When you are working with user data, data anonymization is an especially important consideration. Many enterprise datasets contain sensitive or personal identifiable information (PII) that should only remain in the hands of the data controller. Even your own employees accessing PII data may lead to accidental exposure, due to everyday testing and development mistakes. The general best practice is to apply PII anonymization as the first step before sharing your data – even internally – or using it for a project.
There are many anonymization solutions today that allow you to fake, change or otherwise obfuscate PII. However, these techniques may alter your data in a way that makes it unusable later on, depending on your downstream use. To address this, we invented contextual anonymization, a novel technique that allows you to anonymize PII values while retaining important context.
In this article, we'll discover what it means to create usable anonymized data and show you how contextual anonymization could be the answer you're looking for.
The 5 Usability Considerations
If you are a data controller, you want to anonymize PII in a way that still allows others to use the data to the fullest capacity. We have learned that preserving certain patterns is often critical to ensuring that the anonymized data is usable.
Let's illustrate this with a concrete example. For the remainder of this article, let's pretend that you have a dataset of donations to a political campaign. This includes information such as the donor's phone number, email, donation amount and tax amount.
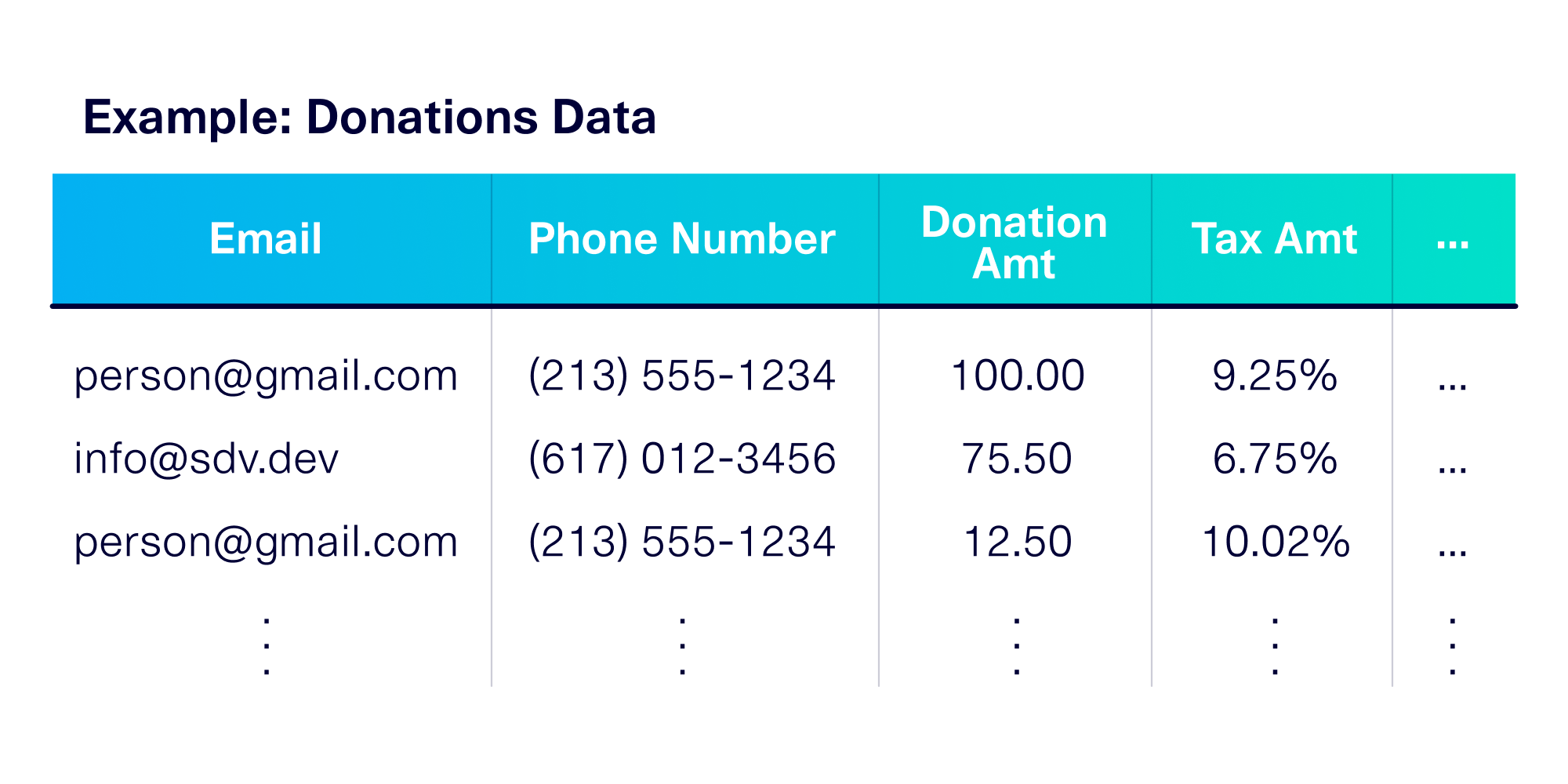
The phone number and email represent PII information. Even though you want to anonymize the PII, you want the overall data to retain some key patterns that were present in the original data. We refer to these as the 5 usability conditions for anonymization:
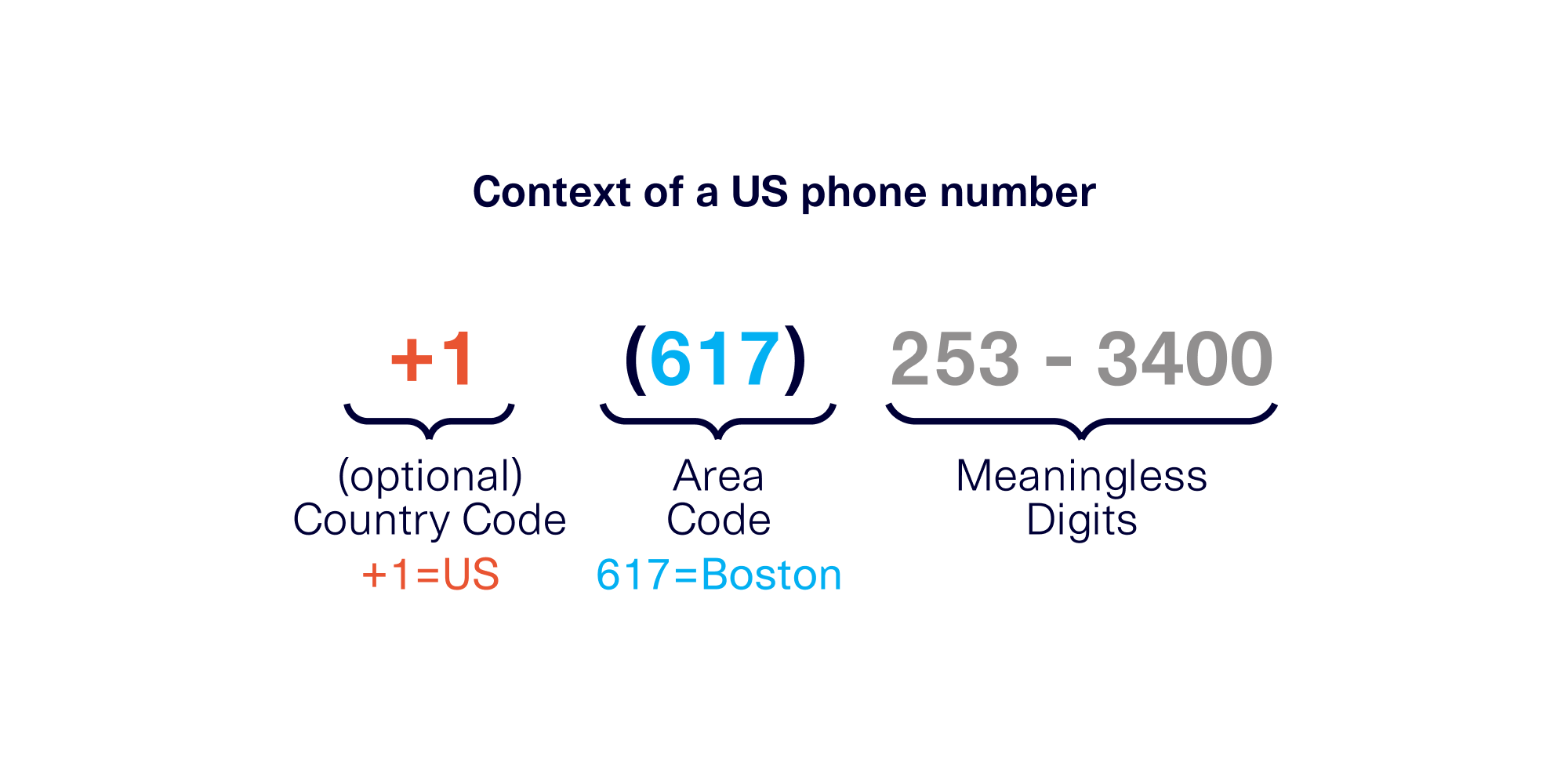
- The PII format, which refers to the overall look and feel of the PII. For example, the phone numbers in our dataset are in the specific format (###) ### – ####.
- The PII diversity, which counts the number of unique PII values present. For example, there may be 1000 unique phone numbers in the dataset.
- The PII frequency, which looks at the frequency of occurrence of a PII value. For example, a few phone numbers may have called 20+ times to donate, while other phone numbers may have made only one call each.
- The context realism, which refers to context in the PII and the deeper meaning associated with it. For example, phone numbers come from specific regions that are discoverable by the area code. The PII may include calls from the 213 area code (Los Angeles) and the 617 area code (Boston).
- The context interactions, which compares how the PII's context interacts with other data in your table. For example the tax rate is high in California, which should be reflected in the phone numbers: area codes 415 (San Francisco) and 213 (Los Angeles) should correspond with higher tax percentages.
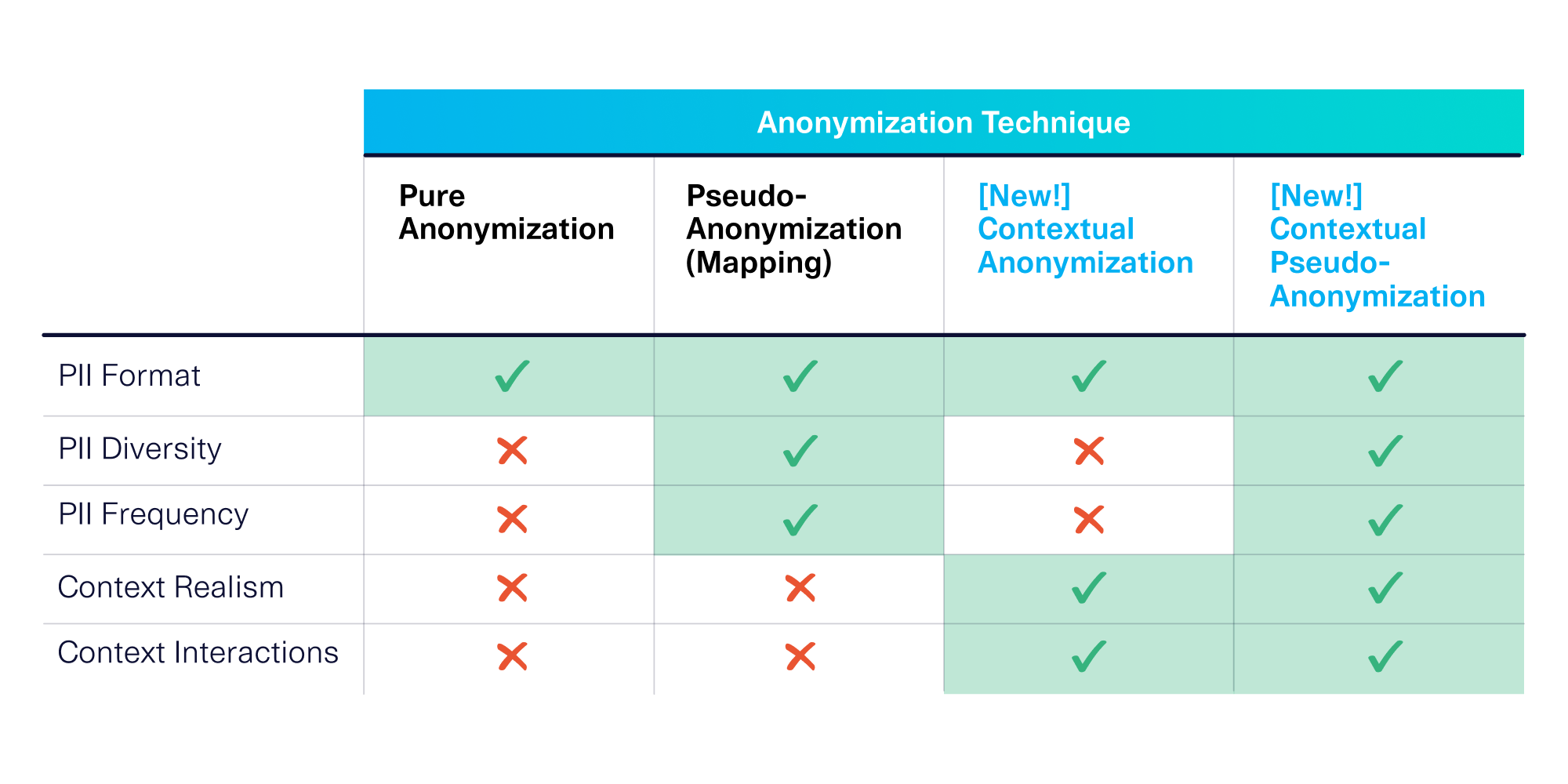
Through many conversations with our users, we've discovered these 5 axes can be critical to ensure that your data is usable in an anonymized state. Alarmingly, we found that the typically available anonymization techniques only meet the first three usability considerations. This is why we invented contextual anonymization, a new anonymization technique that deeply understands and incorporates the PII's meaning.
Why traditional anonymization features won't work
While a few anonymization techniques have already existed for years, we have found that these techniques are not equipped to give you full usability of your anonymized data.
Pure Anonymization
When you hear the term "anonymization," you may imagine the least complex version, which is called pure anonymization. Many software packages offer this technique, including the publicly available RDT library.
Pure anonymization randomly creates fake PII values without ever needing to look at the original data. The data is irreversibly anonymized, because there is no way to guess the original values based on the anonymized ones.

Pure anonymization preserves at most 1 of the 5 axes for data usability: the PII format (though some software does not even do this). The RDT preserves realistic formats, and even allows you to select specific locales to make them accurate. For example, the RDT makes sure the format of a phone number is country-specific.
Pseudo-Anonymization (Data Mapping)
Another common technique is pseudo-anonymization, or data mapping. To pseudo-anonymize PII, the anonymizer creates completely new, fake values, but does so using a consistent mapping scheme. As the word "pseudo-" implies, the anonymization scheme is reversible if you have the right information – i.e. the mapping. With this mapping, you can look up the original PII values, which may be useful if you are debugging or analyzing data. Keep in mind that the mapped values will still be randomly generated, offering you protection against leaking actual, sensitive information.
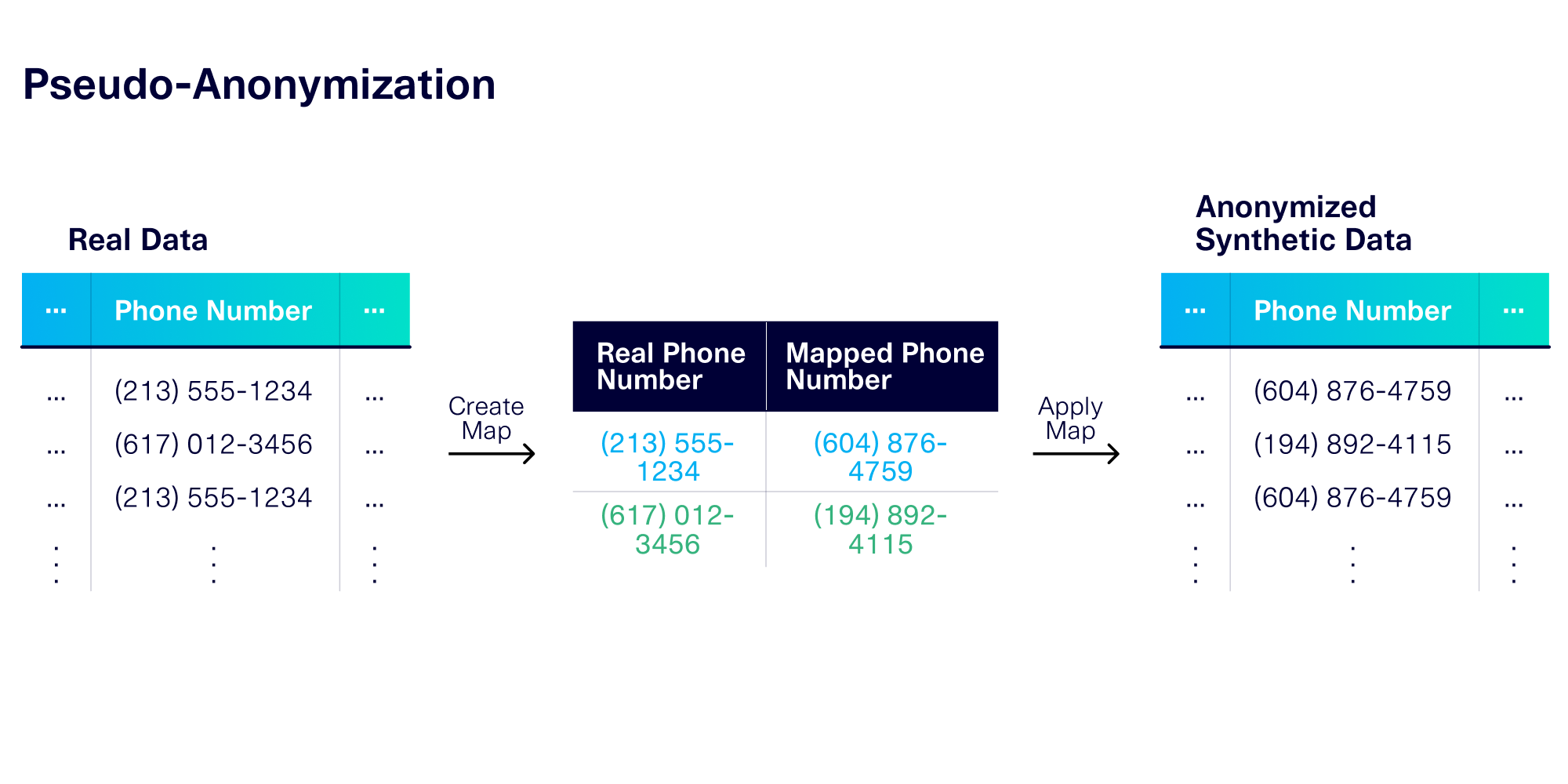
In addition to data format, the mapping process allows you to preserve 2 more axes of data usability.
- The data diversity: If the original data set contains exactly 1000 unique phone numbers the map will create 1000 anonymized phone numbers that correspond to them.
- The data frequency: If a few numbers appear 20+ times, the consistent mapping will ensure the corresponding anonymous phone numbers also appear the same number of times.
Nevertheless, pseudo-anonymization does not understand any information about the context of the PII.
Contextual Anonymization: Making your data more usable
DataCebo, Inc., invented the contextual anonymization technique in 2022 to address the problems of traditional anonymization. Much like these traditional techniques, our technique is available in two forms – pure and pseudo-anonymization. But our techniques also take into account the PII's context, allowing you to capture more nuanced properties of the data.
Contextual Anonymization
In pure contextual anonymization, we extract context from the PII and ensure that it is preserved during the anonymization process. So even though the anonymized data is completely fake, it has the same underlying contextual patterns.
What is context? "Context" represents the deeper, semantic meaning that we give to PII. The exact details depend on what the PII represents and what kinds of rules are used for it. For example, phone numbers are created to follow a particular pattern: The first few digits encode the geographical area (country or region) while the last few digits are random. So in this case, the context is the geographical area.
When we use contextual anonymization on phone numbers, we preserve the geographical context. The anonymized data contains random, new phone numbers – but within the same overall geography as the original.
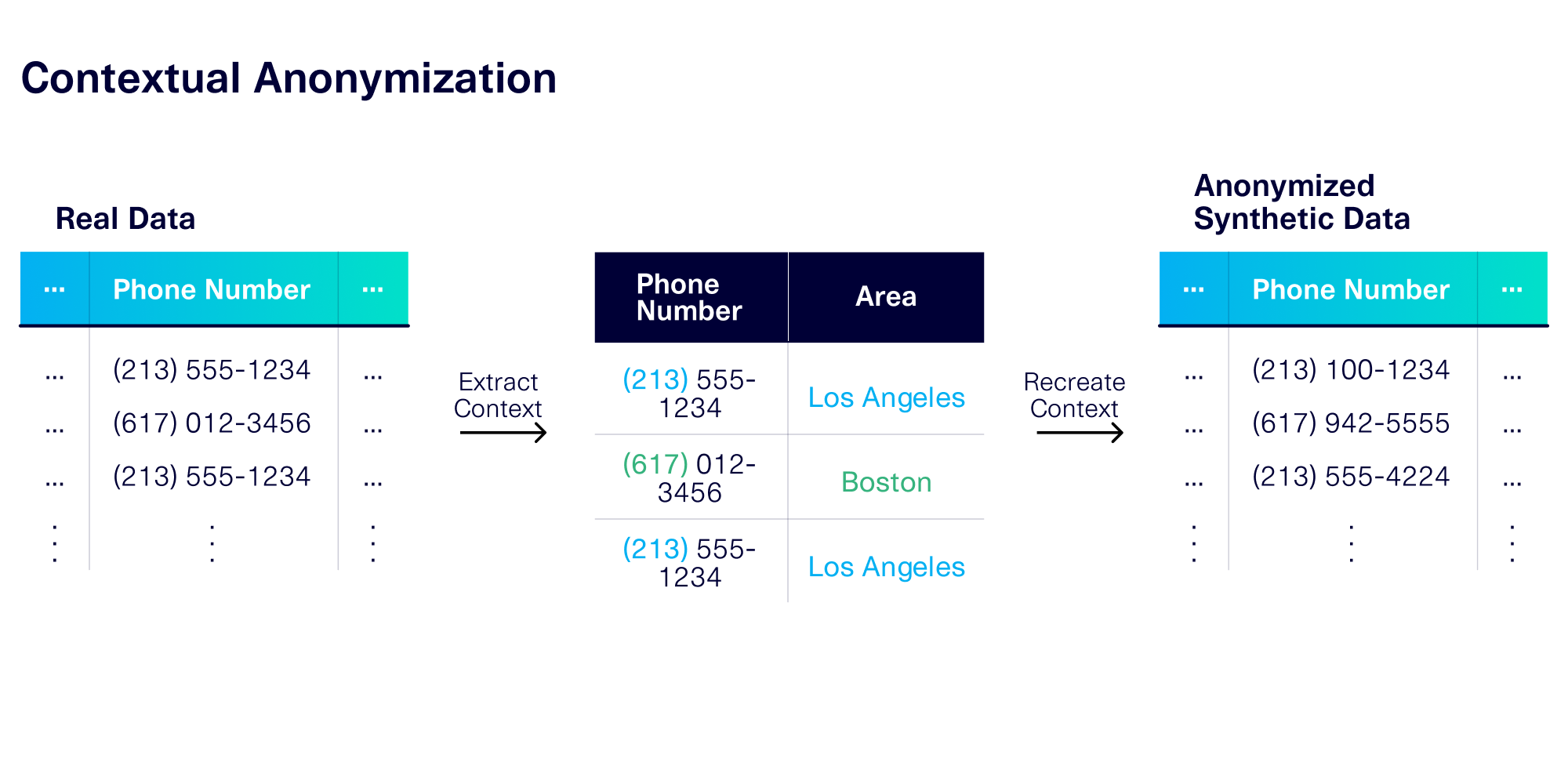
Contextual anonymization allows us to meet the remaining 2 usability axes that traditional techniques could not:
- Context realism is preserved during our process, including the geographical areas (Los Angeles and Boston) and how often they appear (Los Angeles appearing twice as often as Boston).
- Context interactions are also preserved. For example, higher tax rates will correspond with phone numbers from highly taxed areas, such as area 213 for Los Angeles, CA.
While we preserve the geographical areas, the remainder of the phone number is irreversibly anonymized. This means you won't be able to look up or guess the original phone numbers.
Contextual Pseudo-Anonymization
Finally, it's possible to apply a consistent, reversible mapping scheme on top of contextual anonymization. Using this technique, we extract the context from the original values and create a mapping to fake values that have the same context. For example, if an original phone number came from the Boston area, it will be mapped to a new phone from the same area.
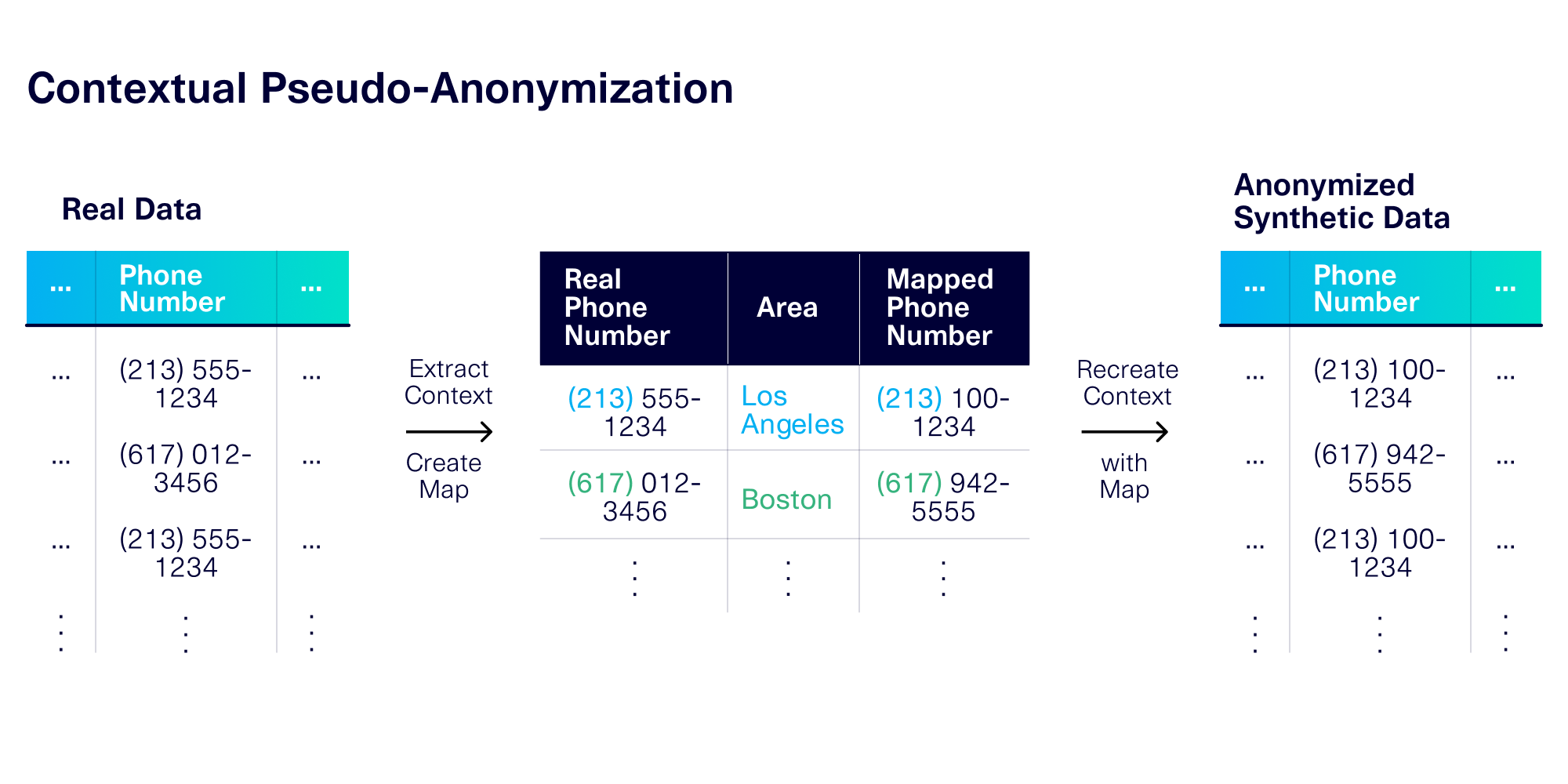
Contextual pseudo-anonymization allows us to capture all 5 axes of usability:
- PII format, from our underlying software.
- PII diversity and PII frequency, through the mapping process.
- Context realism and context interactions, through the context extraction process.
Applying Contextual Anonymization to your PII data
In this article, we focused on PII data that represents phone numbers. But contextual anonymization can apply to almost any complex type of data:
- From email addresses, we can extract context about the overall domain name (gmail.com, mid.edu, etc.) or the type of domain (free, commercial, educational, etc.).
- From credit card numbers, we can extract the issuer and bank.
- From an HTTP access log, we can extract the domain, subdomain, path and parameters.
- And more!
Anonymization is a great first step before you share your data or use it for a project such as synthetic data generation. The RDT software is publicly available as a Python library that allows you to get started with simple pure and pseudo-anonymization. Contextual anonymization is currently an enterprise feature that is only available to our licensed users. If you're interested in exploring contextual anonymization with us, please contact us with more details about your use case and data.