Making generative AI for tabular data more transparent, adaptable and controllable for enterprise.
We are excited to announce a major milestone for our flagship software library. This week, we are releasing a newly updated SDV 1.0 library that contains many highly requested features, customization options and easy-to-use APIs.
With over 100 issues filed and resolved, a lot of hard work has gone into this update. As the core developers of the SDV ecosystem, we want to shed some light on this large undertaking: Why did we choose to update the library, and how did we decide which changes to make?
Introducing the Programmable Synthetic Data Stack
When we first started DataCebo in 2021, we had set the goal of using generative AI for tabular synthetic data – but we didn't know if users would find the features or abstractions adequate. In the beginning, users would run into hurdles and we would frequently iterate to address missing features.
Fast forward 2 years, and we have a much better sense of which synthetic data concepts are making a difference to enterprise and community users. These include metadata, preprocessing (using reversible data transformers and constraints), evaluation metrics and transparent, generative models. The ideas made so much sense that even other projects and technologies began adopting them. We realized that it was time to formalize our home-grown concepts into a complete vision of synthetic data creation – and thus, the SDV's programmable synthetic data stack was born!

The stack scaffolds users through a workflow for synthetic data creation, enables introduction of custom logic through easy programmable interfaces. It also provides transparency and ability to control synthetic data generation.
Today we are releasing SDV 1.0 which formalizes all these concepts. Let's go through a few critical principles that guided our vision.
Supporting a 5-Step Synthetic Data Creation Workflow
At its core, the SDV uses machine learning to learn and generate synthetic data. So the very first SDV models included 2 steps that are common to machine learning libraries:
- Training, where we let the machine learning algorithm learn from the real data
- Sampling, where we use the learned patterns to generate new, synthetic data
Although these steps form the core of synthetic data, we've discovered that enterprise deployment requires a more holistic workflow, as illustrated below.
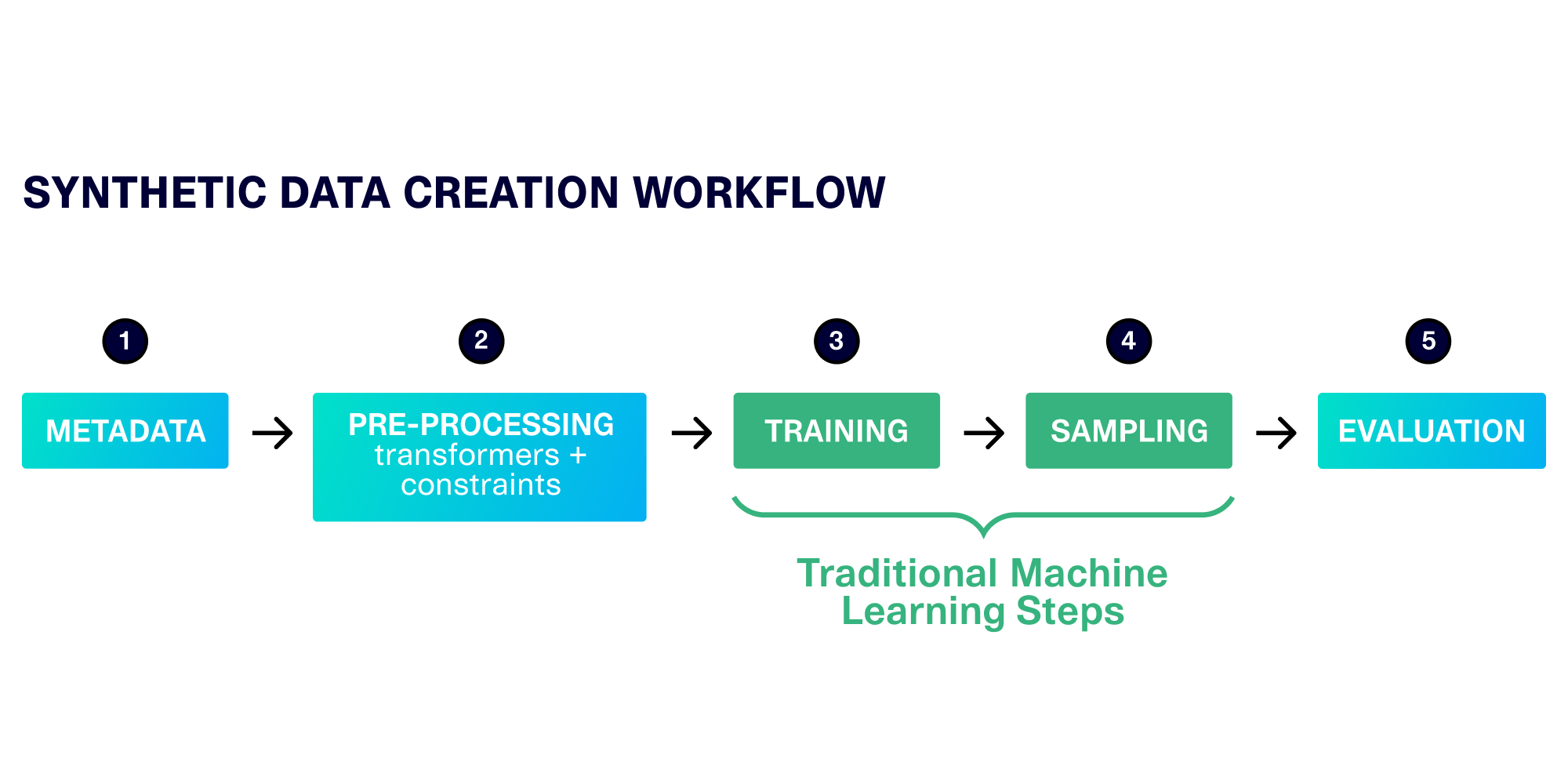
To generate the highest-quality synthetic data, it's important to start with metadata, which accurately describes the types of data in each table and the connections between them. This description helps us during the pre-processing stage, where we transform raw, real-world data into fully numerical data that is ready for machine learning. This is also where we handle constraints (logical business rules).
The training and sampling happen as they would in any machine learning project. Finally, we end with evaluation, where we compare the real and synthetic data across a variety of metrics.
In SDV 1.0, all synthesizers distinctly follow the 5 steps we've detailed. The result is consistent and cohesive usage regardless of the particular machine learning algorithm involved. In SDV 1.0, you can:
⭐️ Automatically detect and modify metadata. Create metadata easily from a CSV file or DataFrame. Easily inspect, visualize and verify that the metadata is correct before using it in a synthesizer.
⭐️ Inspect the steps in your workflow. Pausing at different steps allows you to inspect and understand your synthetic data project. For example, you can inspect the transformations to understand how the data is being processed. You can also retrieve and save the cleaned, numerical data before it's used for machine learning.
⭐️ Run evaluation reports to measure the synthetic data quality. After creating the synthetic data, we integrate fully with the SDMetrics library to generate a quality report, which provides a single, summarized score as well as detailed breakdowns. It's also possible to visualize the data for more insights.
Making Our Framework Adaptable
As with any machine learning project, it's great when the SDV synthesizers work perfectly out of the box for a dataset – with no extra effort needed. But we recognize that an enterprise dataset may have idiosyncrasies that demand extra attention.
We built SDV 1.0 to be more flexible than its predecessor, accommodating the different areas where your input may be needed. The following areas are built into the SDV framework now – allowing for easy input and usage:
⭐️ Provide enriched, semantic data types in your metadata. The data types you have may not neatly fit into a statistical data type (eg. numerical, categorical, datetime). You can now specify a number of complex, semantic data types such as "address" or "phone number."
⭐️ Write logic and apply custom constraints to your synthesizers. If your particular business logic cannot be expressed using the predefined constraints, you can write and use custom logic. SDV 1.0 allows you to express this logic simply using functions, and to apply it in multiple places.
⭐️ Easily plug in different preprocessing transformers. To further improve the quality of your synthetic data, you can now create and supply your own reversible data transformers to use during the preprocessing step. This includes anonymization and pseudo-anonymization.
Providing Increased Transparency & Control
In the earlier version of the SDV, we heavily focused on allowing users to set up the machine learning algorithm by borrowing concepts from data science. We've learned over the years that the typical synthetic data user may not necessarily be an expert in machine learning concepts. It's more important for the SDV to clearly communicate ideas and show what the synthesizers are doing.
In SDV 1.0, you'll see a number of usability improvements aimed at increasing the transparency and controllability of the synthetic data creation workflow. Some of these include:
⭐️ Easily understand your code with intuitive class and parameter names. We've clearly delineated the core machine learning models from the overall workflow, naming the latter "Synthesizers." We've also adjusted some parameter names to make them more intuitive – even if you're not a machine learning expert.
⭐️ Access parameters that the synthesizers have learned. After processing and machine learning, you can dig in deeper to understand exactly which patterns were extracted from your data. You can access any transformer and inspect its values – for example, accessing mappings used to pseudo-anonymize sensitive data.
⭐️ Control randomization when creating synthetic data. Synthesizers will randomly produce different data every time you sample. However, you can now reset the synthesizer to its original state, allowing you to reproduce those random results.
Try Out the SDV 1.0 Beta!
The SDV 1.0 library is available today in Beta. Check out our new documentation site for more instructions on how to install the library, test it and provide feedback. We've also created a series of demos and tutorials for those who are getting started with synthetic data for the first time (or for anyone who wants to improve their skills).
Happy synthesizing!
- The DataCebo Team