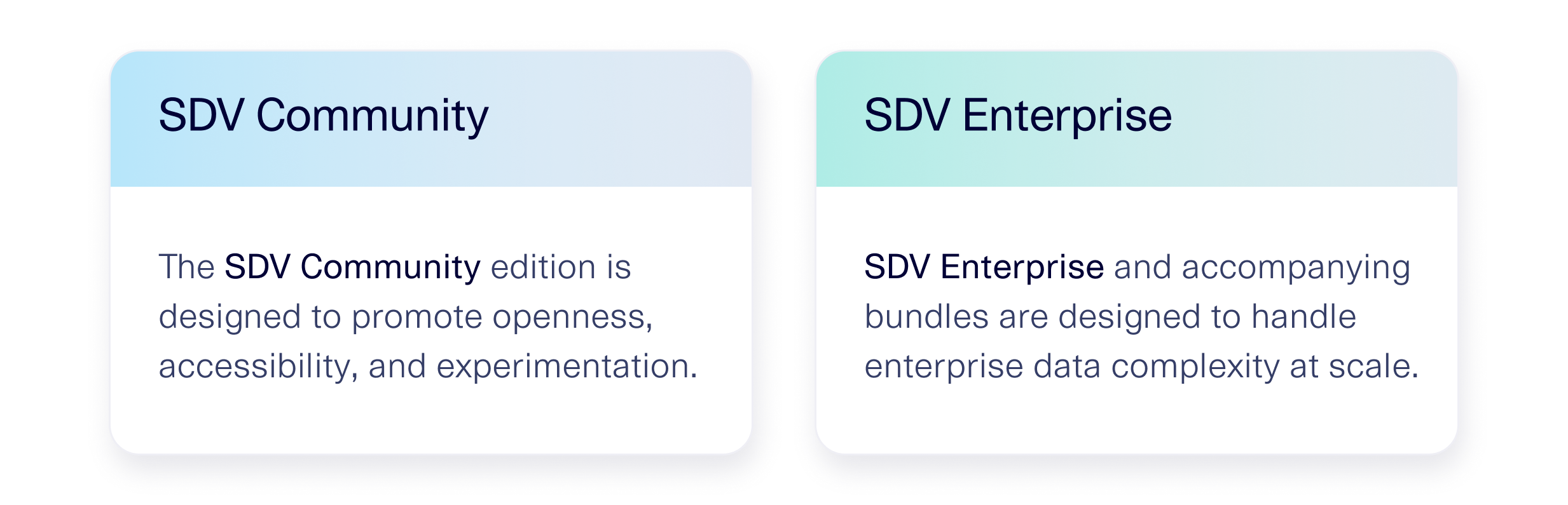
DataCebo offers two versions of The Synthetic Data Vault: SDV Community, which is publicly available under a business source license, and SDV Enterprise, our paid version that can handle the complexity inherent in enterprise data. If you're benchmarking tools used for enterprise needs, comparisons with SDV Enterprise are much more valid than comparisons with SDV community.
SDV Community is widely used and freely available. As it has gained traction, vendors have increasingly used it as a benchmark for their own offerings. They encourage organizations to use it for comparisons as well, and because SDV Community is free and has low overhead. Vendors then signal enterprise readiness for their own immature products by showing marginal improvements over SDV Community's performance. Several enterprises have also been encouraged to do such comparisons when a vendor contract was up for renewal.
Unfortunately, such comparisons are inherently flawed, and often result in purchasing decisions that lead to perilous integration roadmaps. This article shares our perspective, and aims to serve as a guide for decision-makers who wish to compare other products with SDV.
Many synthetic data products can't handle enterprise-grade data complexity, which leads to perilous integration roadmaps
Over the past two years, we have heard from many enterprises who have adopted synthetic data products from various vendors, only to find their capabilities limited.
Enterprise data environments are extremely complex. They're characterized by rich schemas, interconnected tables that must be modeled together, and critical database contexts and lineages that must be preserved. In some cases, this lineage information must be detected automatically because it is not otherwise available.
Building generative models that perform reliably in these settings requires substantial capabilities, above and beyond generative modeling techniques alone. As a result, enterprises working with immature tools run into problems. Here are just a few examples of issues that we've heard about:

Vendor tactics, risks, and what you can do about it
If you're looking for enterprise-grade synthetic data, watch out for these vendor tactics. They could give you the impression that a product will work for you when it really won't.

Here is a real life scenario where a vendor benchmarked against SDV Community. The vendor chooses arbitrary settings in SDV Community to claim superiority. A vendor claimed SDV Community’s HMASynthesizer failed to preserve referential integrity in multi-table datasets. In reality, both SDV Community and SDV Enterprise include SDV Guarantee, which ensures that synthetic data maintains integrity across related tables. We could not reproduce the reported results by the vendor. After we raised the discrepancy, the vendor reviewed and retracted the comparison. This highlights the need for accurate, reproducible evaluations when assessing enterprise-grade synthetic data solutions.
An important yardstick: If you see a comparison of a synthetic data generation product against SDV Community, it's very likely that the product does not have any functionality that will address enterprise grade complexity.
The right approach is to compare against SDV Enterprise
If you're working with complex, enterprise-level data, you'll get the best information from a comparison with SDV Enterprise.



