We started SDV open source in 2018 at MIT with the goal of creating a powerful, usable, machine learning-based synthetic data generation software system. The core belief that drove us was the conviction that more than 90% of data work can be done using synthetic data instead of real data. Early experiments at MIT had been promising and we were ready to invest our time and energy into that promise.
Now, 3 years later, we are pleased to see that the market demand for synthetic data is increasing. In a 2021 article, Gartner predicted that 60% of data used for AI & analytics will be synthetic by 2024.
As time progressed, we used feedback from our users to make numerous improvements to the SDV (see articles Part 1 and Part 2). In response, we've seen increased usage, validating the market need for synthetic data generation software. In this article, we'll describe the SDV growth trends in detail.
Persistent 4x/year growth in downloads
Every year we are experiencing a 4x increase in SDV downloads. In 2021, we had 135,000 downloads of SDV – up from 30,576 in 2020. From the start of 2020 to the end of 2021, we have seen 16x total increase in SDV downloads. The figure below shows our yearly usage.

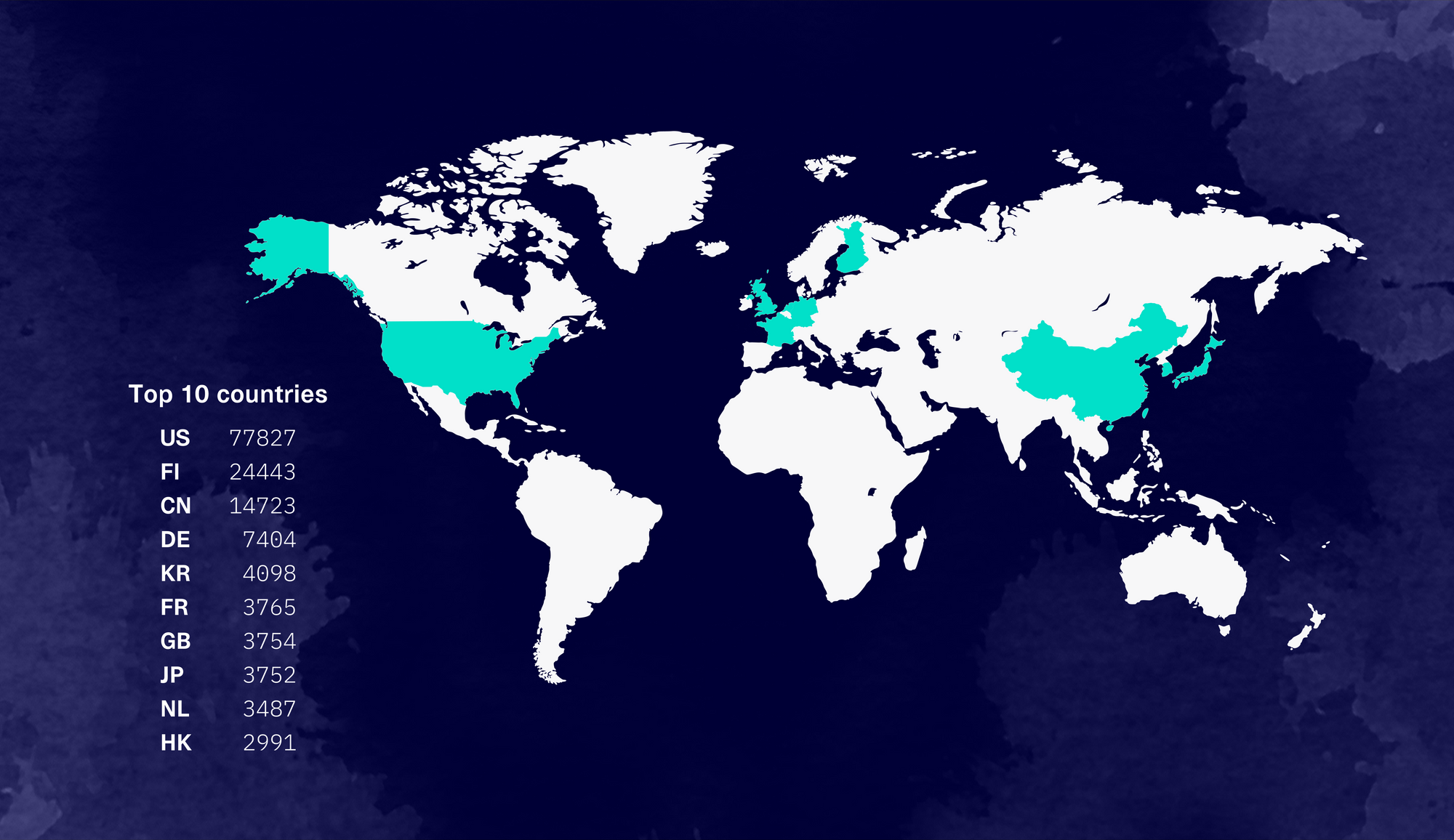
The downloads are coming from all over the world. In the map below, we list the top 10 countries.
Why are users downloading the SDV? We know that they want to create synthetic data, but they are using the synthetic data to solve a variety of different needs. We will explore this more and share it in a future article.
Over a thousand new community members
Another measure of our growth – and validation from the market – comes from the SDV community we've built on our GitHub and Slack. In 2021, we welcomed more than 1000 new members to these spaces.

As this article points out, members contribute in several different ways: Many help increase awareness of an open source solution for this enterprise pain point. Meanwhile, others jump in, use it and give feedback actively. In 2021, we doubled the number of unique users raising issues on our GitHub. Throughout the year, over 200 members actively participated in our forums by raising GitHub issues or contributing to discussions on Slack.
Enterprise feedback is particularly useful to us. This type of feedback comes from users who are solving targeted business problems with the SDV. Direct and succinct feedback explains what would make the SDV more useful. An example is shown below.

Our team addresses the user feedback throughout the entire SDV ecosystem. The ecosystem includes not only modeling, but also the ability to compare models through SDGym and measure synthetic data quality through SDMetrics. In 2021, the team put out 49 releases throughout the SDV ecosystem, doubling our number of releases in 2020.
Looking forward to 2022!
We are looking forward to 2022! With so many users giving us feedback, we have a long list of features that we want to incorporate. We can't wait to share with our community what everyone is using SDV for, and keep on climbing to our original goal: 90% of data work accomplished with synthetic data.