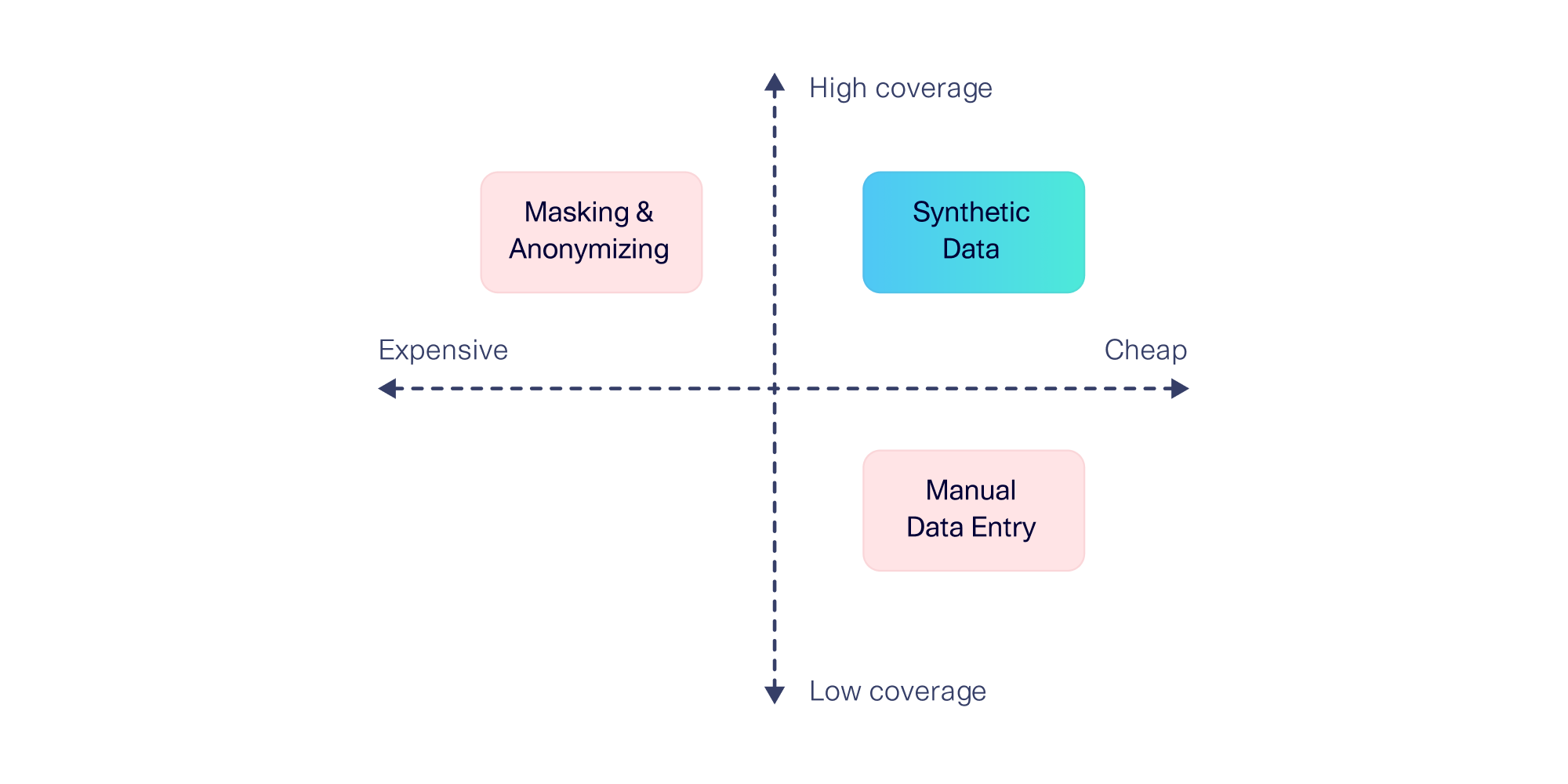
The team had two possible solutions to this problem, but neither was sufficient:
- Data masking and anonymization. For the highest possible coverage, the team considered applying the necessary masking, anonymization, and de-identification procedures before moving the data out of production. But there were drawbacks. First, the rigorous privacy review would have been costly for developers, especially because the team would need to do it every time the SEPA application changed. Secondly this practice is only suitable for the acceptance environment, and is not sufficiently private to bring down to the testing and development environments, where it matters the most. The team opted against this approach.
- (Status quo) Manual data entry. To save costs, the team had been manually creating SEPA payments by typing up XML messages. This required a complex application, with XML that took up almost three pages and required some knowledge of the different payments. It was only feasible to create a few payments, inevitably leading to lower coverage. This was still better than nothing, so it had been the team's approach.
ING realized that a solution with generative AI would fix these challenges. SDV Enterprise would allow them to create SEPA payments in a smarter way for use in the lower environments.
SDV Enterprise Creates Synthetic SEPA Payments On-Demand
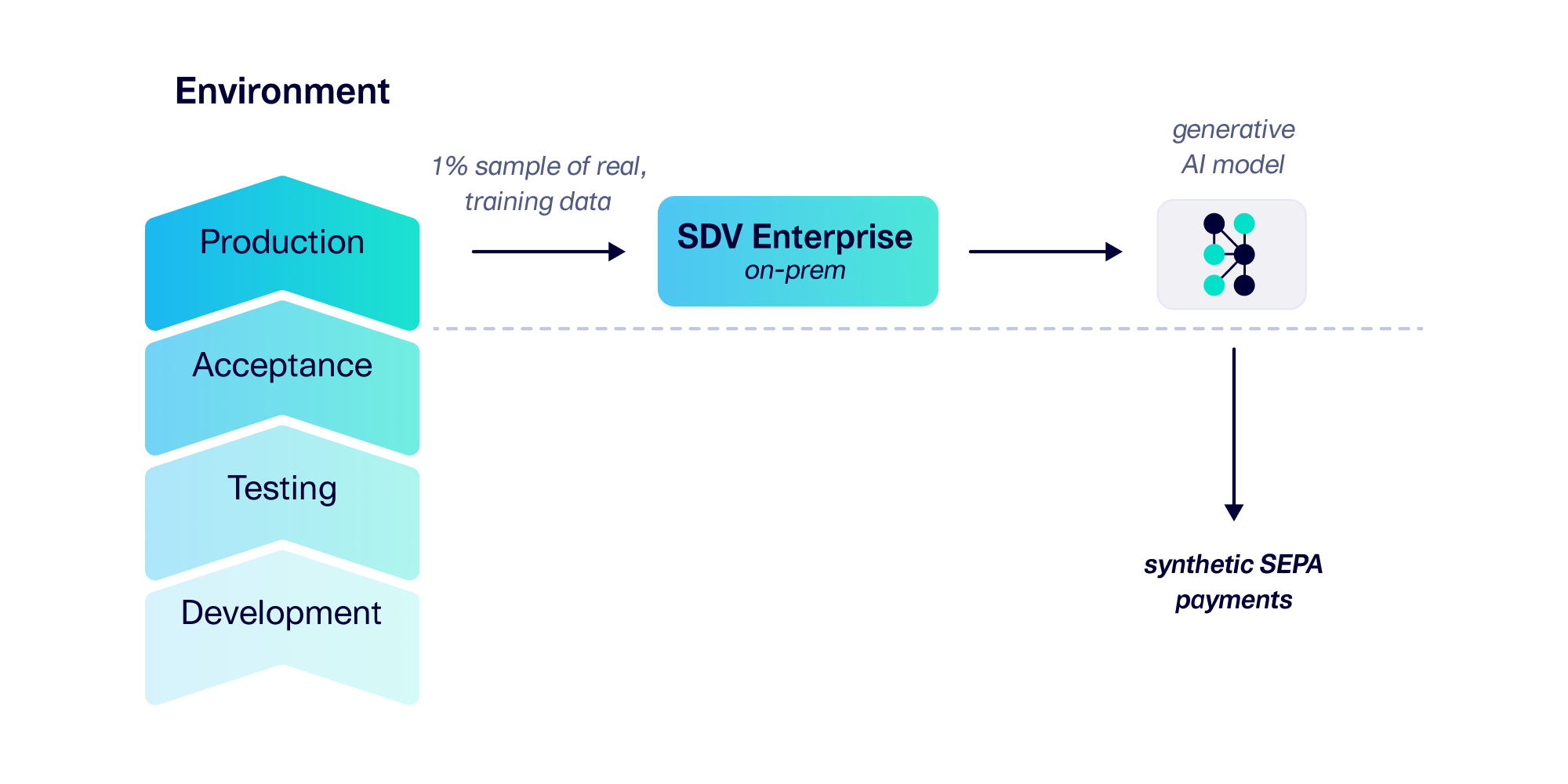
SDV Enterprise allows users to train their own generative AI model for a business application. ING trained their model using real, historical SEPA payments. The trained model could then generate any amount of synthetic SEPA payments, all of which follow the same structural and mathematical properties as the original.
Training a Generative AI Model On-Prem
SDV Enterprise is available as an on-prem developer package. The ING team made the SDV Enterprise software available in their environments, enabling SDV Enterprise to read data from the production environment. This allowed ING to train an AI model using 5K real SEPA payments from their production processing queue, which represents less than 1% of daily payments. Since SEPA payments are available in a structured XML, they could be easily converted to the tabular format the SDV Enterprise requires as input. The training process took less than 5 minutes using the local, on-prem hardware (no GPUs needed).
Creating synthetic data on-demand
After training, the ING team could generate any number of synthetic SEPA payments on demand. For example, sampling 10K payments took less than 2 minutes. Synthetic SEPA payments represented completely fake transactions between synthetic users. The ING team could now inject the synthetic data back into the lower environments for acceptance, testing and development – thus unblocking their workflow.
High Coverage vs. Low Cost? No Longer a Tradeoff
Before using generative AI, it would take, at minimum, one hour to create around 10 valid SEPA payments manually – and those 10 payments would not provide high enough coverage. With SDV Enterprise, generating as many as 10K synthetic SEPA payments takes only 2 minutes. This leads to a significantly larger number of scenarios covered in a fraction of the time. Even a conservative estimate leads to us measure 100x the coverage in 1/10th the time.
In other words, ING no longer had to choose between high coverage and low cost – synthetic data provided the best of both worlds.
Benefits of Adopting SDV Enterprise
As the team began to adopt synthetic data into their workflow, customization allowed them to create even more realistic synthetic data and reap more benefits:
- The constraints feature allowed ING to input business rules that were especially important to the application. There were logical checks to ensure that certain core assumptions of a synthetic SEPA payment would never be broken. For a complex application such as SEPA, the ING team encoded 3 business rules.
- The conditional sampling feature allowed ING to generate synthetic data with greater precision. Rather than leave the synthetic payments to chance, the team could explicitly request that the AI model generate particular payments, amounts, or accounts. This allowed them to quickly build up a minimal viable test set – that is to say, an easy-to-manage, smaller set of test data with high coverage for their usage.
An unexpected side benefit was that synthetic data allowed ING to explore new scenarios. For example, what would happen if the transactions on a few accounts spiked (stress testing)? Or what if the overall transactions increased in frequency (performance testing)? The team began to see more possibilities.
Ultimately, SDV Enterprise enabled the SEPA team to create and develop their test data in a more self-serve way. ING actively uses the synthetic SEPA payments to test their processing application today. They have continued to update the SDV Enterprise generative AI model as the SEPA payment structure continues to change. This deployment strategy ensures that the payment processing application remains robust to upcoming changes.