Neha Patki is the VP of Product and co-founder of DataCebo, where she's revolutionizing Generative AI for enterprises. Before DataCebo, Neha invented the first Generative AI for relational tabular datasets. She was also a product manager at Google, where she managed creator analytics features at YouTube. She studied Computer Science and Artificial Intelligence at MIT.
As co-founders of DataCebo, Kalyan Veeramachaneni and I are excited to announce our first commercial product, SDV Enterprise. SDV Enterprise builds on our popular, publicly available SDV software to provide teams with even better synthetic data more efficiently: SDV Enterprise creates data 100x faster, and achieves 10x the quality.
Kalyan and I created the original SDV at MIT in order to accelerate software development by removing barriers to data access and availability. SDV enables users to train a Generative AI model on relational databases, allowing them to create synthetic data in the same format as their original data, on-demand. We showed how synthetic data can replace real data when developing software, and we released SDV to the public as an open source library. Now, we're taking SDV to the next level with SDV Enterprise.
The Rise of Generative AI: Why tabular data is a special case
Like SDV itself, SDV Enterprise came about when we noticed a need — this time from large enterprises, especially the Global 2000.
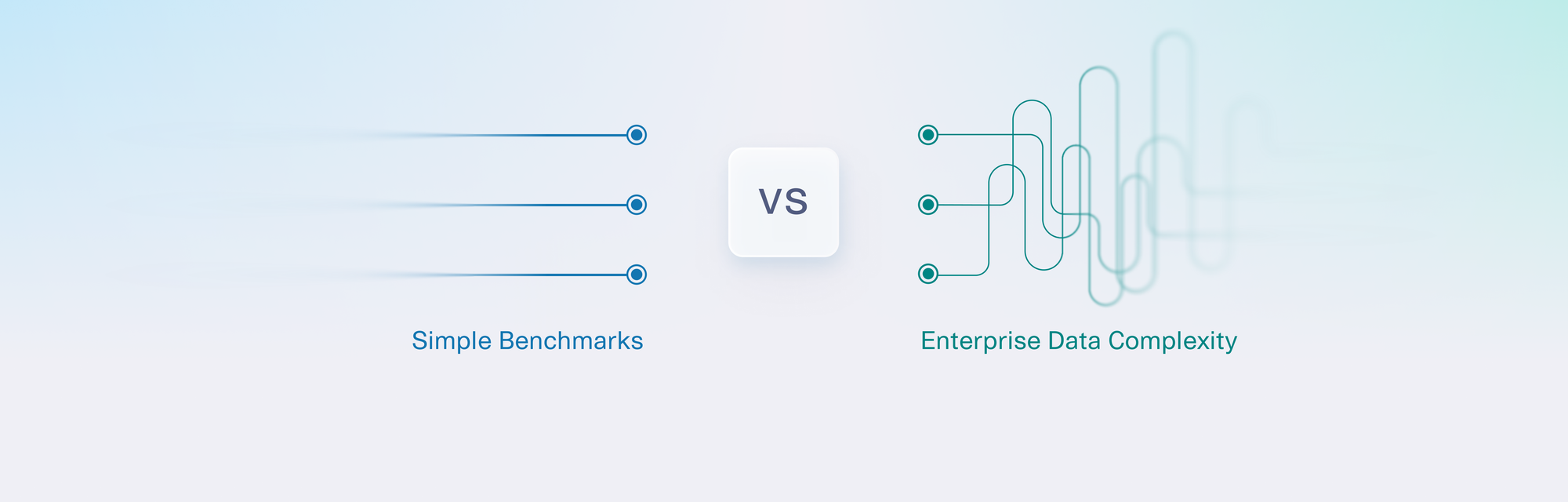
Our work with SDV users showed us that software applications have gotten more data-hungry. While in the past, software may have relied on hard-coded logic and limited test cases, today's applications are more complex, and increasingly use data to make decisions. What's more, these critical enterprise applications need a specific kind of data: tabular data. Tabular data is stored in a structured, tabular format. This data can be most easily visualized as a spreadsheet, with multiple connected tables, rows and columns. SDV is a type of Generative AI that is built specifically for tabular data.
Tabular data is a vital data category, but it's often overlooked. That's because public conversation about Generative AI tends to focus on image and text data created using large language models (LLMs). A single LLM is trained on petabytes of public images and natural language data (training can be cost-intensive, taking over 72,000 GPU-hours). Once trained, the LLM is universal because this type of data is primarily meant for human consumption, and we all read language and understand images in the same way.
Image and language data will always be around, but we find that enterprises need solutions for tabular data too. And unlike with LLMs — which create universally understandable images and language — tabular data is meant for a particular application to use, and its structure is highly specific to an enterprise. It is unlikely that two applications will have the exact same database schema or business logic. In fact, applying an incompatible structure can make the data unusable for a business use case. So for tabular data, users need a Generative AI that is tailored to their application.
SDV allows users to create a private model trained with their data. We designed it to work well even with smaller datasets, making it efficient and cost-effective (SDV Enterprise takes around 15 min to train several GBs of data using only CPUs). Enterprise users can perform this step on-prem, using private production data.
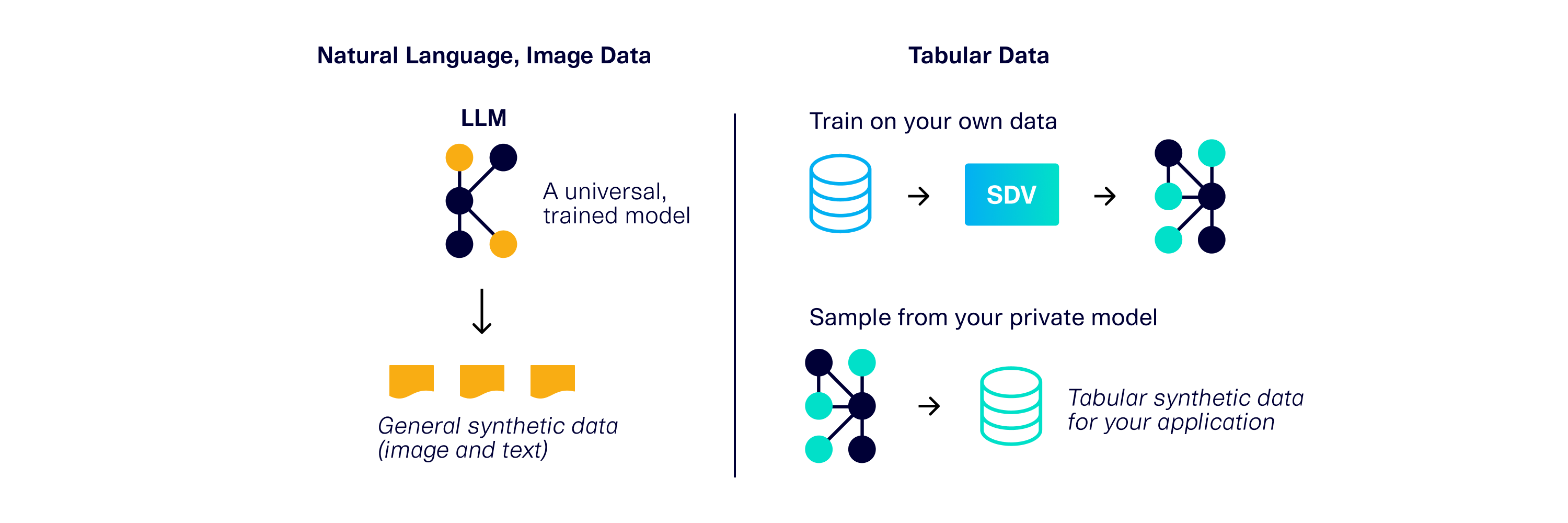
Today, the public SDV has over a million downloads, and thousands of community users who provide feedback. It has become clear to us that tabular Generative AI is a game-changer for software development. Without it, the landscape is siloed: Each team may be accessing data in different ways (manual creation, copying and anonymizing production data, etc.), leading to an error-prone and limited patchwork of approaches. With Generative AI, developers have virtually unlimited access to a variety of data, and enterprises can confidently build robust software.
Productionizing a Generative AI is hard
Our enterprise users tell us that it's easy to build a working proof-of-concept Generative AI using the public SDV. But transitioning to an actual, live application can be a challenge for a variety of reasons.
Enterprise applications have much more complex data patterns. For a pilot, a simple dataset may be sufficient. An enterprise application introduces complexity in two primary areas:
- Data schemas. An enterprise application is likely to contain many more tables and much more interconnectedness. Our enterprise customers report that a typical application contains 5-20 tables of varying configurations, and we know that this number can climb even higher for larger applications that are central components for a business.
- Domain-specific concepts. A demo dataset may contain data that is specially suited for AI — for example, with fully numerical values. An enterprise application often contains more advanced concepts, such as industry-specific codes.
Training a model is an iterative and often collaborative task. The process of training a model includes collecting the data, describing the data's format, and annotating it with special business rules. Our enterprise users have shown us that this is not a one-shot, waterfall process. Many stakeholders are usually involved:
- A database admin or data controller provides access to the training data, which is often coming from production.
- A data owner knows the data schema and any idiosyncrasies, providing valuable annotations about data types and other relevant concepts.
- A developer who will use the synthetic data may have even more information about business rules required by the application.
In our experience, it can take anywhere from 4 to 10 iterations to produce a Generative AI model with input from all these stakeholders.
Once built, a model is rarely single-use. There may be cases where a fixed quantity of synthetic data suffices — but in our experience, developers want to request synthetic data from the model on-demand. SDV also allows users to request synthetic data with specific instructions about which types of scenarios to cover. The challenge is to allow repeated generation while also keeping records for replication and auditing purposes.
Generative AI needs to evolve with the application. Synthetic data is usable by developers if it follows the same format as the real data, and emulates roughly the same mathematical patterns. But the real data – along with the real application – is not fixed in time. As the team adds more features to the application, the schema may change — and as the business continues to grow, the patterns collected in the real data may also drift. For a Generative AI to withstand these external pressures, it must also evolve alongside the application.
SDV Enterprise: A Generative AI solution for enterprise
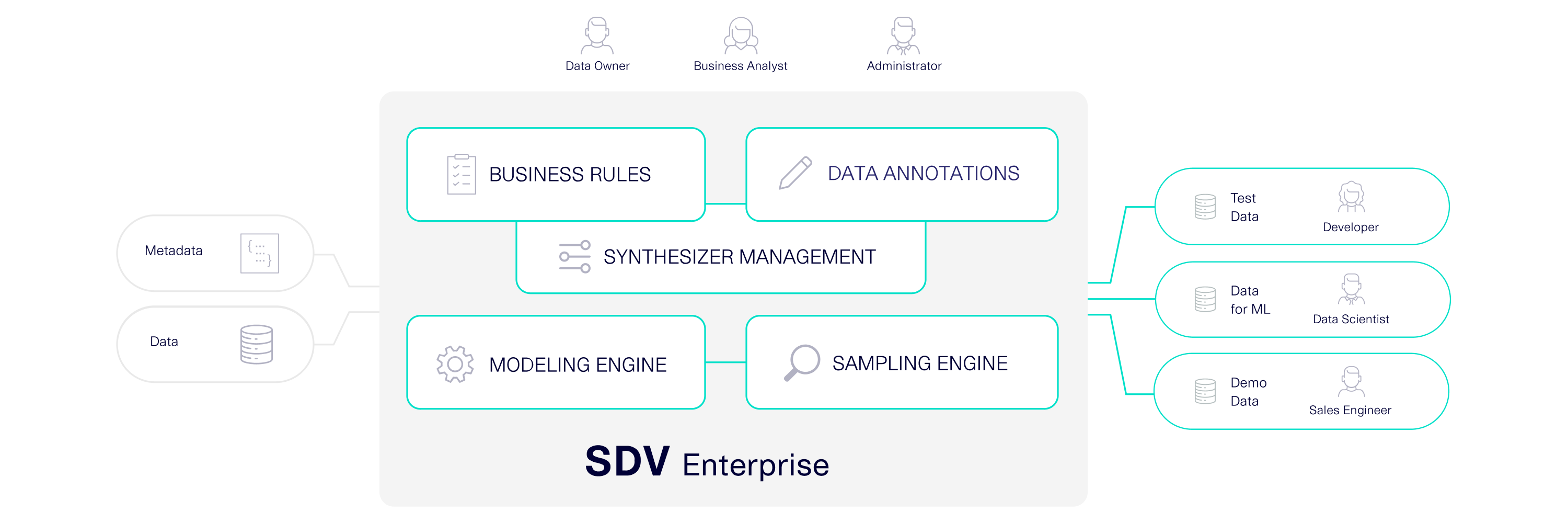
We built SDV Enterprise with the needs of enterprise applications in mind. SDV Enterprise contains the same powerful modeling and sampling engine as the public SDV, but with enhancements for performance and quality. The system is designed for users who want to expand their synthetic data offerings throughout the enterprise, for a variety of stakeholders and downstream uses
SDV Enterprise is built for scalability. Enhancements to the modeling and sampling engines allow enterprise users to model much more complex schemas, potentially with hundreds of interconnected tables. Our team has thoroughly tested the engines on common patterns in database design, including bridge tables, star schemas, and snowflake schemas.
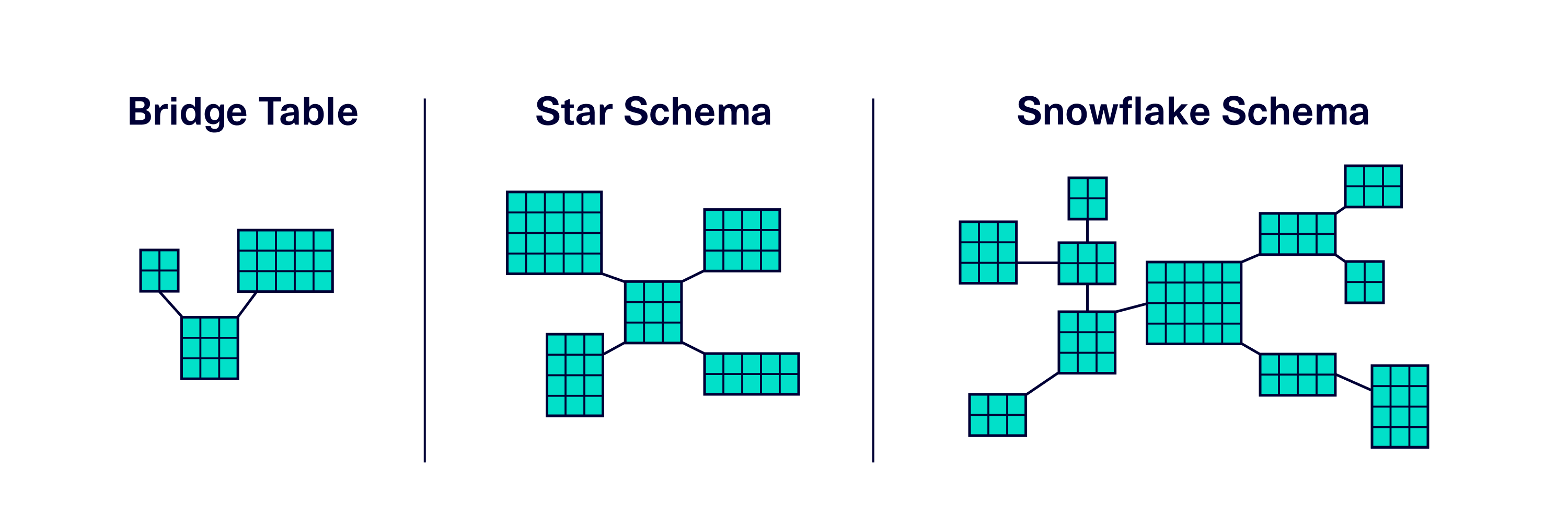
Our early SDV Enterprise customers have also shared their schema designs with us, in which common elements of database design have become elements of a larger application with even more interconnectedness! SDV Enterprise can handle these too.
SDV Enterprise deeply understands data. For human-created concepts and industry-specific terms, SDV Enterprise offers a boost in data quality. It is designed to parse and extract the deeper meaning behind the data, enabling it to create realistic synthetic data that preserves this meaning. For instance, SDV Enterprise knows that:
- Phone number data includes a country and area code. For example, in a number such as +1(617) 253-3400, the +1 indicates that it is a US-based number and the area code (617) indicates that it is from Cambridge, Massachusetts.
- Email data includes a free or commercial domain. For example, an email such as info@datacebo.com includes the domain "datacebo.com", indicating that it is a commercial entity.
- Postal code data varies by country, and within a country, different parts of the code encode a region. For example, "02116" follows the 5-digit format used by the US, and the leading "0" indicates it's from the East Coast. This specific code refers to a region within Boston.
Our team continues to add support for data across domains, from the automotive industry, to finance, to healthcare. Enterprise users observe that synthetic data created by SDV makes sense within the industry context.
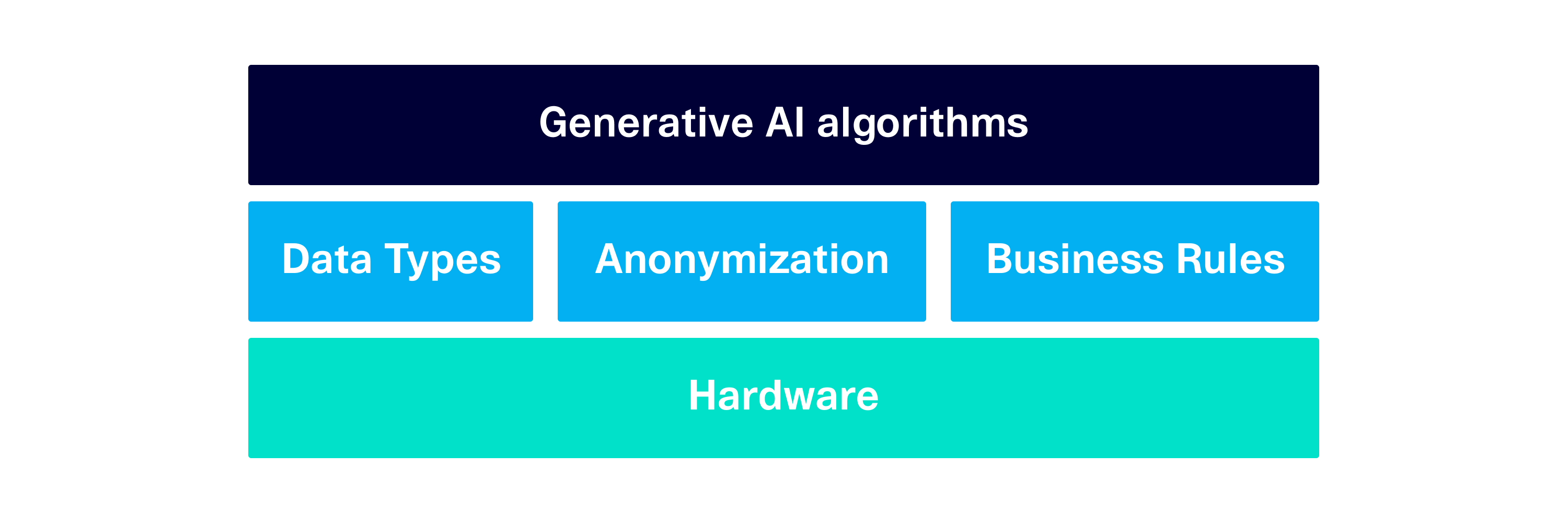
SDV Enterprise is customizable, allowing all stakeholders the opportunity to provide input. The modeling engine features a programmable data stack, allowing customizations for any part of the training process. Using low-code APIs, stakeholders can supply their data schema, anonymization settings, and business rules, and even choose between many different AI algorithms. The software is also designed to run on-prem using CPUs, meaning that it supports a variety of hardware configurations.
SDV Enterprise is built to integrate directly with data sources. Storage of tabular data may vary. Some applications may use popular database management systems such as those provided by Oracle, Microsoft, or IBM. Other times, the data may be stored in a more flexible format, like a Data Lake. With SDV Enterprise, our goal is to integrate with a variety of data sources, making it easier for the modeling engine to ingest training data.
After the sampling engine runs, SDV Enterprise is also designed to export the synthetic data to a desired destination. Usually, teams choose to create a separate synthetic database using the same database management system, producing a synthetic data "clone" of the original database.
SDV Enterprise is an enterprise-wide platform. Most enterprises are made up of multiple teams that could benefit from synthetic data. We envision a centralized SDV system that allows teams to manage their own applications and work together. We are working out capabilities so that each team can:
- Create a new model corresponding to a new application
- Iterate over the model to get stakeholder alignment
- Deploy the model by allowing on-demand synthetic data generation and data export
- Record synthetic data generation requests from the model
- Update the model as the application changes'
Our full enterprise-wide platform system is still underway. With our early access customers, we have successfully navigated through synthetic data creation, iteration, deployment, and updates for select applications.
Looking Towards the Future
Over the past year, we've worked closely with a select set of customers to get more insight into how enterprises operate, and understand the best ways to incorporate synthetic data. In 2023 alone, we made 62 software releases across our libraries, and developed a framework for SDV Enterprise. We also expanded our own team, attracting top engineering and business talent to double in size and scale our capabilities – just this week, we welcomed Elisa Castañer, our very first Director of Business Development. (We are still growing: If you'd like to join a passionate, fast-paced team looking to revolutionize the Generative AI space, please check out our careers page!)
While we are thrilled to announce SDV Enterprise today, we anticipate a few more rounds of iteration and feedback before the product is ready for general availability. In the meantime, we're always looking for more beta users whose vision for Generative AI is aligned with ours. If your team is looking to boost software development productivity with synthetic data, please contact us to inquire about early access.
Shaping the future of Generative AI continues to be a rewarding journey. A feat of this size is only possible through a strong partnership between Product and Engineering. I'm especially grateful to Andrew Montanez, our Director of Engineering, and to the rest of our passionate team. I'm incredibly proud of what we have accomplished so far, and I look forward to even more momentum in 2024.