In our previous article, we explored how machine learning (ML) plays a key role in synthetic data creation. One of the biggest strengths of ML is automatic rule detection (also known in ML terms as correlations): The algorithms are designed to learn patterns in the data, even without additional user input. The result is synthetic data that resembles the original, right down to its mathematical properties!
However, in some cases, applying an ML model right out of the box may not immediately achieve the desired result. In this article, we'll explore the strengths of ML models and go through those areas where user input may be required.
Strengths of ML Models
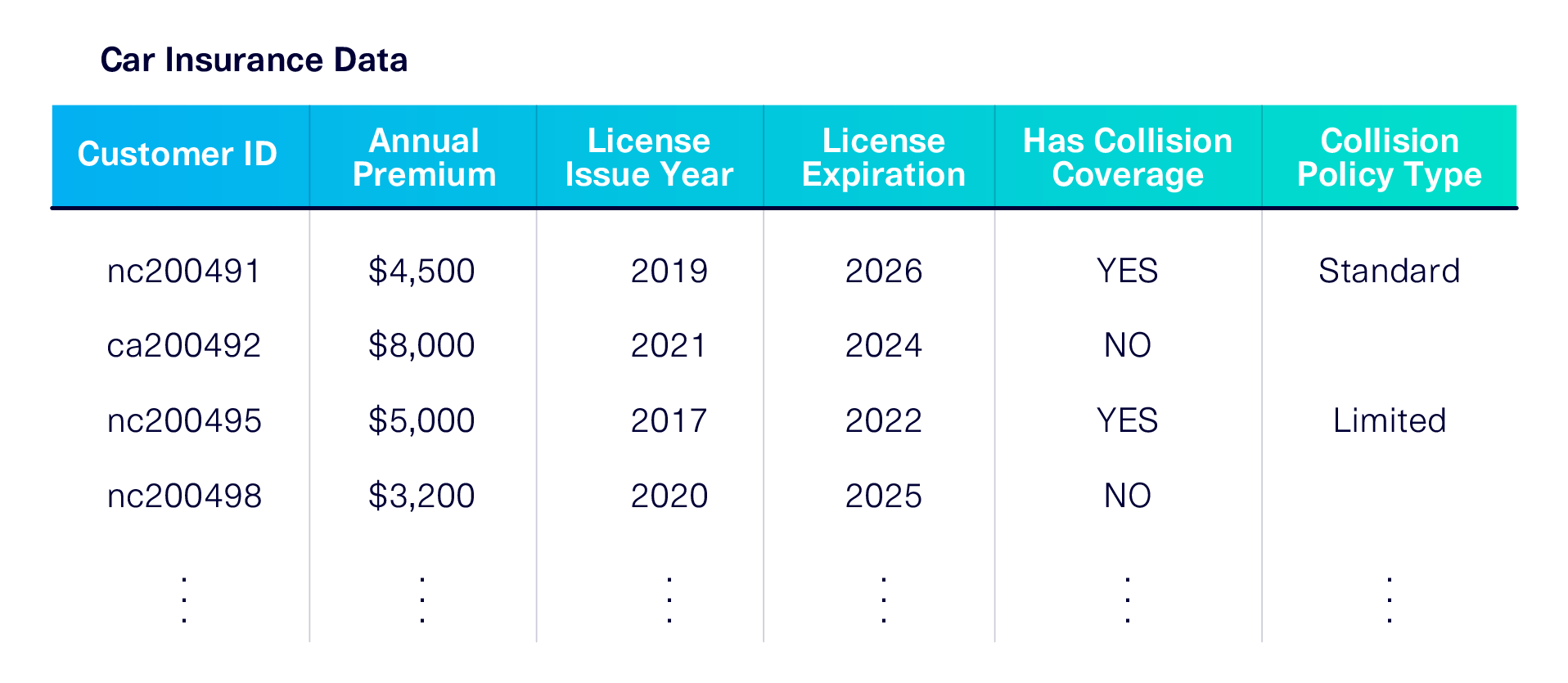
The goal of any ML-based synthetic data generation software is to learn from and emulate the input data. To illustrate this, let's pretend you work in the car insurance business, and you're in possession of a real dataset related to drivers and their insurance:
An ML-based system, such as the Synthetic Data Vault (SDV), will learn patterns from the real data and use it to create new synthetic data. Recall some of the important patterns that ML algorithms detect:
- Shapes. The general shape of the data. For example, in the dataset above, 50% of drivers have Collision Coverage and the Annual Premium is uniformly scattered between $3,000 and $9,000.
- Correlations. The trends within the data. For example, having Collision Coverage -- especially Standard coverage -- means a higher Annual Premium.
These shapes and correlations will be present in the synthetic data that is outputted by the ML model, as shown below.
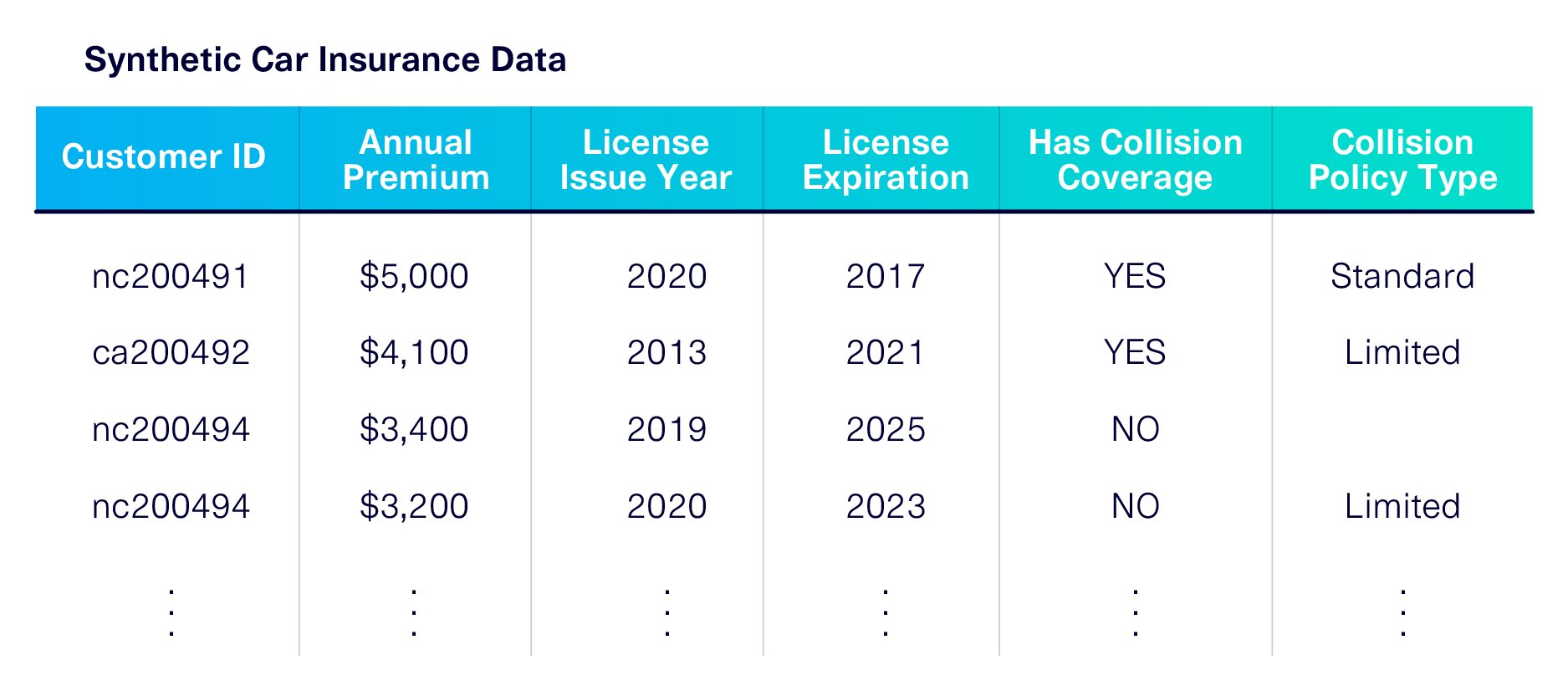
Perhaps the single biggest strength of an ML algorithm is its ability to learn rules by looking for general patterns in the data, using probability and statistics.
What ML models do not learn out of the box
Let's take a closer look at the synthetic car insurance data. You might notice that two of the rows in the synthetic data don't make complete sense. Below, we've highlighted the errors.
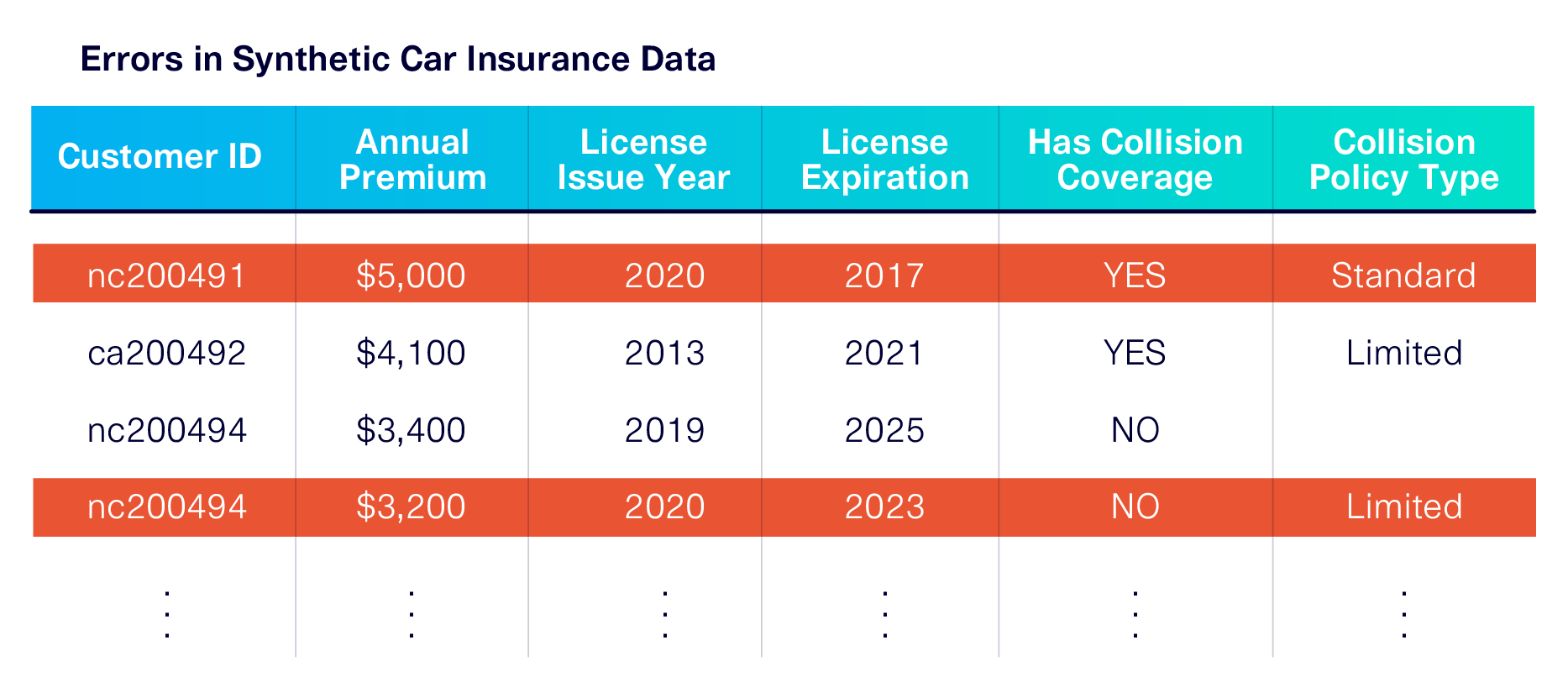
Do you see what has gone wrong? In the first row, the license expired 3 years earlier than it was issued. In the last row, a driver without Collision Coverage has a Collision Policy Type. Additionally, the same Customer ID has been repeated in Row 3 and Row 4.
There are three rules that the ML algorithm did not follow:
- License Expiration > License Issue Year
- If Has Collision Coverage = NO, then Collision Policy Type must be empty
- All Customer IDs must be unique
Why does the ML model easily pick up on some rules and not others? To answer this question, we can look closely at the rules themselves. All of the rules that the ML model successfully learned -- including the distribution shapes and the correlations -- were based on general trends. These probabilistic rules apply to a majority of the relationships within the dataset, but not all of them. Although they have to make sense in aggregate, a few rows may be exceptions.
By contrast, the rules that the ML model failed to learn were stricter. These deterministic rules describe intrinsic laws of nature, time or logic. Each and every row must adhere to them, and they won't change regardless of how much (or how little) data has been given to the ML model.
To continue with the driving theme: A probabilistic rule is like a yield sign, signaling a general recommendation that works out differently for each individual situation -- some cars may need to stop, while others just slow down. Meanwhile, a deterministic rule is like a stop sign, demanding that every single car must come to a full stop.
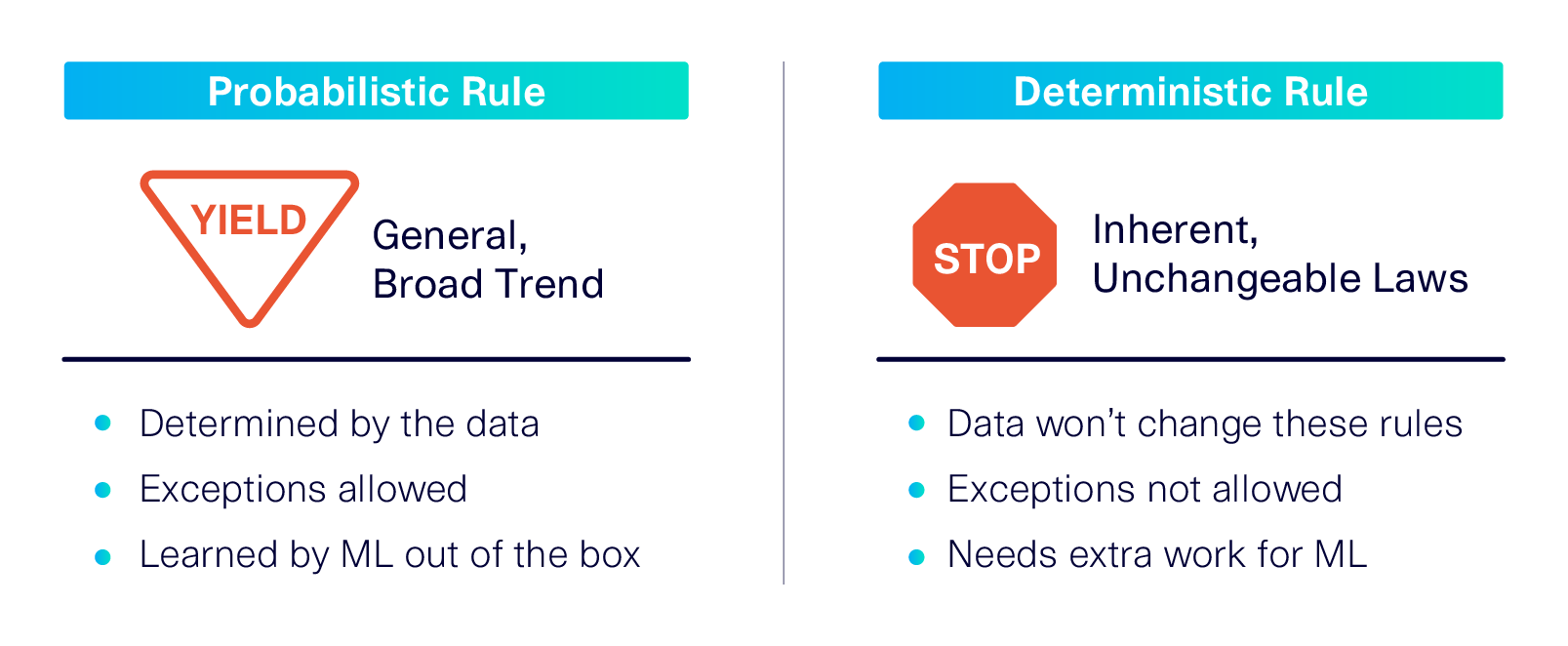
By default, our ML model assumed that all rules were probabilistic. When this happens, synthetic data still generally follows the desired properties -- for example, License Expiration > License Issue Year -- for most of the rows, but not for every row.
Improving the ML Models using constraints
Just because the ML model didn't automatically follow a deterministic rule doesn't mean that it can't. It's possible to improve the model so that it understands this type of rule. As a user working with the SDV, you can input deterministic rules into your model using constraints.
An ML model built using constraints will accommodate both probabilistic and deterministic rules.
Do you need SDV constraints?
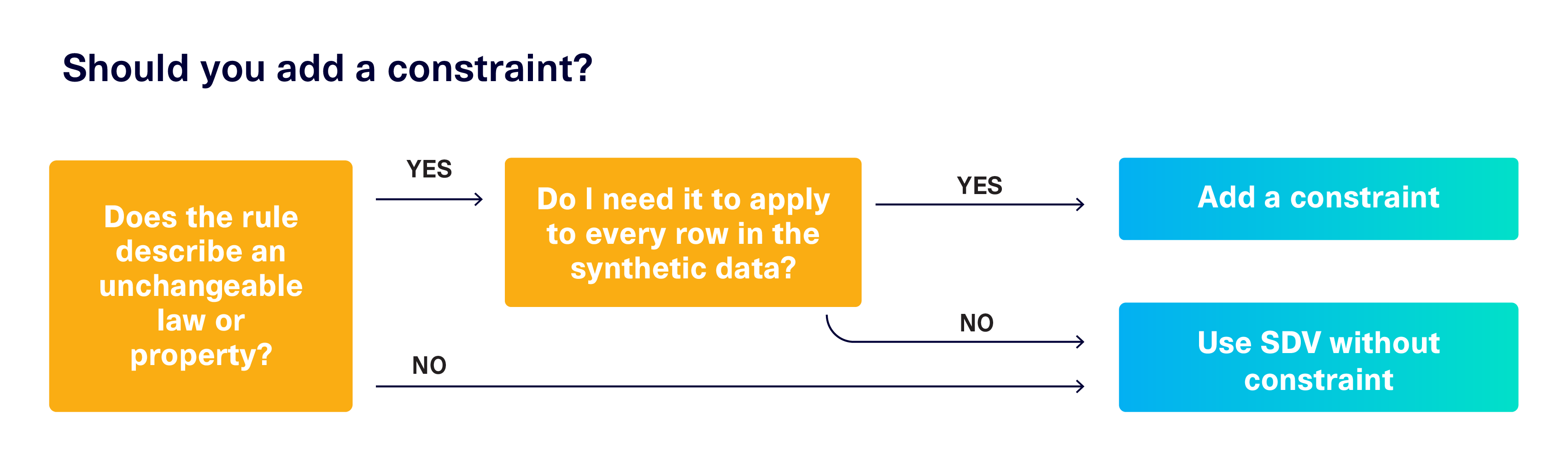
Deterministic rules are often easy to spot in your dataset: They are the rules that every single row must follow in order to be valid, regardless of how much data there is overall. But even if you identify the right constraints, there are some cases where you might not actually want to supply them to the SDV.
Because the SDV learns probabilistic rules, most of the synthesized data is generally valid. Having a few errors sprinkled in might actually be beneficial if you want your synthetic data to cover some edge cases. For example, if you're using the synthetic data to test insurance claim software, leaving in some weird data points might help you ensure that the software can handle unexpected cases -- like the License Expiration accidentally being set too early.
The figure below shows a few questions you can ask to determine whether adding a constraint is the right approach.
The SDV Constraints offering
If you decide that adding deterministic rules is important for generating your synthetic data, the SDV has many different constraints to choose from! The table below describes the constraints you would need in order to define the deterministic rules that would best mold your Car Insurance dataset.

The SDV offers many more possible constraints, including:
- UniqueCombinations
- Positive and Negative
- Rounding
- Between
- OneHotEncoding
You can add multiple constraints to the same dataset in order to accommodate all the deterministic rules you need. For more details, read the Constraints User Guide.
Takeaways
In this article, we learned that:
- Data is governed by rules. The SDV automatically learns probabilistic rules, which describe overall trends or patterns in the data.
- However, sometimes the data has deterministic rules, which are always inherent no matter how much or how little data there is. ML-based systems, including the SDV, may not enforce deterministic rules out of the box.
- Users can input deterministic rules to the SDV using constraints. To figure out whether you should input a constraint, ask yourself whether there are any rules that the data must always follow. There are many constraints to choose from.
In future articles, we'll dive deeper into this topic. We'll explore the technical details behind constraints, and how exactly the SDV's ML models are able to learn deterministic rules.