The SDV uses machine learning (ML) to automatically learn rules (aka correlations) from real data and generate accurate synthetic data. While these models are powerful, they may not learn everything. In our previous article, we described how the SDV models may not learn deterministic rules. These are patterns and laws that are inherent to the dataset:
- They are unchangeable, no matter what data you input.
- They describe rules that must apply to every row, no exceptions.
Luckily, it's possible for you to improve the machine learning model: When you input constraints, it ensures the model will learn deterministic rules and ultimately improve the quality of your synthetic data.
In this article, we'll dive into the technical details of how you can apply constraints and how they work under-the-hood. You can also follow along in our notebook.
!pip install sdv==0.13.0import numpy as np
import warnings
warnings.filterwarnings('ignore')The Dataset
The dataset we're using comes from a Kaggle Competition hosted by Expedia. We've modified the data slightly for our use.
from sdv.demo import load_tabular_demo
data = load_tabular_demo('expedia_hotel_logs')In this real-world dataset, each row represents a search result for a hotel booking.
For the purposes of this notebook, we'll drop some columns that aren't useful to us.
import pandas as pd
# Drop some columns that aren't useful for this demo
drop_columns = ['date_time', 'user_location_country', 'user_location_region',
'user_location_city', 'user_id', 'srch_destination_id',
'hotel_country', 'hotel_market', 'hotel_cluster',
'srch_destination_type_id', 'orig_destination_distance',
'posa_continent', 'site_name', 'channel']
data = data.drop(drop_columns, axis=1)
# make sure these columns are read as datetimes
for col in ['srch_ci', 'srch_co']:
data[col] = pd.to_datetime(data[col])
# Inspect the data
data.head()
The search parameters, for finding a hotel room, saved in this dataset come from from user's input. For example:
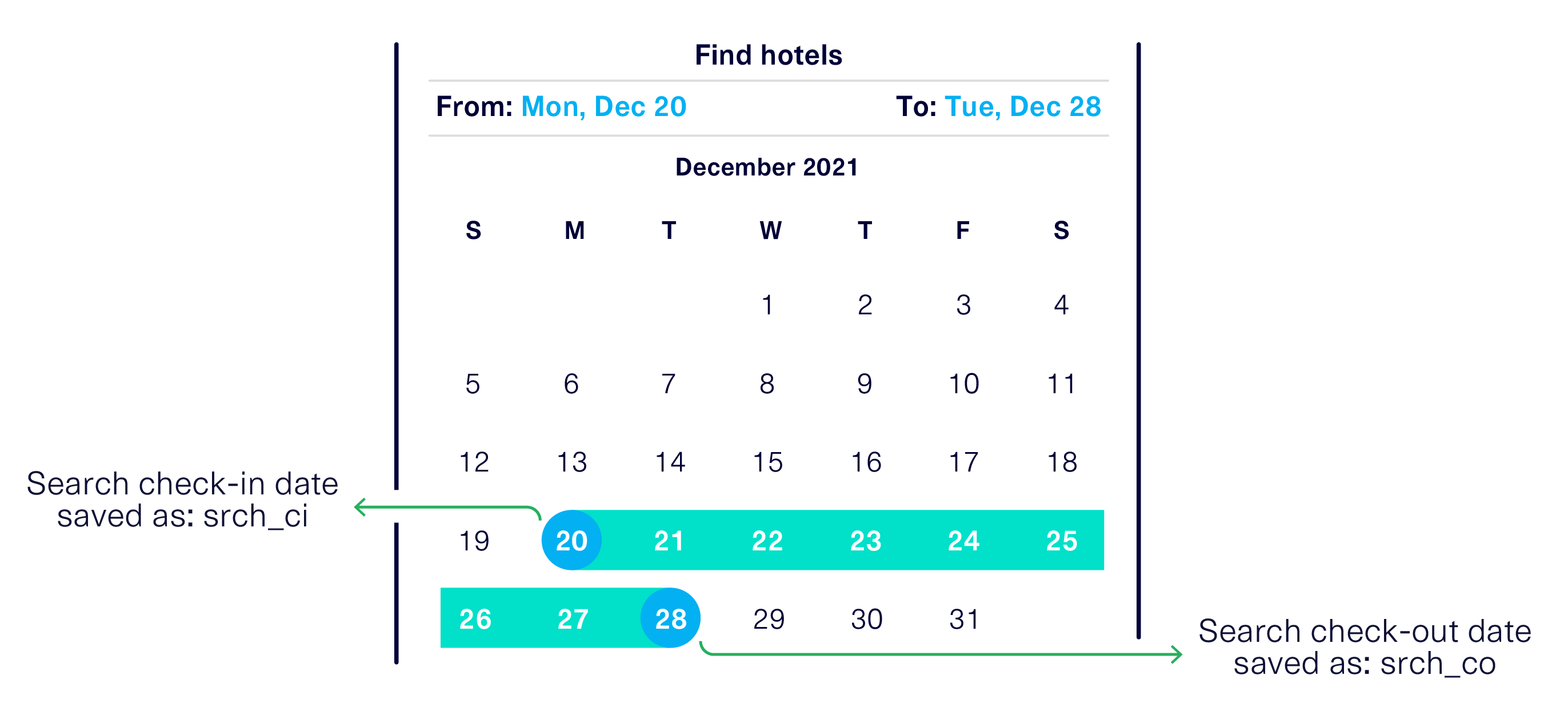
Deterministic Rule
In order for the search to be valid, the searched check-in date must happen before the searched check-out date. That is: srch_ci < srch_co.
This is an inherent property of any search, not just for this particular dataset -- we call this a deterministic rule. We can verify if this is true by checking for any exceptions.
print('Violations of the deterministic rule')
len(data[data['srch_ci'] > data['srch_co']])0Will SDV's machine learning model learn this out of the box?
To test this, let's use SDV to learn a GaussianCopula model from the data and sample synthetic data.
from sdv.tabular import GaussianCopula
np.random.seed(0)
model = GaussianCopula(primary_key='log_id')
model.fit(data)
synth_data = model.sample(500)
synth_data.head()
Now, we can inspect the synthetic data to see if there are any invalid rows.
invalid_row_indices = synth_data['srch_ci'] > synth_data['srch_co']
invalid_rows = synth_data[invalid_row_indices]
num_invalid = len(invalid_rows)
perc_invalid = num_invalid / len(synth_data) * 100
print('Number of invalid rows:', num_invalid, '(', round(perc_invalid, 2), '%)')
invalid_rows.head()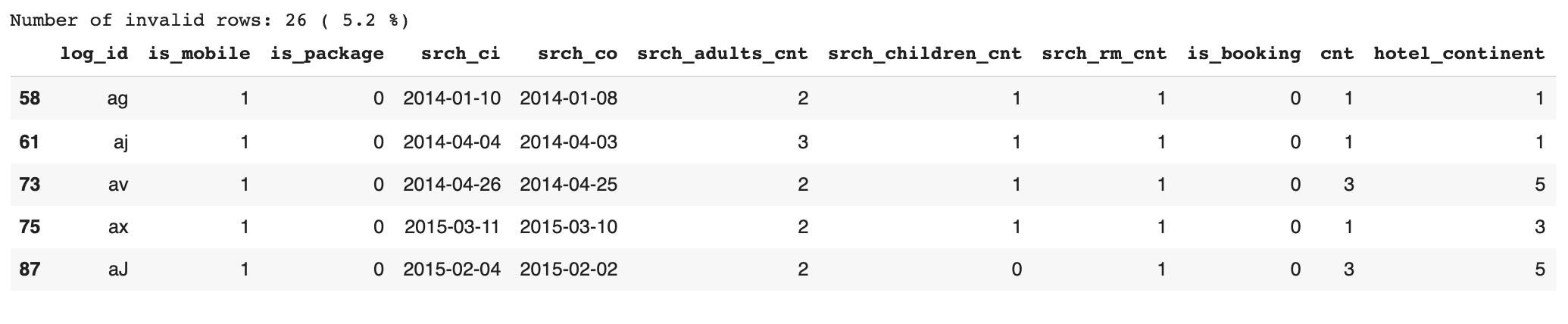
The majority of the rows (94.8%) are valid, meaning the model learned the rule pretty accurately. It learned probabilistically that if the srch_ci is higher srch_co should be even higher. However, some invalid rows (~5%) are still created so the model did not learn this deterministic rule.
This raises the question: What can we do to enforce a deterministic rule?
Improving the synthetic data
Let's explore some options for enforcing our deterministic rule in order to improve the overall quality of the synthetic data.
Rejecting invalid data
The simplest solution is to simply drop the invalid rows, and continually sample from the model until the desired amount of valid rows are produced. We call this reject sampling.
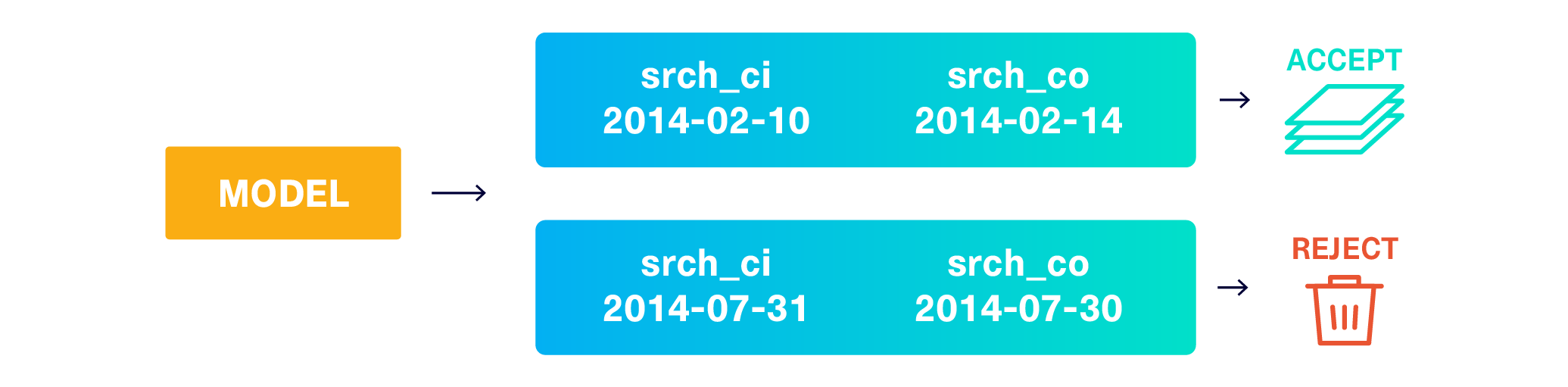
The code below performs reject sampling until we have synthesized 500 rows.
import pandas as pd
# Keep track of how many valid rows we've sampled
num_valid_rows = synth_data.shape[0] - invalid_rows.shape[0]
while num_valid_rows < 500:
# Reject the invalid data
synth_data = synth_data.drop(invalid_rows.index)
# Create new data to replace the invalid data
new_data = model.sample(500-num_valid_rows)
synth_data = pd.concat([synth_data, new_data])
invalid_rows = synth_data[synth_data['srch_ci'] > synth_data['srch_co']]
num_valid_rows = synth_data.shape[0] - invalid_rows.shape[0]
synth_data.reset_index(drop=True, inplace=True)Now, there are no invalid rows in our dataset.
invalid_rows = synth_data[synth_data['srch_ci'] > synth_data['srch_co']]
invalid_rows.shape[0]0In this example, we got lucky. Only a small percentage of the rows were invalid each time sample was called.
What would happen if majority of the rows were invalid every time we sampled? It would take a longer time to get all the desired rows. Sampling time is the primary drawback of reject sampling. Is there another approach we can use to improve the time?
Transforming your data
Instead of reject sampling, what if the model never produced invalid rows in the first place? To achieve this, we can alter the input data to the model so it's forced to learn the constraint.
Let's stop giving the srch_ci and srch_co to the model. Instead, let's teach the model to learn the srch_ci and the difference between the dates.
difference = srch_co - srch_ciThe model will produce srch_ci and difference as a result. Then, we can re-compute srch_co with the opposite formula.
srch_co = srch_ci + difference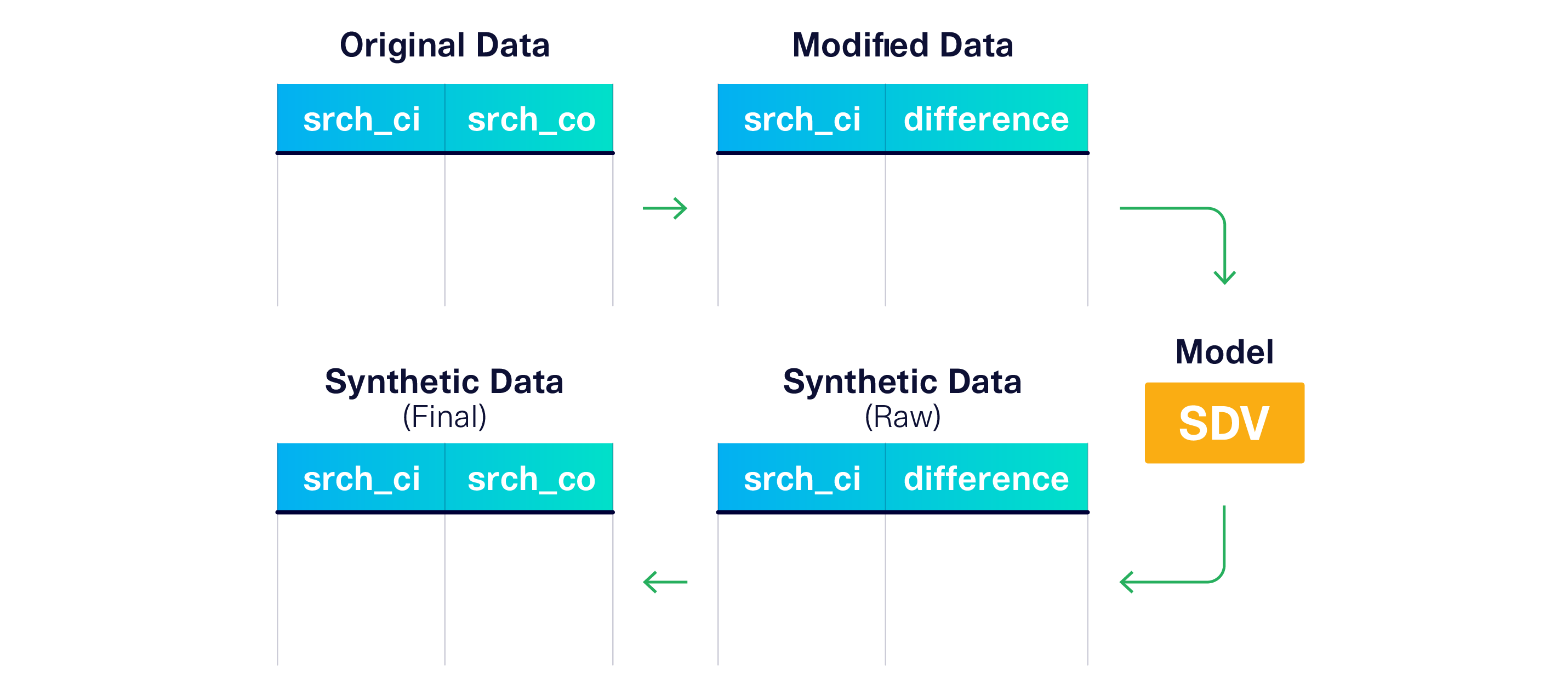
(Of course, we need to make sure the difference is always positive, which we can do using a log + 1.)
Let's see this in action.
# Compute the difference
diff = (data['srch_co'] - data['srch_ci']).astype('timedelta64[D]')
# Take the log and add one to ensure that it's positive
date_diff = np.log(diff + 1)
# The model should learn this column instead of the checkout date
modified_data = data.drop('srch_co', axis=1)
modified_data['difference'] = date_diff
modified_data[['srch_ci', 'difference']].head()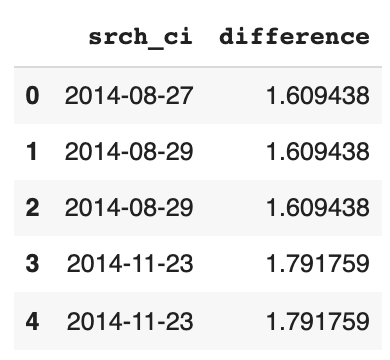
Now, we can fit the model with the modified data. The new samples will include the srch_ci and date_diff columns.
np.random.seed(20)
modified_model = GaussianCopula(primary_key='log_id')
modified_model.fit(modified_data)
modified_synth_data = modified_model.sample(500)
modified_synth_data[['srch_ci', 'difference']].head()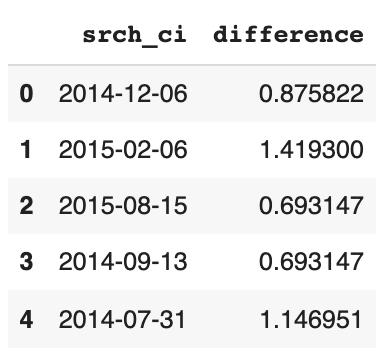
We can recompute the srch_co based on srch_ci and difference.
# Undo the log+1 that we added
diff = (np.exp(modified_synth_data['difference'].values).round() - 1).clip(0).astype('timedelta64[ns]')
# Reconstruct the end_date and remove the date_diff column
modified_synth_data['srch_co'] = modified_synth_data['srch_ci'] + diff
modified_synth_data = modified_synth_data.drop('difference', axis=1)
modified_synth_data.head()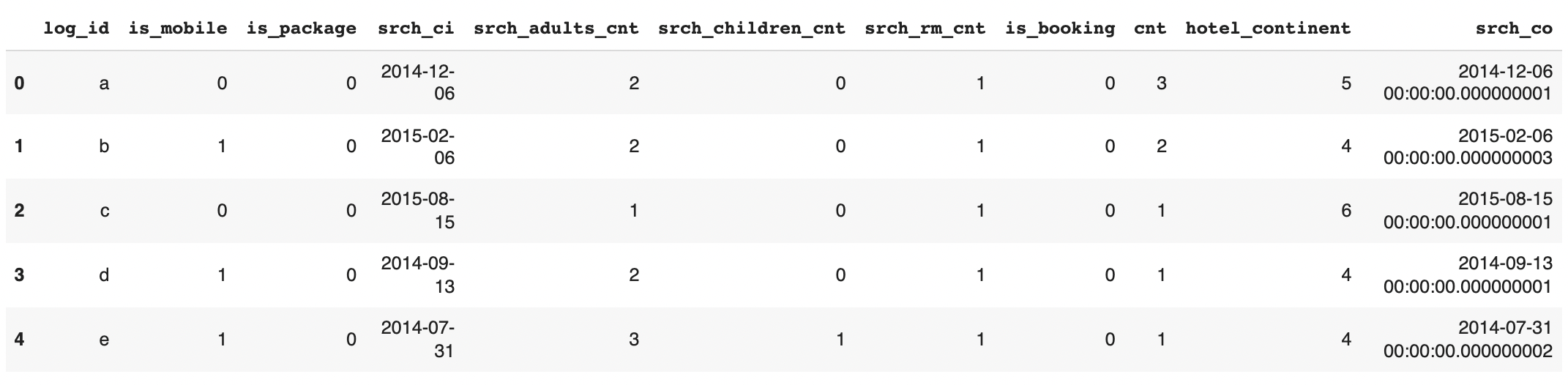
Let's verify that this computation does not create any invalid rows.
invalid_rows = modified_synth_data[modified_synth_data['srch_ci'] > modified_synth_data['srch_co']]
invalid_rows.shape[0]0The transformation worked! In our case, this was a more efficient way to enforce the deterministic rule.
But if our rule were more complex -- and we couldn't think of a transformation -- we could always fall back to reject sampling.
Inputting deterministic rules in the SDV
We've seen how reject sampling and transform can be used to improve the quality of the synthetic data by accounting for deterministic rules. However, it may be cumbersome for you to manually implement these strategies. In fact, we saw some common problems in our SDV user community:
- Users had multiple deterministic rules in their dataset. For example, there could be multiple comparisons between different pairs of columns.
- Users from multiple domains often had the same kind of deterministic rule. For example, one column being greater than another is a common deterministic rule, agonistic of a use case or domain.
To solve these problems, we introduced a constraints module in the SDV. With the constraints module, SDV users can easily input deterministic rules. Let's look at an example.
Using the SDV constraints module
The constraints module in the SDV contains several different types of pre-defined deterministic rules.
We will use the GreaterThan constraint, which will enforce that one column's values are always greater than another's.
from sdv.constraints import GreaterThanNext, we can input the logic of our deterministic rule by creating a constraint object. The GreaterThan constraint accepts the column names as input.
gt_constraint = GreaterThan(
low='srch_ci',
high='srch_co')Finally, we can input this constraint when instantiating the model.
np.random.seed(10)
# Apply the constraint to the model
model_with_constraint = GaussianCopula(
primary_key='log_id',
constraints=[gt_constraint])
model_with_constraint.fit(data)
# Sample synthetic data
constrained_data = model_with_constraint.sample(500)
constrained_data.head()
As a result, we should see that all 500 generated rows are valid on the first try. No invalid rows are present in our dataset.
invalid_rows = constrained_data[constrained_data['srch_ci'] > constrained_data['srch_co']]
invalid_rows.shape[0]0Using the SDV was much simpler than writing the code ourselves! Plus, we can create multiple constraints for the same dataset an easily use them on other datasets.
Specifying the strategy in the constraints module
By default, the GreaterThan constraint uses the transform strategy. However, you can use the handling_strategy argument to control this. This argument accepts 'reject_sampling' or 'transform' as valid strategies.
gt_reject_constraint = GreaterThan(
low='srch_ci',
high='srch_co',
handling_strategy='reject_sampling' # specify the strategy
)Similar to before, we can then input this constraint into the model.
np.random.seed(30)
# Apply the constraint to the model
model_with_reject_constraint = GaussianCopula(
primary_key='log_id',
constraints=[gt_reject_constraint])
model_with_reject_constraint.fit(data)
# Sample synthetic data
constrained_reject_data = model_with_reject_constraint.sample(500)
constrained_reject_data.head()
invalid_rows = constrained_reject_data[constrained_reject_data['srch_ci'] > constrained_reject_data['srch_co']
invalid_rows.shape[0]0What other deterministic rules are already available in SDV?
The GreaterThan constraint is one kind of deterministic rule, but there may be others that apply to your dataset. The SDV offers more constraints for other types of logic.
- Unique when values in a column must be unique to the entire dataset.
- UniqueCombinations to limit the permutations between multiple columns.
- Positive and Negative to enforce boundaries.
- ColumnFormula when there is a formulaic association between columns.
- Rounding to enforce decimal precision.
- Between when one column's values must be between 2 other values.
- OneHotEncoding when your data includes a variable with one hot encoding.
For each of them, you can specify handling strategies for reject_sampling to discard invalid data or transform to modify the data (unique to each constraint).
What if my rule isn't included in the module?
You may come across a rule that cannot be described by any of the constraints classes in the SDV. In this case, you can define a CustomConstraint with logic specific to your use case.
Additionally, consider filing a feature request on GitHub with details about your use case & scenario. We can add your logic as a pre-defined constraint so others can benefit from it too!
Takeaways
In this notebook, we explored what happens when we have a deterministic rule in our dataset.
- Machine learning models may not able to learn the deterministic rules out of the box, but it is possible to improve the model to learn these types of rules.
- Deterministic rules can be handled by discarding invalid data (reject sampling) or by adding some clever preprocessing to your code (transforming).
- The SDV offers a
constraintsmodule that allows you to input commonly found deterministic rules. You can specify the handling strategy for each constraint and apply multiple rules to the same dataset.
Further Reading
For further information about constraints refer to the Handling Constraints User Guide.