
SDV Enterprise offers a variety of techniques for generating synthetic data. As of now, we have three different multi-table synthesizers, each of which creates fully valid synthetic data for complex schemas.
In this article, we'll walk through our approach to multi-table data, and explain how each of our synthesizers uses a fundamentally different algorithm – allowing users to choose between them based on quality and performance factors. By the end, you'll understand the differences between our synthesizers and be able to identify which one is right for your project.
What is multi-table data?: More than just a set of tables
Users often tell us that their data takes the form of multiple tables. At face value, this may not seem too challenging for synthetic data creation ("Why not create synthetic data one table at a time?"). But the reality is more complex.
At its core, multi-table data represents interconnected entities. For example, an e-commerce company might be keeping track of product lines, customer profiles, and orders. All three of these entities are connected to each other and likely to even more entities, including some that are added over time as the company's needs change.
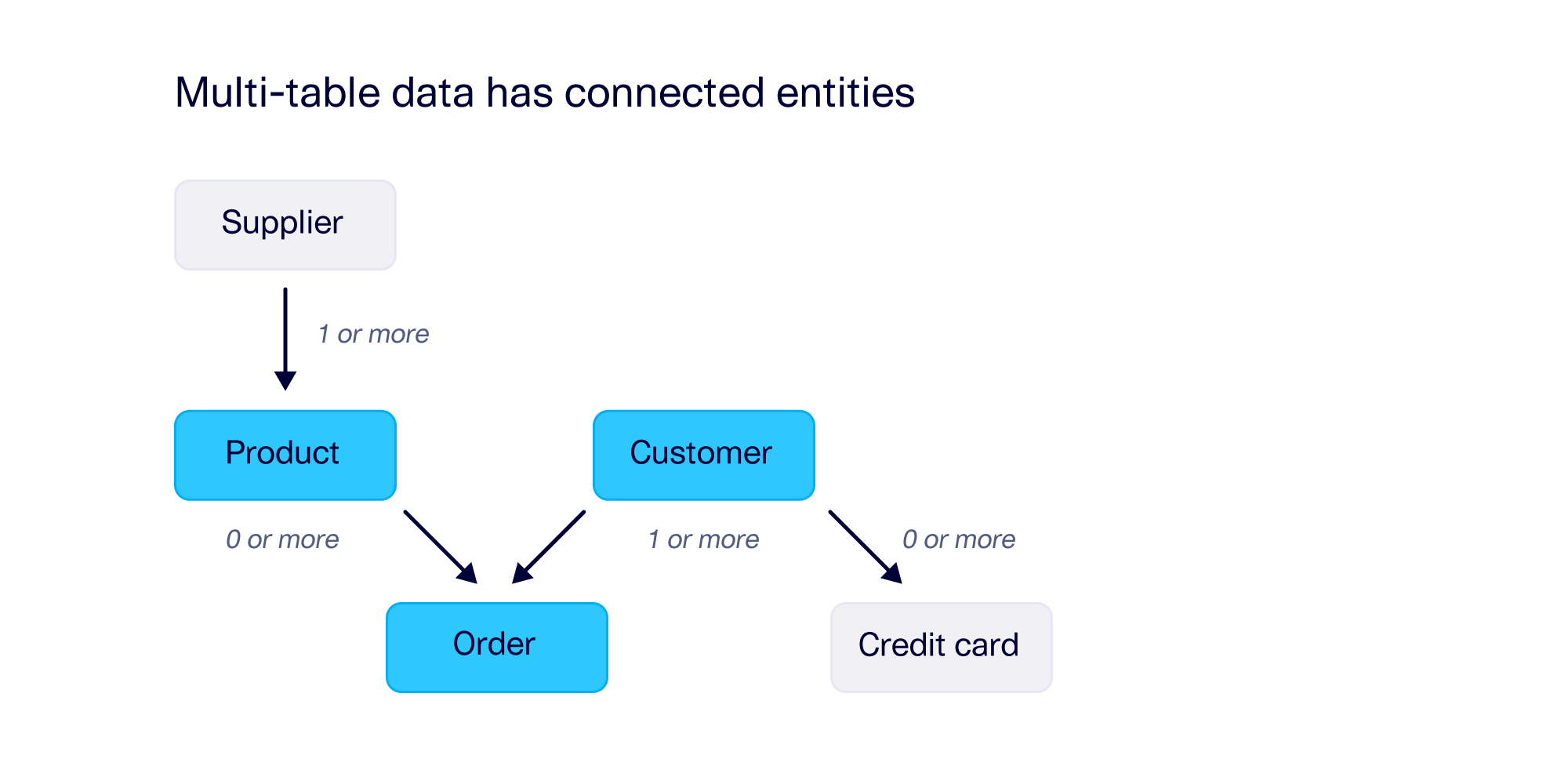
In the data itself, a connection is made when different tables contain references to the same value. For example, if every order is linked to a customer, that means that every order references a customer ID — which then may appear in other tables, with more associated information.
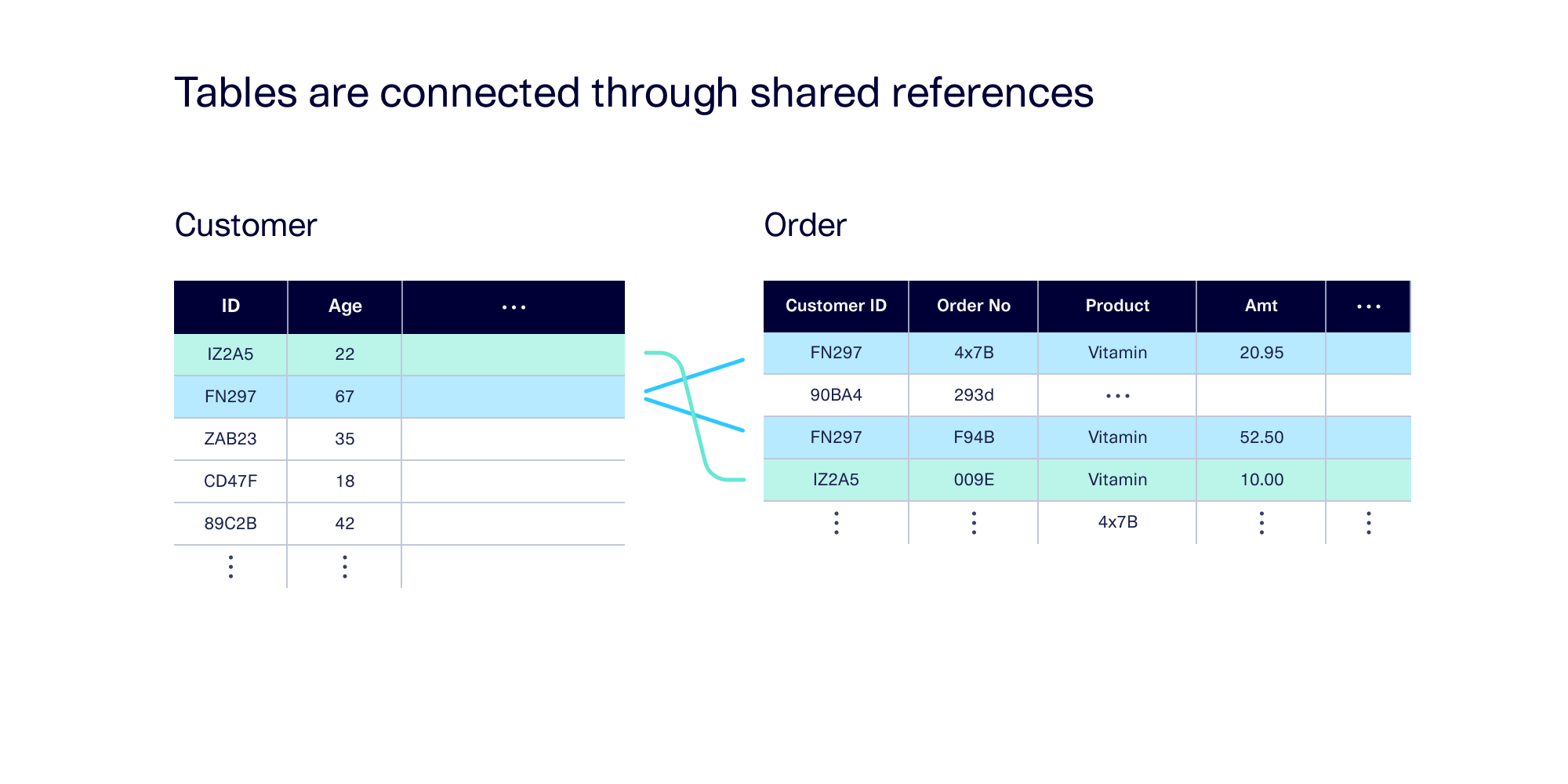
A connection between two tables allows for other interesting data patterns to occur between them. These patterns include:
- Cardinality, or the number of links that occur between elements. For example, perhaps every customer must have at least 1 associated order, and 50% of customers have 2 or more orders.
- Intertable trends, or correlations between the other columns. For example, a customer's age may correlate with the amount they spent on an order. Even though these columns are present in different tables, intertable trends exist due to the connection between the tables.
Herein lies the challenge of working with multi-table data: The presence of connections between the tables means there are many more data patterns that we need to learn and preserve in order to create high-quality, realistic synthetic data.
Multi-table synthetic data is in our DNA
When building SDV Enterprise, we decided to embrace the challenges inherent in creating quality synthetic data that preserved intertable patterns and could stand in for all kinds of multi-table datasets. Since the very first iteration of our product, we have worked to create synthetic data in a multi-table setting. Today, as we continue to build SDV Enterprise, we remain committed to modeling and synthesizing data for all kinds of complex, multi-table schemas.
Over time, this commitment has allowed us to formulate a framework for creating synthetic multi-table data. We start by pre-processing the data, incorporating customizations such as business rules and anonymization. Then we run a proprietary multi-table algorithm to learn about the patterns between tables. Finally, we learn patterns within each individual table.
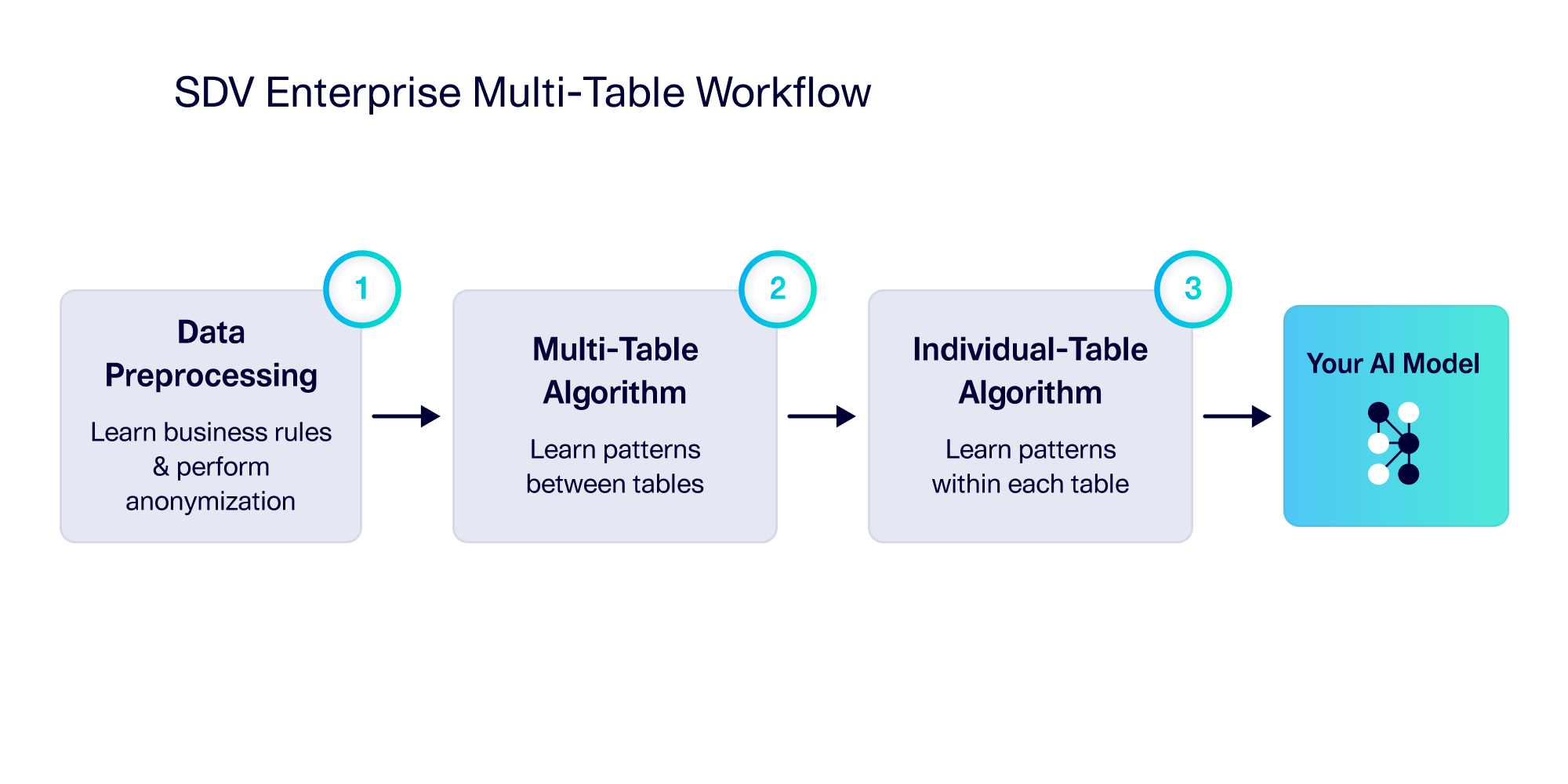
The core of this framework is step #2: The multi-table algorithm. This algorithm seeks to learn from the connections between tables, an area ripe for innovation. Our workflow is abstracted in such a way that we can insert different algorithms into this step while preserving the rest of the functionality for users. It also means that no matter which algorithm we use, we can offer the same set of features for the other steps.
Today, we encapsulate this workflow in a synthesizer. Each synthesizer contains a different multi-table algorithm (step #2), so each navigates data in its own way.
Meet the SDV Enterprise multi-table synthesizers
SDV Enterprise currently offers three multi-table synthesizers: The original HMA Synthesizer, first released in 2018, as well as two recent additions, the HSA Synthesizer and the Independent Synthesizer. To understand their characteristics, it's important to know their history.
HMA Synthesizer
HMA (Hierarchical Modeling Algorithm) was described in the 2016 paper that originally introduced the SDV, and was made available as part of our very first release in 2018. Although it's gone through many significant improvements since then, the core goal of the algorithm remains the same: This synthesizer is designed to exhaustively capture all patterns between tables.
This goal is more complex than it seems. We've seen intertable trends between tables that are directly connected to each other, but HMA also aims to capture trends between tables that are indirectly connected. For example, in the schema below, products and customers are not directly related to each other, but they are indirectly related through the orders table. This means that there may be trends between the two tables. In this sense, we can view HMA as a brute force algorithm that aims to understand absolutely every possible pattern in the schema.
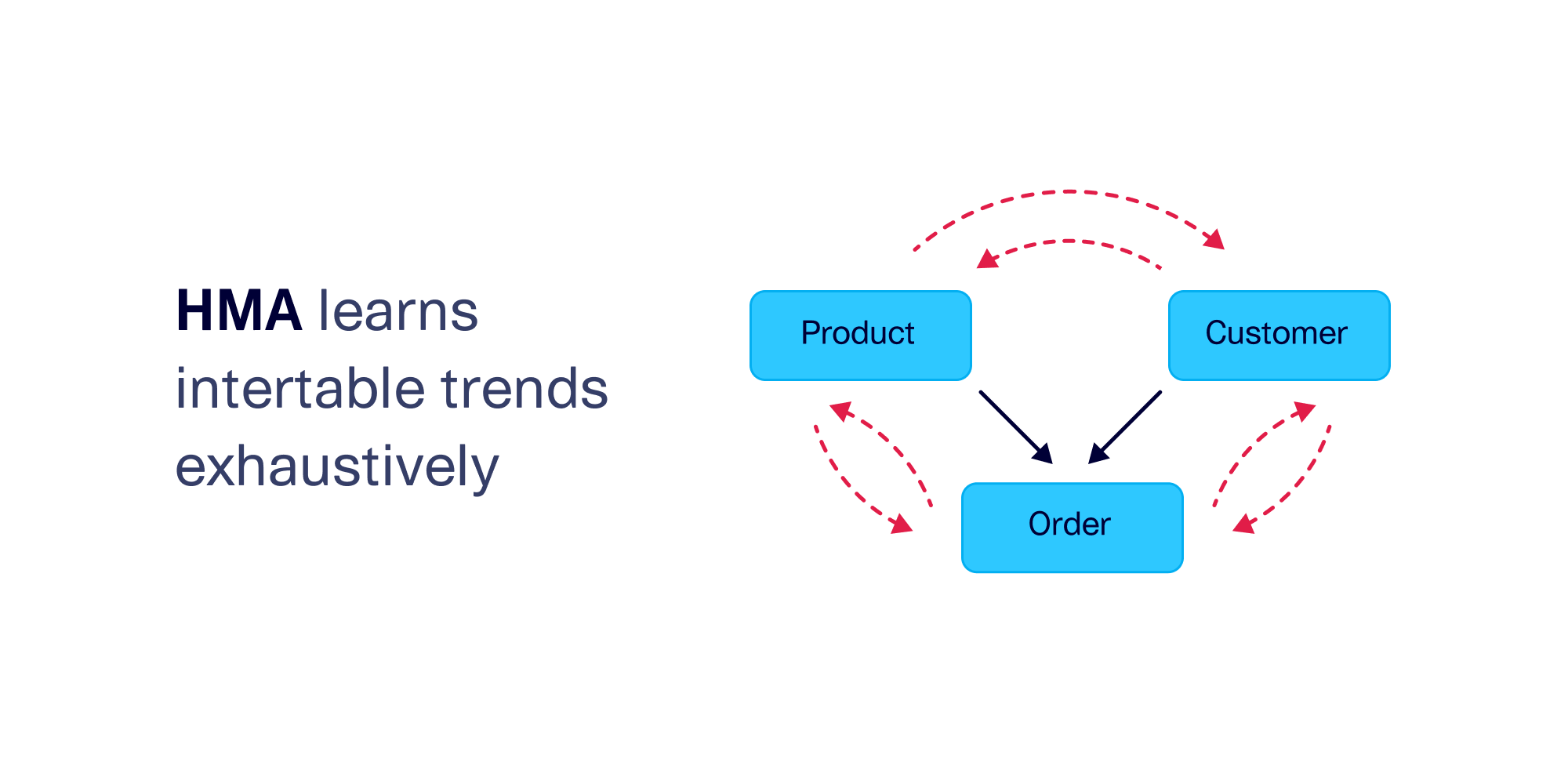
The downside is that this level of thoroughness is hard to scale. We find that modeling more than 5 tables can lead to performance and memory issues on a standard machine. Still, HMA is a popular choice for small datasets.
HMA is also our only multi-table synthesizer that is available to the public. It is a useful entry point for anyone getting started with synthetic data. We provide functionality to simplify complex datasets with many tables, which helps scale down the schema into a smaller, more manageable set of tables. Used this way, HMA is useful for completing a proof-of-concept project – and deciding whether to purchase SDV Enterprise for access to our other synthesizers.
HSA Synthesizer
We invented HSA (Hierarchical Segmentation Algorithm) in 2022, with the goal of allowing more scalability than is available with HMA. HSA can model complex multi-table schemas that contain 20 or more tables – in various configurations.
In order to do this, HSA makes a tradeoff. Instead of exhaustively computing all possible intertable trends, HSA summarizes the information. The summaries also influence indirect connections between the tables. Overall, this technique allows for faster computation while still capturing the major trends. As an added bonus, HSA is more efficient at learning each table individually.
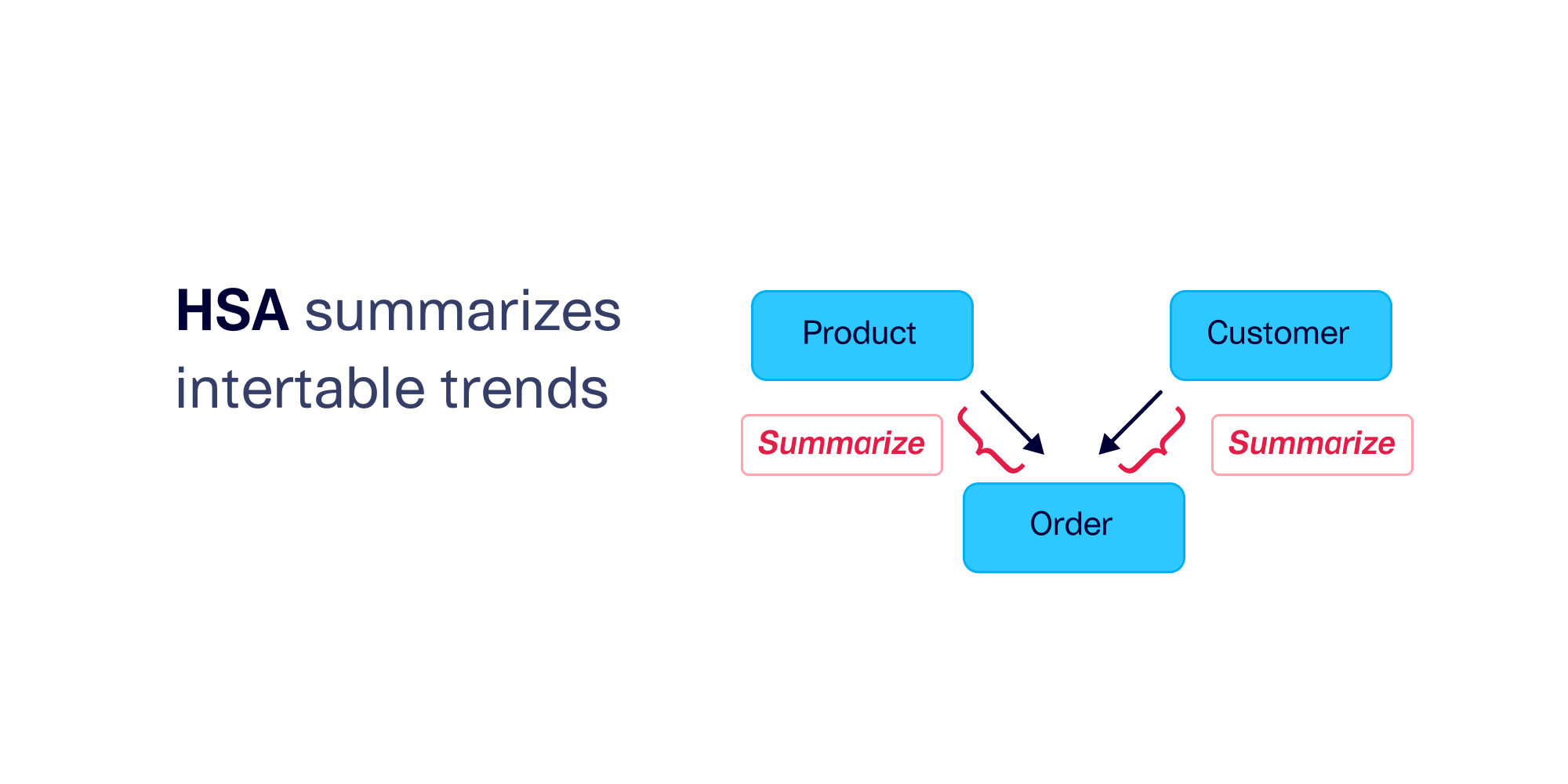
The result is a flexible algorithm that is suited for larger datasets. Many of our customers love HSA because it allows them to easily model complex, enterprise-grade schemas while still understanding the most important aspects of intertable trends and cardinality.
Independent Synthesizer
Finally, we released the Independent Synthesizer in 2023. If the original HMA Synthesizer is the slowest, brute force approach, then our Independent Synthesizer is the other extreme: This is our fastest synthesizer, able to scale to vast amounts of tables with virtually unlimited complexity. The tradeoff is that it only learns the bare minimum for creating valid data.
We designed the Independent Synthesizer to only learn the patterns inside each individual table. It does not learn any intertable trends, instead connecting the tables randomly based on basic cardinality rules. Our customers choose this synthesizer when intertable trends do not exist – perhaps if their data tables represent independent works that don't have many interesting patterns.
Takeaway
At the end of the day, SDV Enterprise users can choose between three synthesizers, each capable of supporting complex, multi-table schemas. The main difference is in the learning algorithm — the three different algorithms that power the synthesizers each approach the task of learning about table interconnectedness differently.
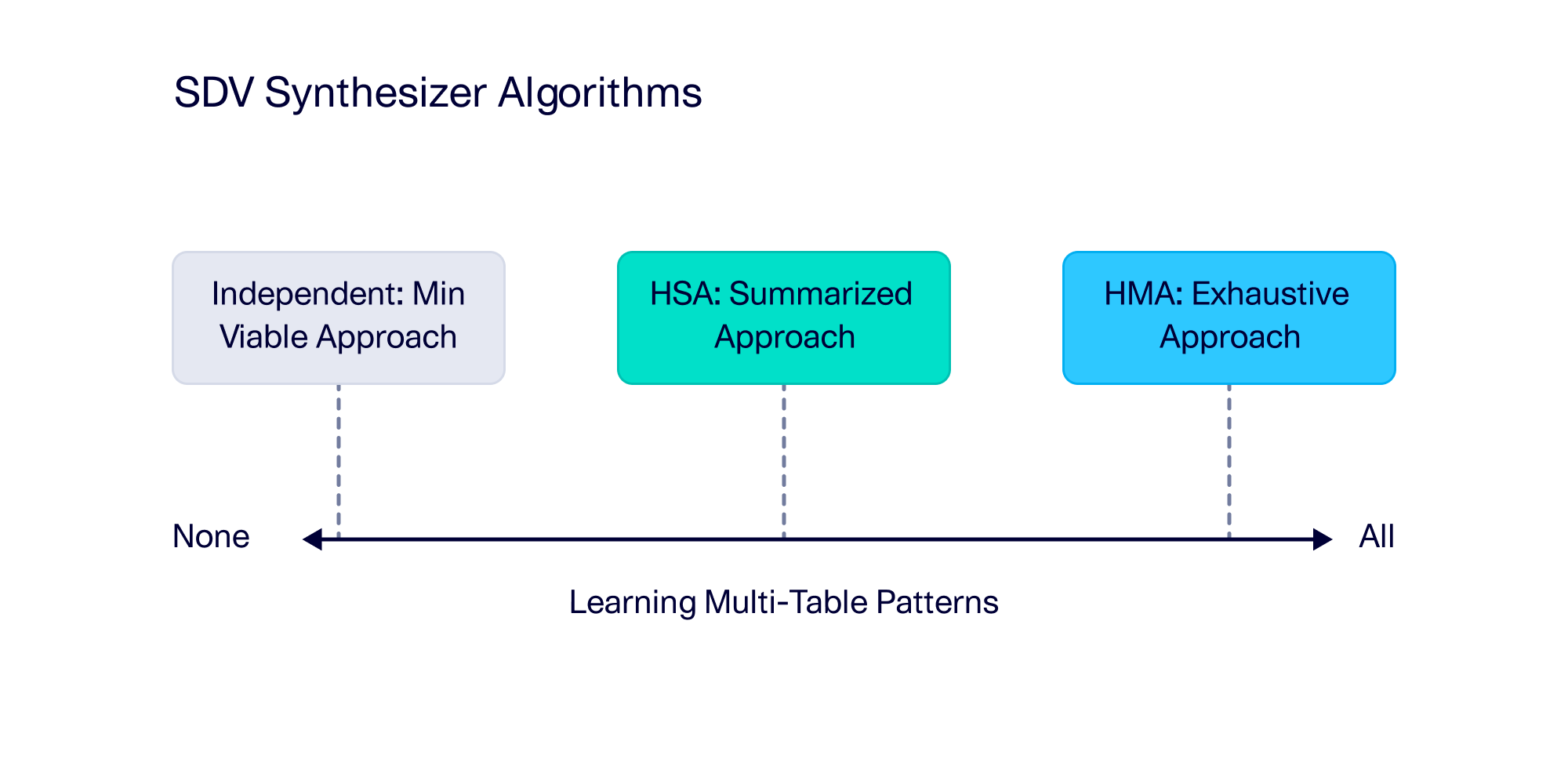
Comparing synthesizer quality and performance: An experiment
How well does each algorithm meet its goals? To answer this question, we conducted an experiment by applying each synthesizer to 20 of the demo datasets offered in the public SDV library. These datasets were small enough that we could run HMA without encountering performance issues, but diverse enough to represent a wide variety of schemas. Our results help to quantify the differences between the three synthesizers.
Intertable trends showcase the algorithmic differences.
The most significant algorithmic difference between our synthesizers is in the way they learn (or don't learn!) intertable trends. We measured the quality of the intertable trends within the synthetic data generated by each synthesizer using the open source SDMetrics library. This library reported a score that ranged between 100% (best quality) and 0% (worst). The graph below shows the average intertable trends score — filtered to show only the trends that were strong in the real data, as these are the patterns that matter.
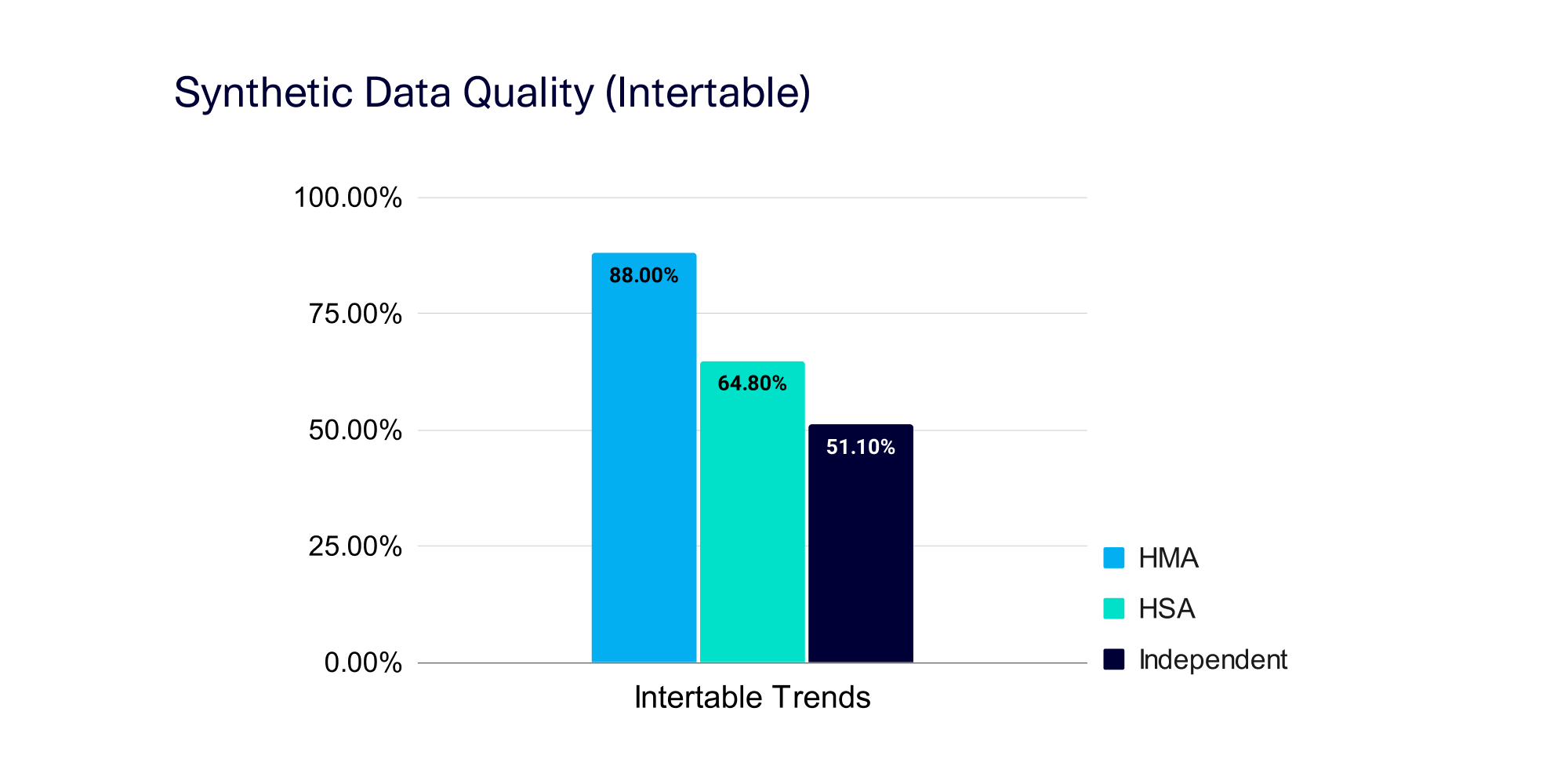
These results illustrate that each synthesizer is doing what we intended. HMA excels at capturing intertable trends, which is no surprise since it performs the most exhaustive computations of all our algorithms. Independent is the worst at capturing trends, landing around 50%, as it's designed to learn the bare minimum, often creating random connections between tables. HSA dutifully falls somewhere in between, since it's summarizing the information.
Individual tables are important too.
For a complete picture of the synthetic data quality, we also measured the patterns present within each individual table. We used the following measures, also from the SDMetrics library:
- Column Shapes, which measures the marginal distributions of individual columns
- Column Pair Trends, which measures correlations between columns in the same table. To focus on the patterns that matter, we filtered our results to show only the correlations that were strong in the real data.
These scores also range from 100% (best possible quality) to 0% (worst). The results are shown below.
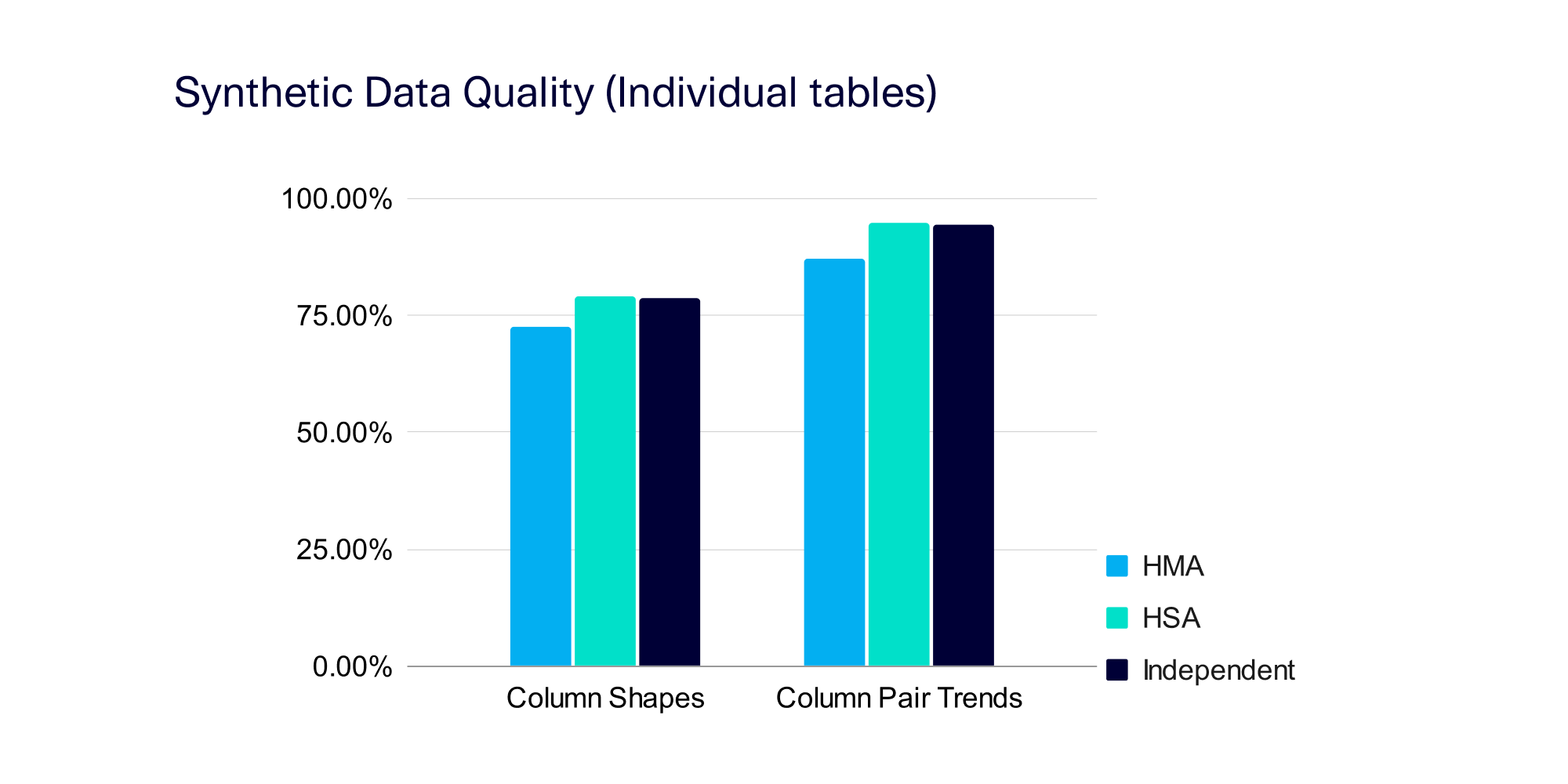
The individual table scores show a closer spread across the three synthesizers, with HMA performing slightly worse than the other two. This illustrates a trade-off in the algorithm's focus: In its attempt to exhaustively learn intertable trends, HMA slightly loses out on capturing patterns inside each individual table.
The results thus far seem to suggest that HMA is a good choice — but synthetic data quality is just one piece of the puzzle. The algorithmic complexity of HMA makes it tricky to apply to large, enterprise-grade schemas, where other concerns like performance are important too.
A tradeoff for intertable trends: Insane speedups in performance
During this experiment, as each synthesizer was modeling and sampling synthetic data, we measured the time it took to finish all 20 datasets. The results speak for themselves: HMA sits the slowest at around 1 hour, while HSA finishes in under 1 minute. The Independent Synthesizer is the fastest, finishing in under 30 seconds! This explains a common sentiment we hear when customers first try HSA: "These speedups are insane!"

Most datasets are much larger than the demos we used for our experiment, which means that in a typical setting, performance challenges are amplified. The difference between HMA and HSA can be the difference between waiting multiple days for each batch of synthetic data vs iterating in a matter of minutes.
For anyone looking to build a sustainable solution for a complex dataset, performance quickly becomes a key consideration. For this reason, many customers end up opting for the HSA Synthesizer, which combines accuracy and speed.
Which synthesizer wins?
It's tempting to choose an overall winner. But as with all AI projects, the answer really is – it depends! Our three options allow you to choose between performance and exhaustive modeling, or between learning intertable patterns vs. individual table patterns. The true answer is that you may want to use different synthesizers for different projects.
No matter what you choose, our goal is to ensure you receive the same great features and a guarantee of valid synthetic data every time.
Ready to get started? The HMASynthesizer is available in our public library. Try it on your smaller datasets for a proof-of-concept.



