If you have ever worked with tabular data, you may be familiar with the concept of a data type: A description of the data in a column, for example numerical or datetime. This simple concept serves a crucial purpose – it allows software to correctly process the data in that column.
As the core developers of the SDV, a software for creating synthetic data, we're very aware of the importance of data types. Because we can only build optimal machine learning algorithms if we know the type of data we are dealing with, we have carefully defined the data types we use, which we call sdtypes (synthetic data types).
Through interacting with hundreds of users, we've realized that one common sdtype is frequently misunderstood: categorical data.
In this article, we provide a closer look at categorical data, so everyone can better understand its nuances and improve their usage of data science software like the SDV. By the end of the article, you'll be able to:
- Define categorical data,
- Understand what it means to create synthetic categorical data, and
- Avoid common misidentifications of categorical data.
What is Categorical Data?
We'll start with a more precise definition of categorical data: Categorical data is data that comes from a predefined set of values. One common example of categorical data is the tax filing status of US taxpayers. The status must be one of five categories – single, married filing jointly, married filing separately, head of household or widower. This is illustrated in the table below.
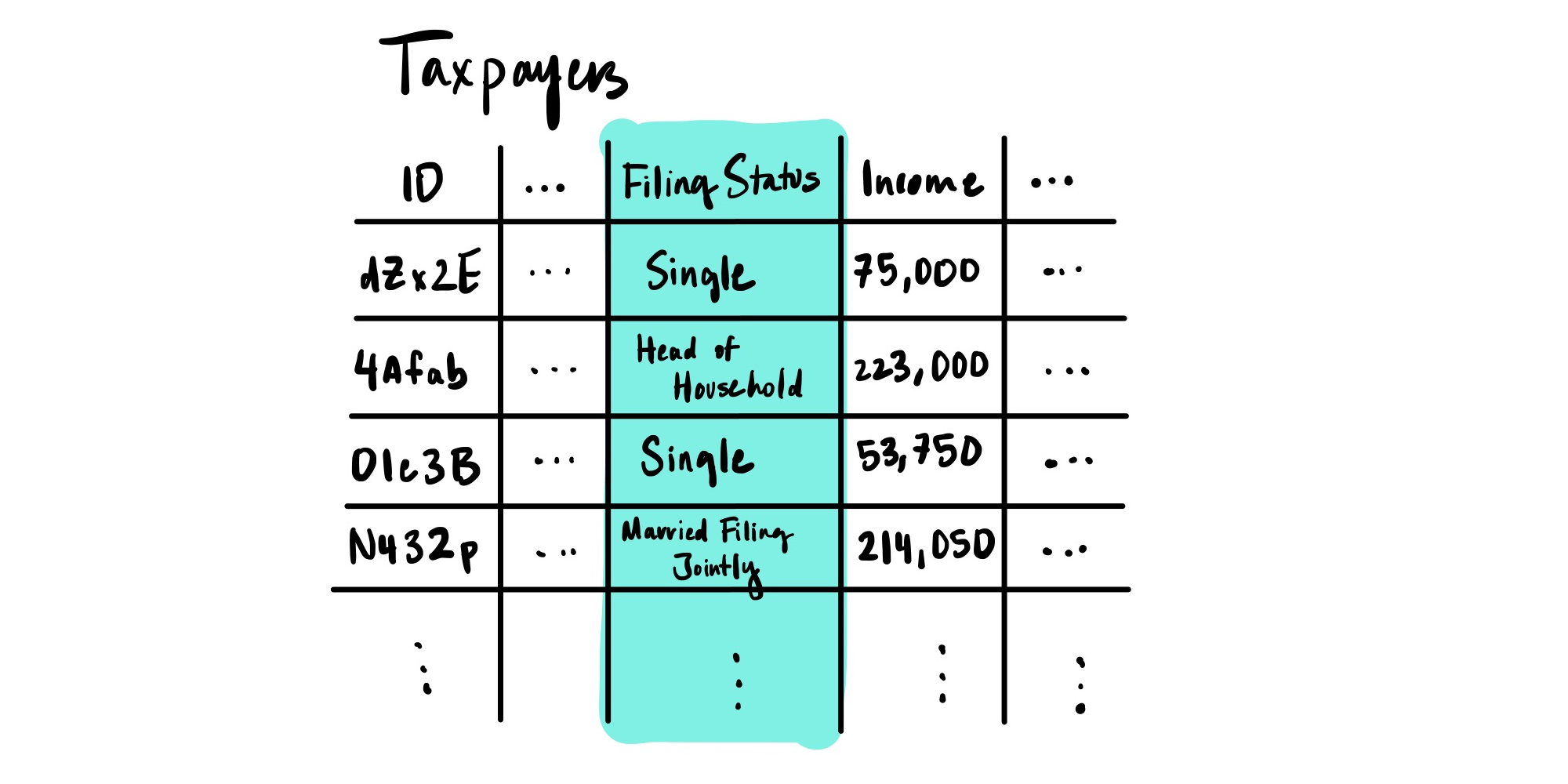
The tax filing status meets our definition of categorical data: There is a predefined set of values – in this case, the 5 statuses. (With categorical data, the possible values are called category values.) No other value is acceptable.
Can categorical data have an order?
Many times, categorical data does not have an order. For example, taxpayer status doesn't really have an order, as taxpayers may get divorced, remarry, or otherwise change their statuses at any time. Categorical data without an order is called nominal data.
However, you may find that in certain cases, this data does have an explicit and enforceable order. For example, the responses to a standard survey question often do: e.g. strongly disagree, disagree, neutral, agree, strongly agree. Categorical data that does have an order is called ordinal data.
Both ordinal and nominal data columns are considered categorical because they exhibit the key defining trait: there is a predefined set of category values.
Creating Synthetic Categorical Data
Once we understand the definition of categorical data, we can see how synthetic data software – such as the SDV – can create it. This type of software uses machine learning to learn patterns in the real data and then emulate them as it creates new, synthetic data. This is shown below with the taxpayer dataset.
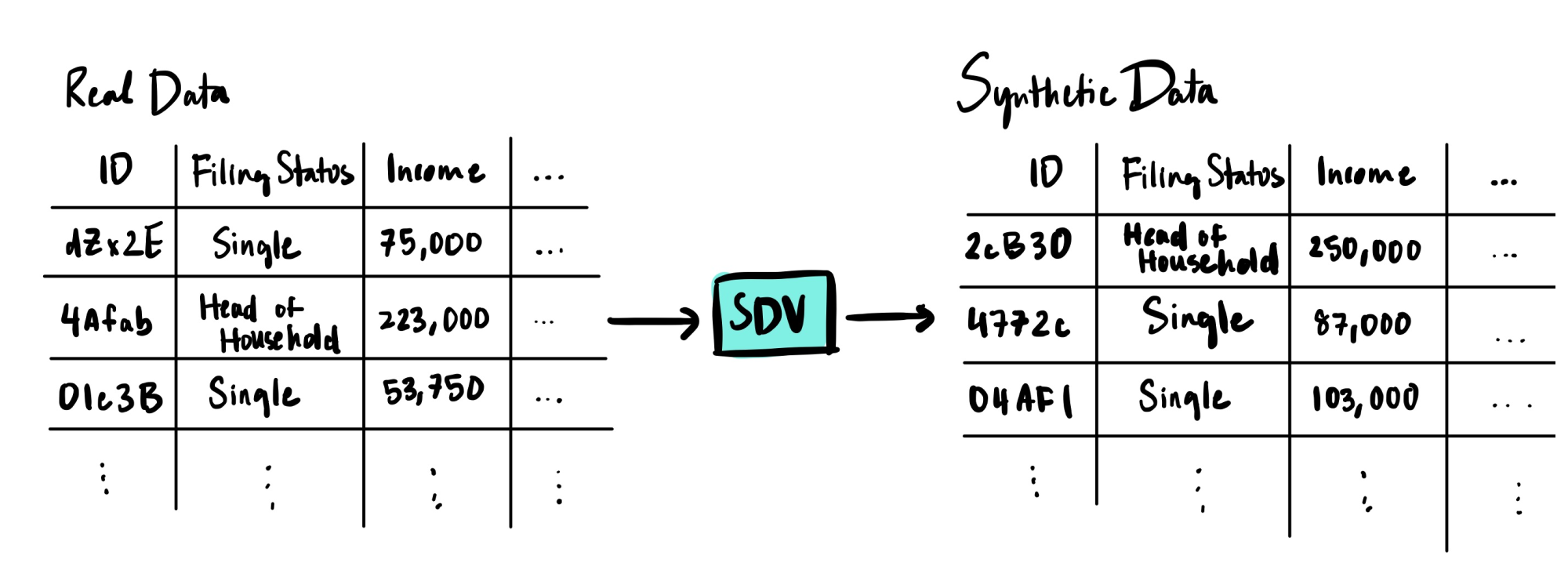
Our illustration shows what the SDV learns and creates:
- The predefined categories. All synthetic data that the SDV creates belongs to a predefined category value. The SDV does not create new category values.
- The frequency of each category value. There are twice as many "single" taxpayers as there are "head of household" taxpayers
- Relationships between a category value and other data. A "single" taxpayer general has a lower income than a "head of household."
Because categorical values must come from a predefined set of values, the SDV can fully learn these relationships.
Is your data categorical? By now, you should have a clearer understanding of what categorical data is, and how the SDV incorporates it into synthetic data. However, it may still be tricky to identify exactly which columns in your dataset are categorical. In these next sections, we'll go through some common traps of misunderstanding — and how to avoid them.
Trap #1: Assuming all strings are categorical
The most frequent mistake we see people making is assuming that every column stored as a computer string (aka text) must be categorical, as though the computer representation exactly corresponds to an sdtype.
Going back to our example of the taxpayer dataset, you may identify several columns where data is represented as strings – for example, tax filing status and address. But just because they are strings does not mean they are categorical.
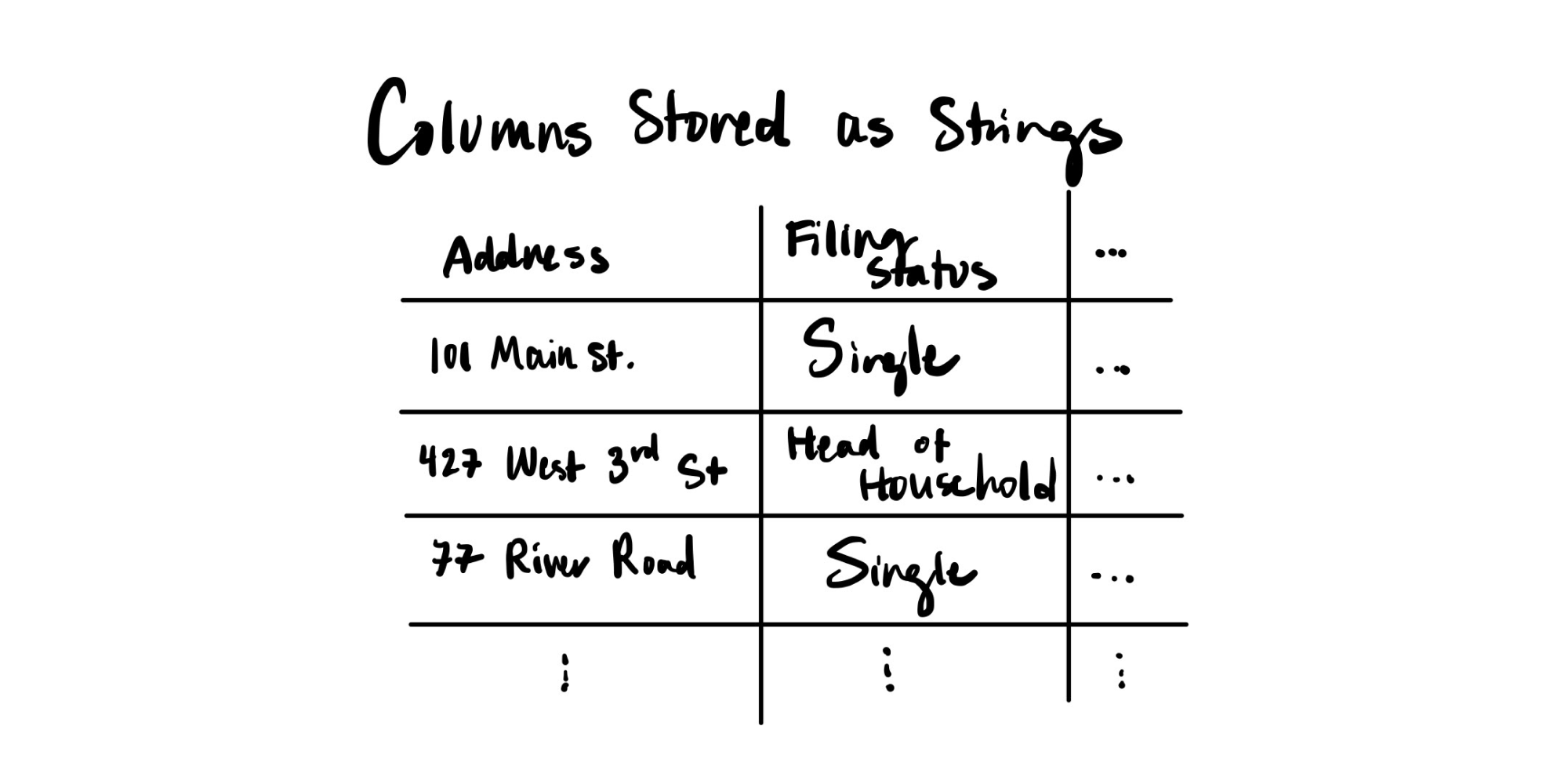
When you're looking at string columns, a key question you can ask is: Do I expect the synthetic data to contain the exact same set of values as the real data? Your answer can guide you to the correct sdtype –
Answer = Yes. For columns such as tax filing status, it is obvious that there is a predefined set of category values. This data is categorical.
Answer = No. For other columns such as address, you do not want the synthetic data to contain the same exact set of values as the real data, due to privacy. In this case, your data is not categorical — instead, it is sensitive or personally identifiable information (PII). The SDV includes special sdtypes for these, which we'll cover in future articles.
Trap #2: Assuming numbers cannot be categorical
The second trap is assuming that numbers (especially integers) cannot be categorical. This follows the same reasoning as trap #1, assuming that the computer representation is indicative of the sdtype.
In our taxpayer dataset, there may be multiple columns where data is represented as numbers – for example, the user's income, ethnicity and phone numbers. Even though the data appears as numbers, it may still be categorical.
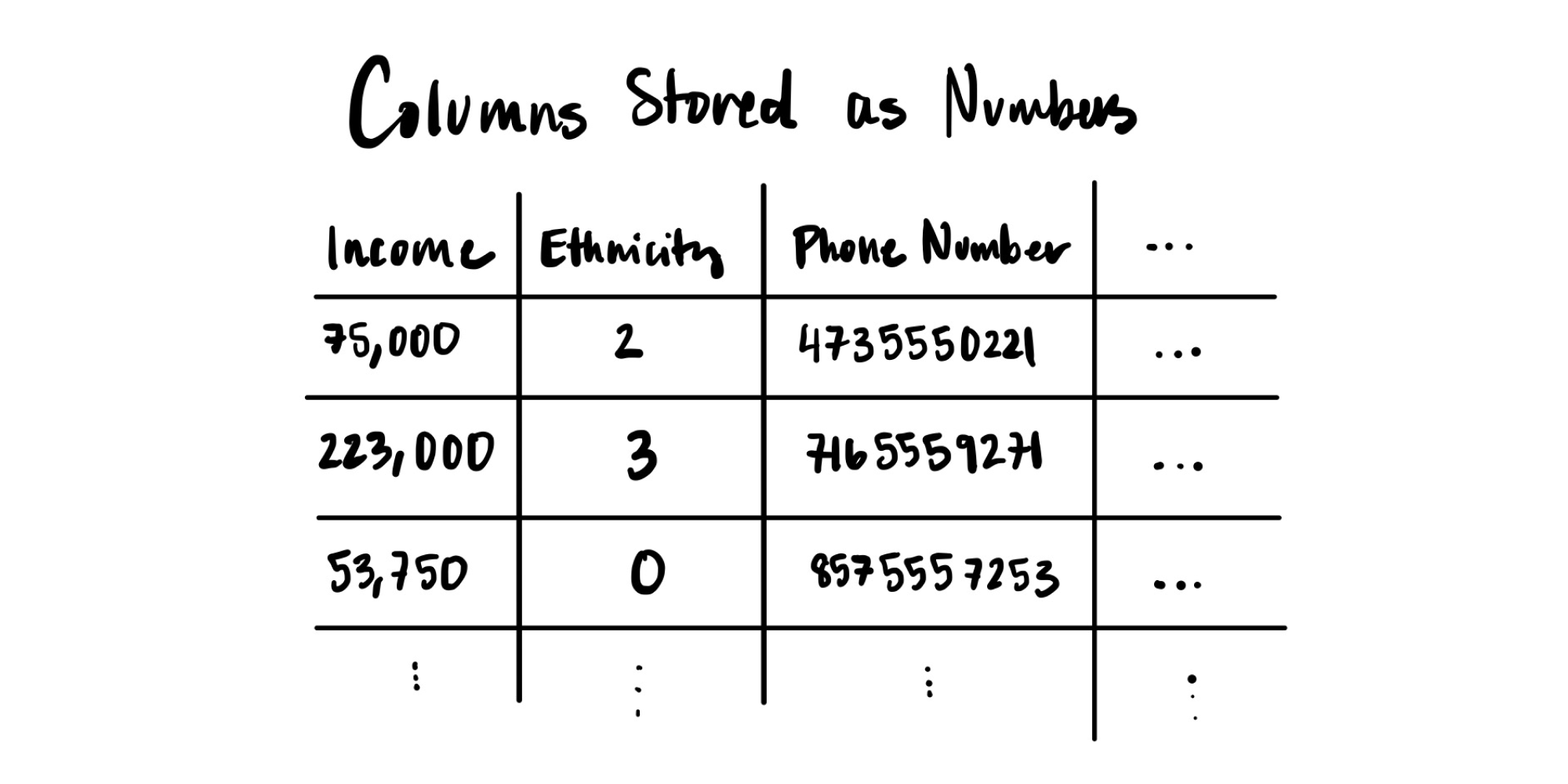
When you encounter this kind of data, it can be clarifying to ask the question: Would it make sense to analyze the numbers through statistical operations such as finding the sum, average or maximum? As before, your answer can illuminate the type of data you are working with –
Answer = Yes. For columns such as income, it makes sense – and is even recommended – to analyze the numbers through statistical operations like averaging. In this case, you have numerical data.
Answer = No. For other columns such as phone numbers or ethnicity, analyzing the numbers is not relevant. (For instance, it's meaningless to talk about the "average" of several ethnicities, or a "minimum" phone number.) If this is the case, you are likely dealing with either PII or categorical data. One way to test this is to go back to our original definition of categorical data: Is there a predefined set of values that we want to repeat? Since phone numbers are sensitive information that should not be repeated, we can identify this as PII data.
Ethnicity, however, seems to be categorical because there are a defined set of values. A tell-tale sign is that the numbers are encoding other concepts. In this case, you may need a reference guide to understand the meaning of the integer, as illustrated below.

Trap #3: Misunderstanding ID columns
The final trap involves general confusion about how to specify an ID column. Usually, an ID column will have high cardinality – that is, a large number of possible values. But depending on your exact goals for creating synthetic data, you may actually find that your ID columns should be categorical.
For example, in our taxpayer dataset, we have more than one ID column, as shown below.
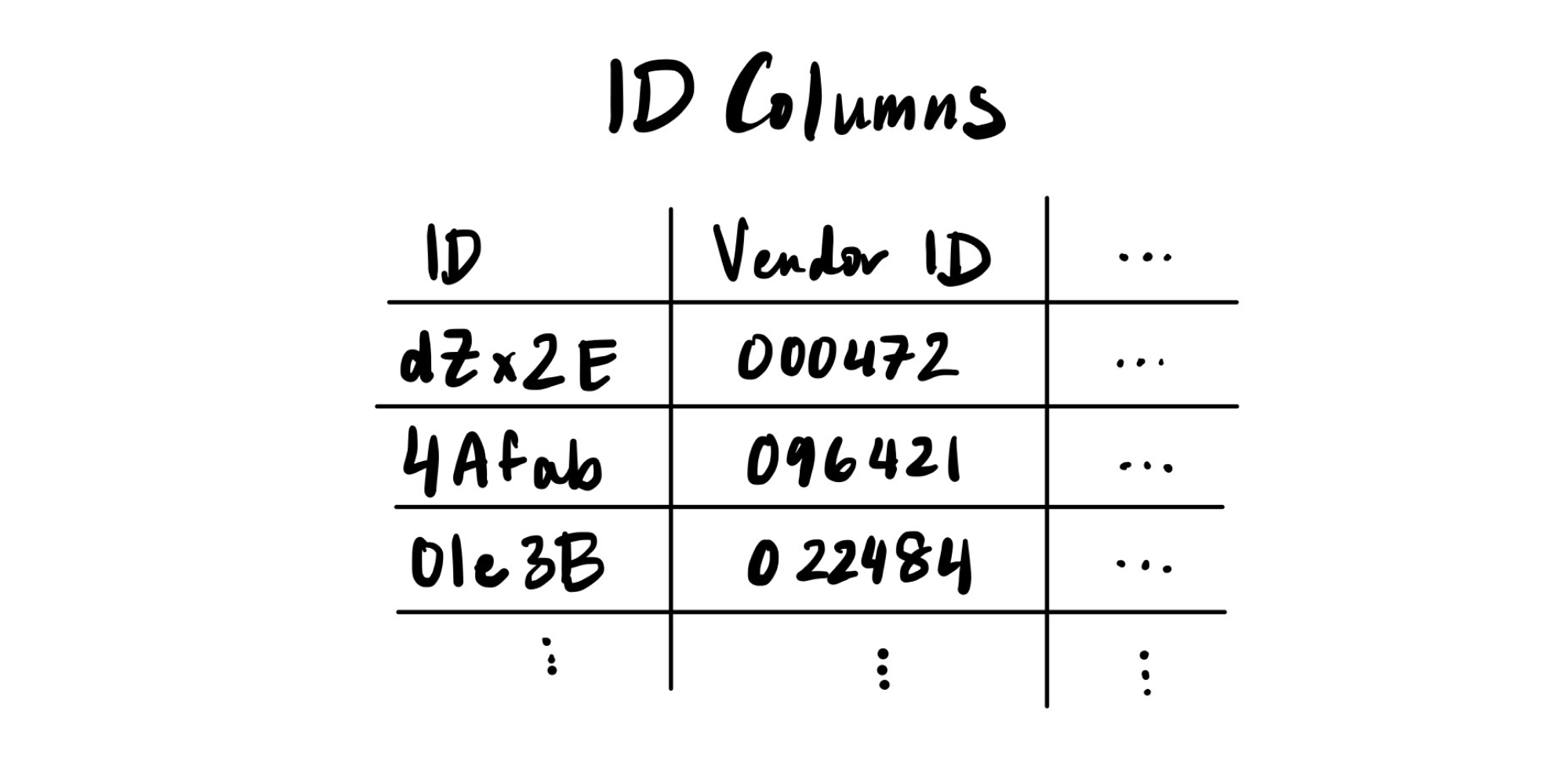
For the purposes of this example, let's say we want to create a synthetic dataset that contains entirely new, synthetic taxpayers. When specifying the data type for each column, we ask ourselves a clarifying question: Do we want to create entirely new, synthetic entities that are different from the original
Answer = Yes. In this case, the column is not categorical. For instance, in our example, the ID column identifies different taxpayers. Since our goal is to create entirely new, synthetic taxpayers, the ID column cannot be categorical. In this case, the column is instead a primary key, because it contains a unique reference per row.
Answer = No. Other columns might be categorical. In our example, the Vendor ID column identifies vendors that help file taxes. We do not want to create entirely new, synthetic vendors — instead, we want to create synthetic taxpayers and assign them to existing vendors. So for our purposes, the Vendor ID column is categorical, because we want to reuse the existing values (along with the patterns that we've learned about them).
This final point is tricky, as your answer may change based on the project. For a different usage, you may want to create new, synthetic vendors. In this case, you'd need to supply a separate Vendor table and mark the Vendor ID as a foreign key reference, instead of categorical.
(Does this concept make sense? The SDV team is still iterating on this particular point, and our understanding may change based on your feedback. Leave us a comment below if you've been confused by ID columns.)
Takeaways
In this article, we summarized the key definition of categorical data: Data that has a predefined set of possible values. Even with this definition, it can be tricky to decide whether a particular column is categorical, so we provided some clarification for 3 common points of confusion:
- Categorical values will be created in the synthetic data exactly as they are in the real data. If you'd like to create new values for privacy reasons, you may be dealing with PII data instead.
- Categorical values may be represented as numbers (integers). If applying standard mathematical operations (min, max, average) doesn't make sense for the data, or if you need a reference guide to understand the full meaning of the integers, you are probably dealing with categorical data.
- Categorical values may have high cardinality in the form of ID columns. If you don't want to create any new, synthetic entities using those IDs, then the column is categorical for the purposes of your synthetic data project.
Are there any other cases where categorical data comes up? Let us know in the comments below!