

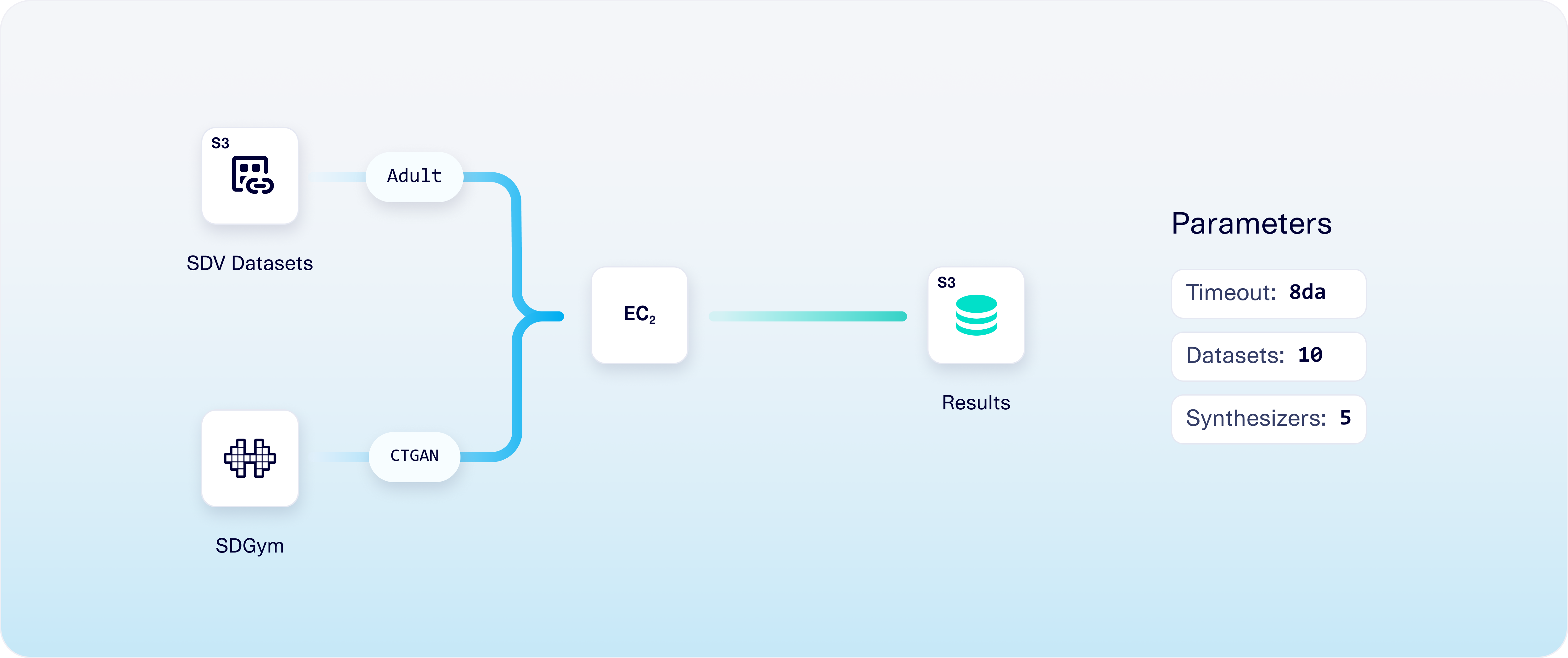
SDGym is a publicly available benchmarking system for synthetic data generation techniques. You can learn more about it in our documentation.
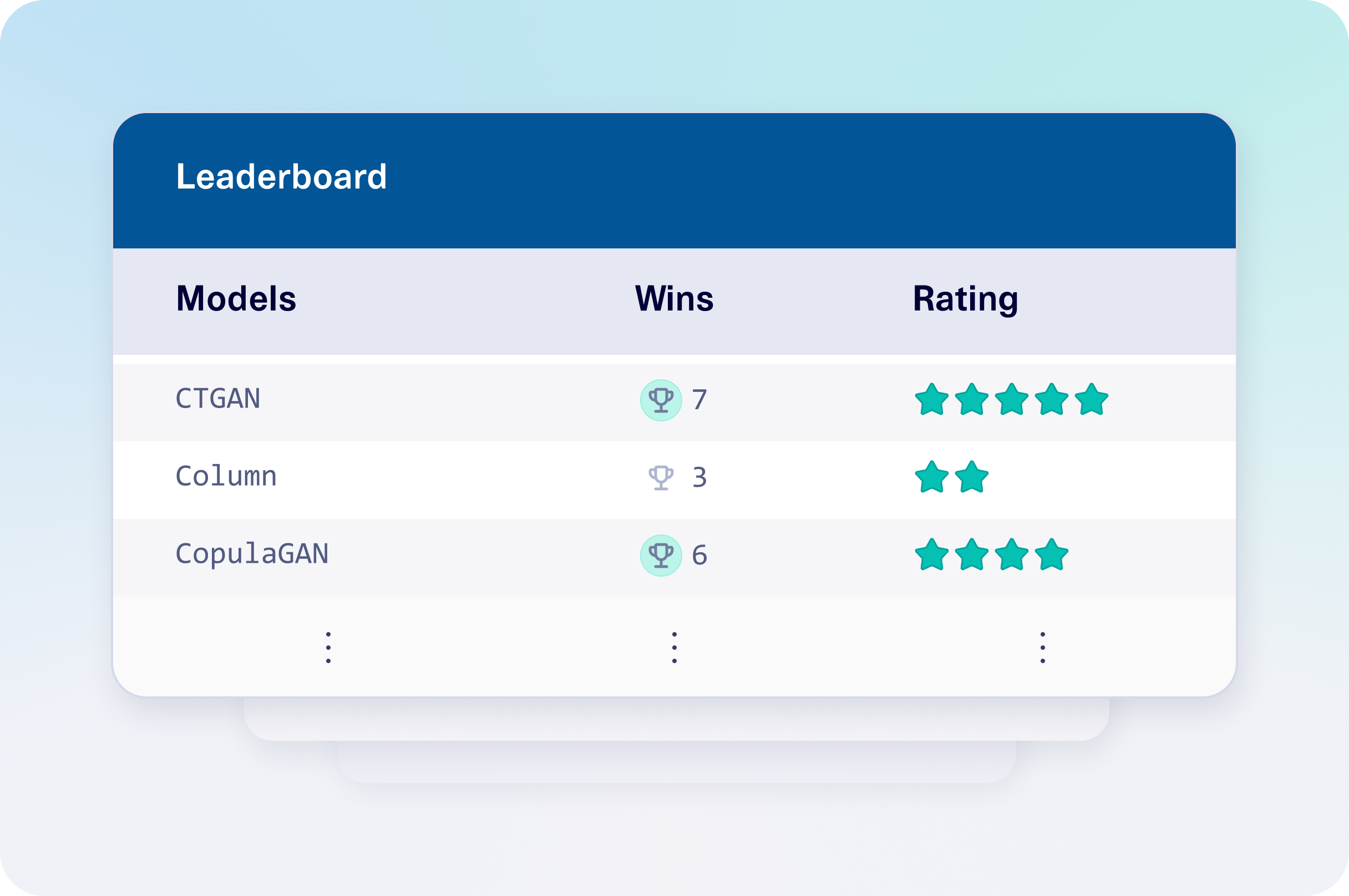
Leaderboard
Last Run:
Models
Wins
The Quality-Speed Tradeoffs
The Optimal Frontier of Synthetic Data—Where Performance Becomes Clear, and Comparisons Go Beyond Quality Alone.
Model Cards
Datasets
Common Q&A
Below are some common Q&A that might help you understand more about SDGym.
from sdv.datasets.demo import download_demo
from sdv.single_table import GaussianCopulaSynthesizer
real_data, metadata = download_demo(
'single_table', 'fake_hotel_guests')
synthesizer = GaussianCopulaSynthesizer(metadata)
synthesizer.fit(real_data)
synthetic_data = synthesizer.sample(num_rows=10)Basetransformer


Follow us
Join our Community
Chat with developers across the world. Stay up-to-date with
the latest features, blogs, and news.



