Synthetic Data Vault (SDV) is a software that uses generative AI to create high-quality tabular synthetic data. Tabular data is data that appears in tables, which contain rows and columns of information. To generate synthetic data, users train a generative model with some amount of real data, and then sample from it.
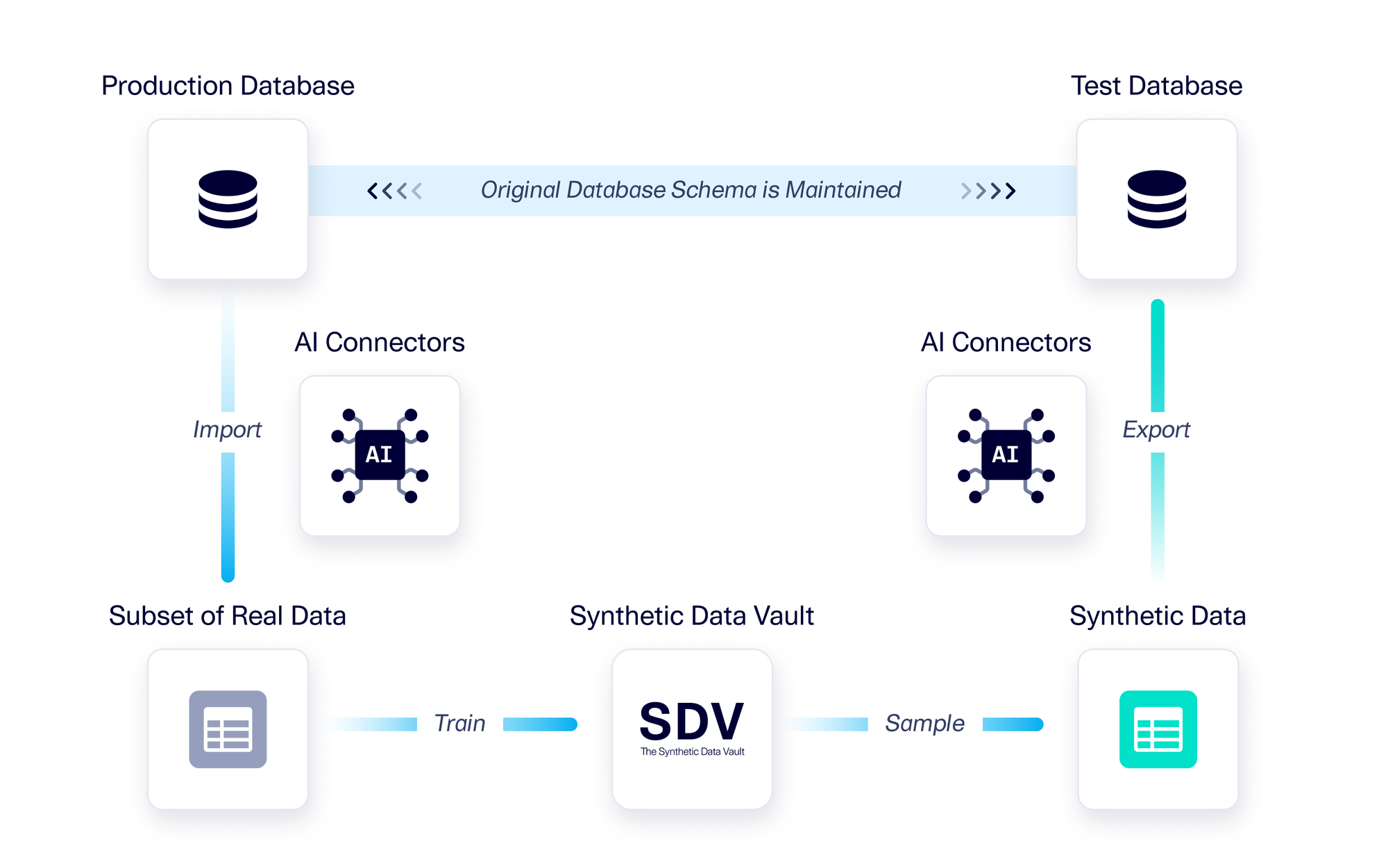
Often, this real data is stored in a database. To use SDV, users must export the tables from their database, load them into Python, create metadata, inspect it and update it, before training a generative AI model. Users face multiple challenges in this workflow, including creating accurate metadata, determining how much data to bring for training and, when working with multiple tables, exporting data while maintaining referential integrity.
Today, we are introducing a new bundle: AI Connectors. With this bundle, users can import data directly from a database, create metadata that describes the data, train a model, and export synthetic data. AI Connectors offers seamless integration with SDV synthesizers, with features specifically designed for generative AI. For example, here is an instance where AI Connectors is used with a Google BigQuery database:
from sdv.io.database import BigQueryConnector
from sdv.multi_table import HSASynthesizer
connector = BigQueryConnector()
connector.set_import_config(dataset_id='sales_dataset')
# Use the connector to create metadata and extract a real data training set
metadata = connector.create_metadata(tables=['products', 'transactions'])
real_data = connector.import_random_subset(metadata)
# Create synthetic data with SDV
synthesizer = HSASynthesizer(metadata)
synthesizer.fit(real_data)
synthetic_data = synthesizer.sample()
# Use the same connector to export synthetic data to a database
connector.set_export_config(dataset_id='synthetic_sales_dataset')
connector.export_data(synthetic_data)Currently, AI Connectors are available for AlloyDB, Oracle, Microsoft SQL Server, Google Cloud Spanner, and Google BigQuery. If you would like to propose an AI Connector for a different database, please fill out this form.
How does using AI Connectors improve your synthetic data?
To understand AI Connectors, let’s go over the challenges involved in importing data from a database, and the benefits this new tool provides.
Challenge 1: Creating highly accurate metadata for generative AI model training engines
Generative AI tools require a deeper understanding of data than is traditionally available in database schemas. While a database schema has valuable information, it is primarily concerned with how the data is stored, rather than with capturing real-world meaning and patterns. A traditional data schema generally includes information such as data types (integers, strings, floats, etc.) and constraints like NOT NULL or UNIQUE, and defines relationships through primary and foreign keys.
This database schema information is not enough for generative AI modeling — which is concerned not with how the data is stored, but rather with what it means. Generative AI requires more information in order to work well.
For example, defining a column as a string is not enough for generative AI. Instead, it needs to know whether that column contains datetime values, categorical values, or values with a high-level domain property (such as postal codes). The format of the column may also be important. For example, a datetime column may require a specific format, a float column may have a certain level of precision, and a postal code column may require a certain number of digits. Unlike a database schema, metadata can provide this information. To solve this problem, we defined a way to annotate columns and called these annotations "sdtypes." sdtypes for each column, along with the relationships between tables, primary keys and foreign keys, form the metadata required by SDV.
To get metadata without AI Connectors, SDV users have to load their data into memory and use SDV’s auto-detect feature. This feature can infer some of these semantic properties by analyzing the data, but this inference isn't always reliable. For example, SDV may not detect that a numeric column represents datetime values, or that certain text fields contain sensitive information. The auto-inference functionality may not pick up on all the relationships present in your data, such as a one-to-many relationship between customers and orders. Additionally, manually defining multiple columns and relationships can become tedious when automated inference falls short.

With AI Connectors, we have leveraged the database schema to automatically generate metadata that includes column types, primary keys, and relationships. We then built an internal inference engine to automatically create sdtypes for multiple different databases, thus creating more accurate metadata. Despite the limitations of a database schema, using it as a starting point helps ensure more accurate synthetic data generation.
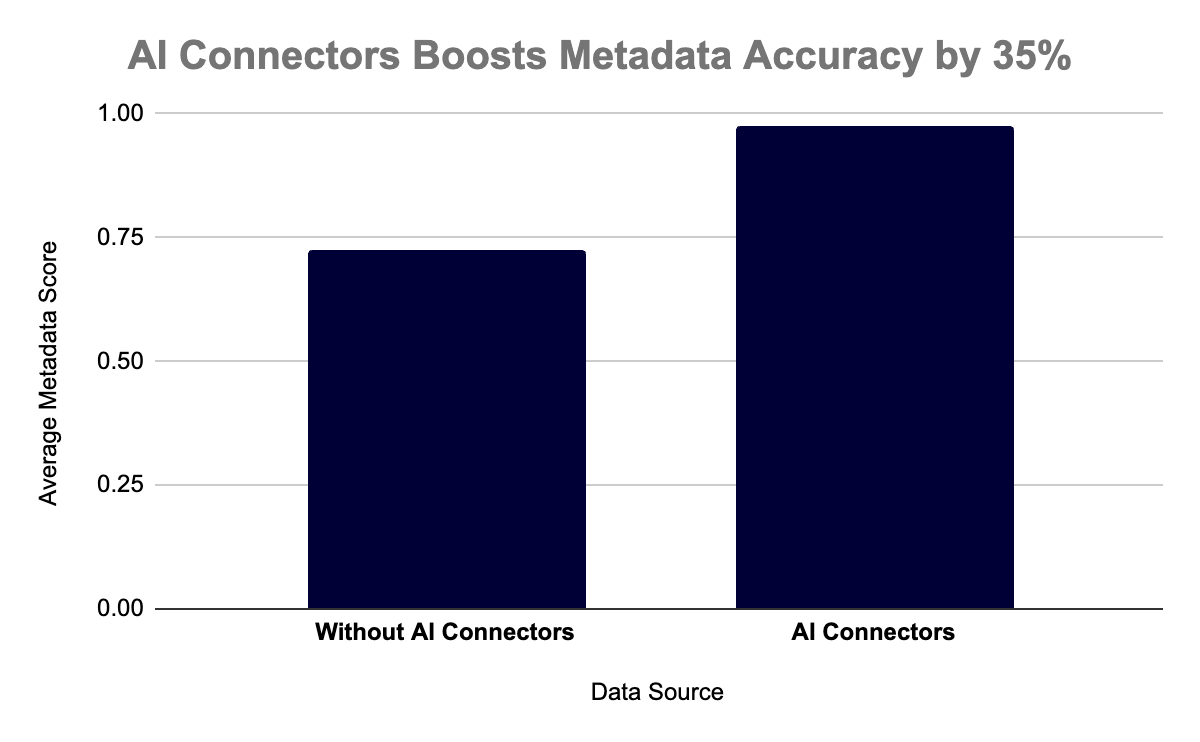
AI Connectors Boosts Metadata Accuracy by 35%
To understand how beneficial AI Connectors can be, let’s consider the metadata score. We designed this score to measure the accuracy of metadata detected through various means by evaluating column sdtypes, primary keys, and relationships. The metadata score compares the true metadata (derived through our own manual annotations) with the inferred metadata, and measures how many sdtypes are correct, how many primary keys are correctly defined, and whether all the true relationships are present. It is graded on a scale of 0.0 to 1.0, where a 1.0 score means the metadata is 100% accurate, meaning the sdtypes, the primary keys, and the relationships are all correct.
To evaluate how well AI Connectors detects metadata, we did an experiment. We started with 55 SDV demo datasets hosted by different databases (AlloyDB, Oracle, Microsoft SQL Server, Google Cloud Spanner, and Google BigQuery). The same 55 datasets were also present as local CSV files.
- When the CSV files were loaded into memory and the metadata was auto-detected, the average metadata score was 0.73.
- When AI Connectors was used with a direct database connection, the average metadata score was 0.98 — a ~35% increase.
This is because the database connection allows for access to the underlying data schema, leading to more accurate sdtypes, primary keys and relationships, and even more accurate formats of datetime columns. In the few instances where sdtypes were not inferred, this was because the database did not have the level of specificity that our inference engine required to determine the sdtypes (for instance, "address", "email", or "credit_card_number” would all be stored as strings in a database).
Challenge 2: Providing training data for generative AI models
To effectively train generative AI models using SDV synthesizers, users need to provide quality training data. Two critical factors are:
Finding a representative subset of real data to train on, rather than using the full dataset. When training an SDV synthesizer, one of the questions our users always ask is how much training data should I provide? One of the primary motivations for creating a synthetic dataset is to mitigate the need to access production data, so if we need terabytes or billions of rows of real production data to train a model, this defeats the purpose. Additionally, even if a large amount of data is available, using it can greatly increase the time it takes to train your model, without actually having a noticeable effect on the quality of the synthetic data generated (for more information, see our previous blog post).
Creating training data with referential integrity. Within the training data, each foreign key must reference a valid record (e.g., every order links to an existing customer). Without referential integrity, the SDV synthesizer can't learn proper relationships, which leads it to produce poor-quality synthetic data. For example, if orders aren't connected to their corresponding customers, the model won't correctly learn the connection between customer attributes and ordering patterns.
- It can be tricky to export a subset of the data while ensuring referential integrity. You might consider randomly sampling X rows from each table while disregarding the foreign keys, and dropping the invalid rows afterwards — but this may result in too small of a subsample.
- You might write complex SQL queries to look at multiple tables — but this may be tedious and time-consuming.
While either of these approaches could work, they can be tricky to implement. They are also not guaranteed to result in high-quality data that is referentially sound.
When we built AI Connectors, we invented a Referential First Search (RFS) algorithm that guarantees that the real data used to train the model is a subset with referential integrity.
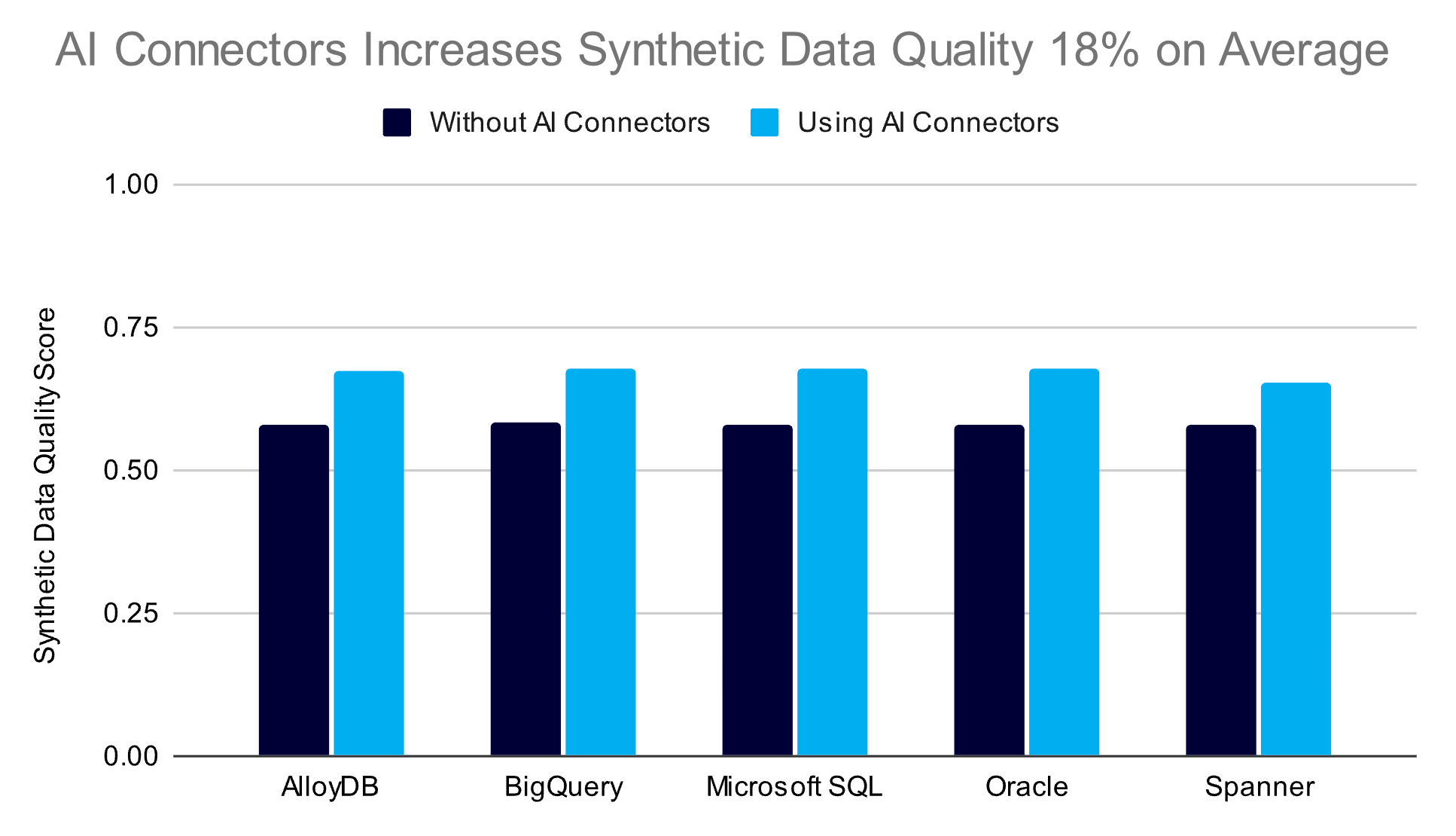
AI Connectors Increases Synthetic Data Quality 18% on Average
To demonstrate how AI Connectors impacts data quality, we tested seven large SDV demo datasets stored across AlloyDB, Oracle, Microsoft SQL Server, Google Cloud Spanner, and Google BigQuery:
- airbnb-simplified
- CORA
- FNHK
- ftp
- imdb_MovieLens
- SalesDB
- Telstra
For this experiment, we wanted to measure how the quality of synthetic data changed based on the training data that was used as an input. We scored quality between 0.0 and 1.0, where a score of 1.0 indicates that the synthetic data patterns and the real data patterns are identical, while a 0.0 score indicates opposite patterns.
The experiment compared two approaches to create training data:
- Without AI Connectors: The training data was created by randomly sampling rows from the multiple tables. To enforce referential integrity across data from multiple tables, rows were dropped manually using SDV’s drop_unknown_references.
- With AI Connectors: The training data was created using the data subsampling algorithm that is part of the AI Connectors.
Both approaches used HSASynthesizer to generate synthetic data. AI Connectors achieved an average of 18% higher synthetic data quality score. This shows that sampling random data and then enforcing referential integrity afterwards (as in the "Without AI Connectors" scenario) limits the amount of real data that can be trained, resulting in lower-quality synthetic data.
Export synthetic data to a database while matching your database schema
After users generate synthetic data with SDV, they often need to export it to a database for downstream applications like software testing. These applications expect a production database schema. However, writing synthetic data to match a production database schema can be challenging.
With AI Connectors, synthetic data is exported to match the production database schema, enabling seamless integration with existing workflows. The downstream application does not have to change at all to work with the synthetic database — it just has to point to it instead of to the real database.
Key Benefits of AI Connectors
AI Connectors streamlines synthetic data generation by directly connecting to a database. This approach offers three key advantages:
- AI Connectors infers high-level metadata concepts from the database schema. In our experiments, this achieved a 35% improvement in metadata accuracy compared to manual methods.
- AI Connectors imports a data subsample that is AI-ready and has referential integrity. In our experiments, this resulted in higher-quality training data, which improved synthetic data quality an average of 18%.
- AI Connectors exports synthetic data to a database in the same format as the original imported data, enabling users to access it easily in downstream applications.
If you are interested in using AI Connectors, please contact us.
Get access to AI Connectors
AI Connectors is available as a bundle for SDV Enterprise users. This bundle supports a variety of databases, including AlloyDB, Oracle, Microsoft SQL Server, Google Cloud Spanner, and Google BigQuery. Additional database types are coming soon!
The AI Connectors bundle has been released in Limited Availability for SDV Enterprise customers. If you're an SDV Enterprise customer interested in trying this in-Beta feature and providing feedback, please contact us.