This topic was researched by Arnav Modi, a community user. Arnav is an aspiring data scientist who spent his summer learning about the SDV and the utility of synthetic data.
The Synthetic Data Vault (SDV) is a publicly available library that allows you to build your own proprietary generative AI model for tabular data. This model can be used for many purposes, ranging from software testing to data augmentation to scenario simulation.
It's generally said that multiple gigabytes of information are required to properly train a generative AI model. But what if you don't have the time or resources to collect and handle large amounts of data? In this article, we'll experiment with training a generative AI using smaller amounts of data. This will help us evaluate whether you can build an effective SDV model using a more workable dataset.
How does the SDV work?
Before we begin with our experiment, it's helpful to review the basics of SDV modeling.
The SDV works on tabular datasets, which are datasets that can be expressed as tables. Columns represent different attributes and rows represent individual observations. For example, the dataset might include observations about users, such as their names, ages and salaries. You train an SDV model by inputting tabular data.
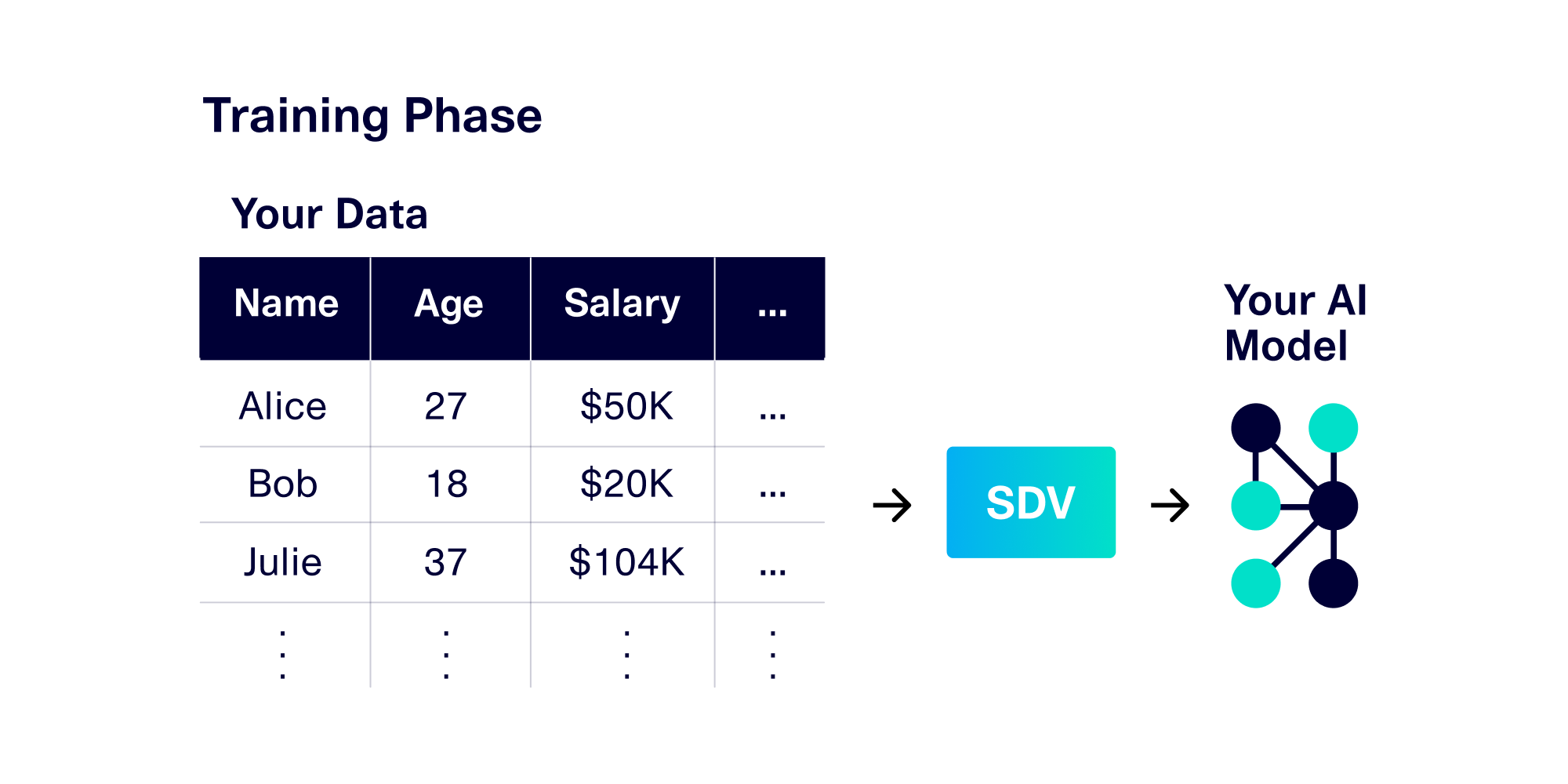
After learning the patterns, the SDV model is able to generate synthetic data on demand, in virtually unlimited quantities. Because the model has been trained on your own dataset, the generated synthetic data has the same basic patterns and format that you're familiar with.
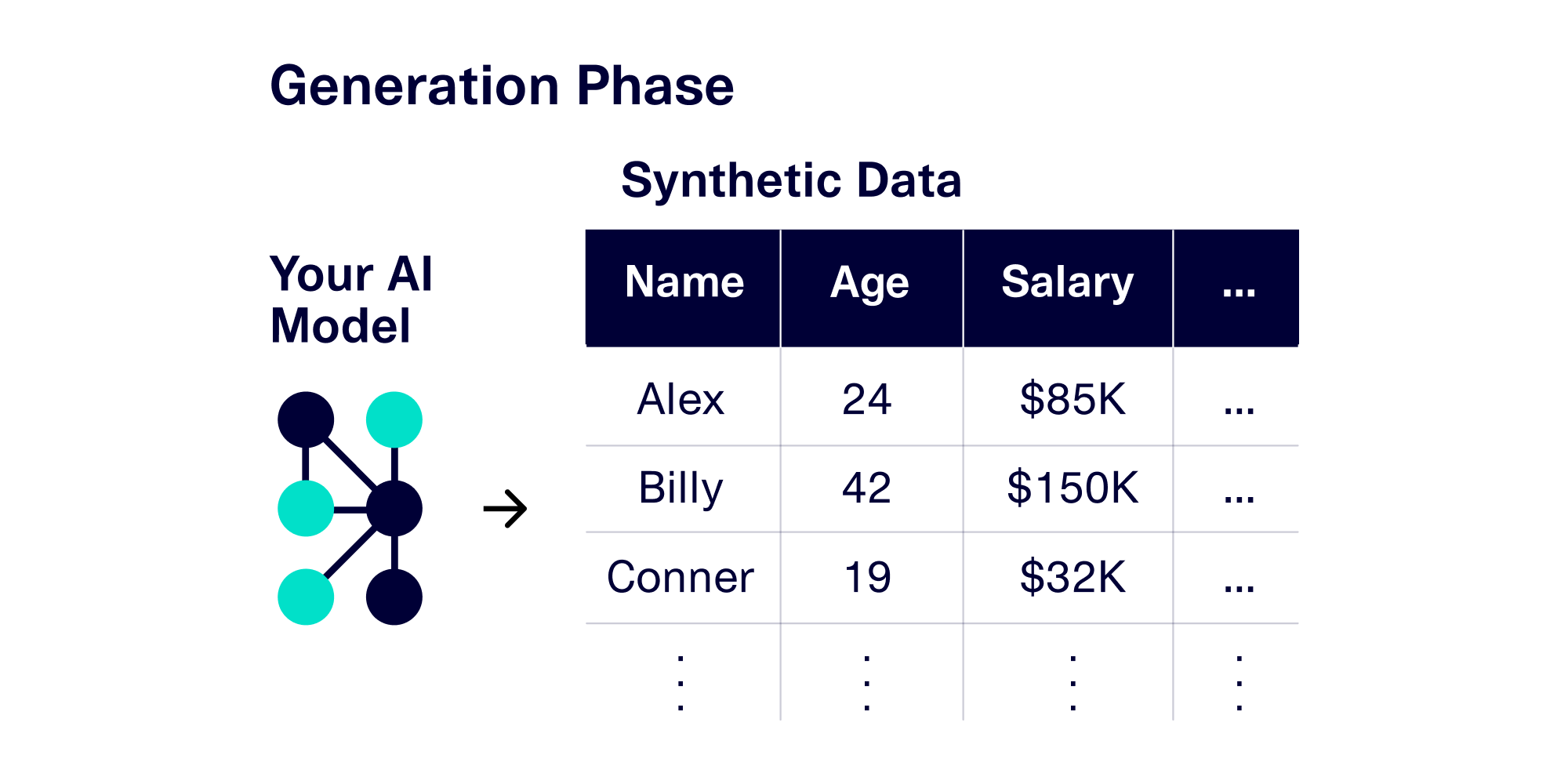
Potential problems may come in the training phase: If you don't have enough training data, there is a concern that the SDV model may not be able to learn relevant patterns, resulting in synthetic data of poor quality. So how much data do you actually need? In our exploration, we'll set out to quantify the effect of the training set size on the overall generative AI model.
Providing a smaller training set: A random subset strategy
Our team wanted to investigate whether selecting a random subset of a full dataset was a viable strategy for reducing the size of training data. This subsample is able to serve as a smaller training set.
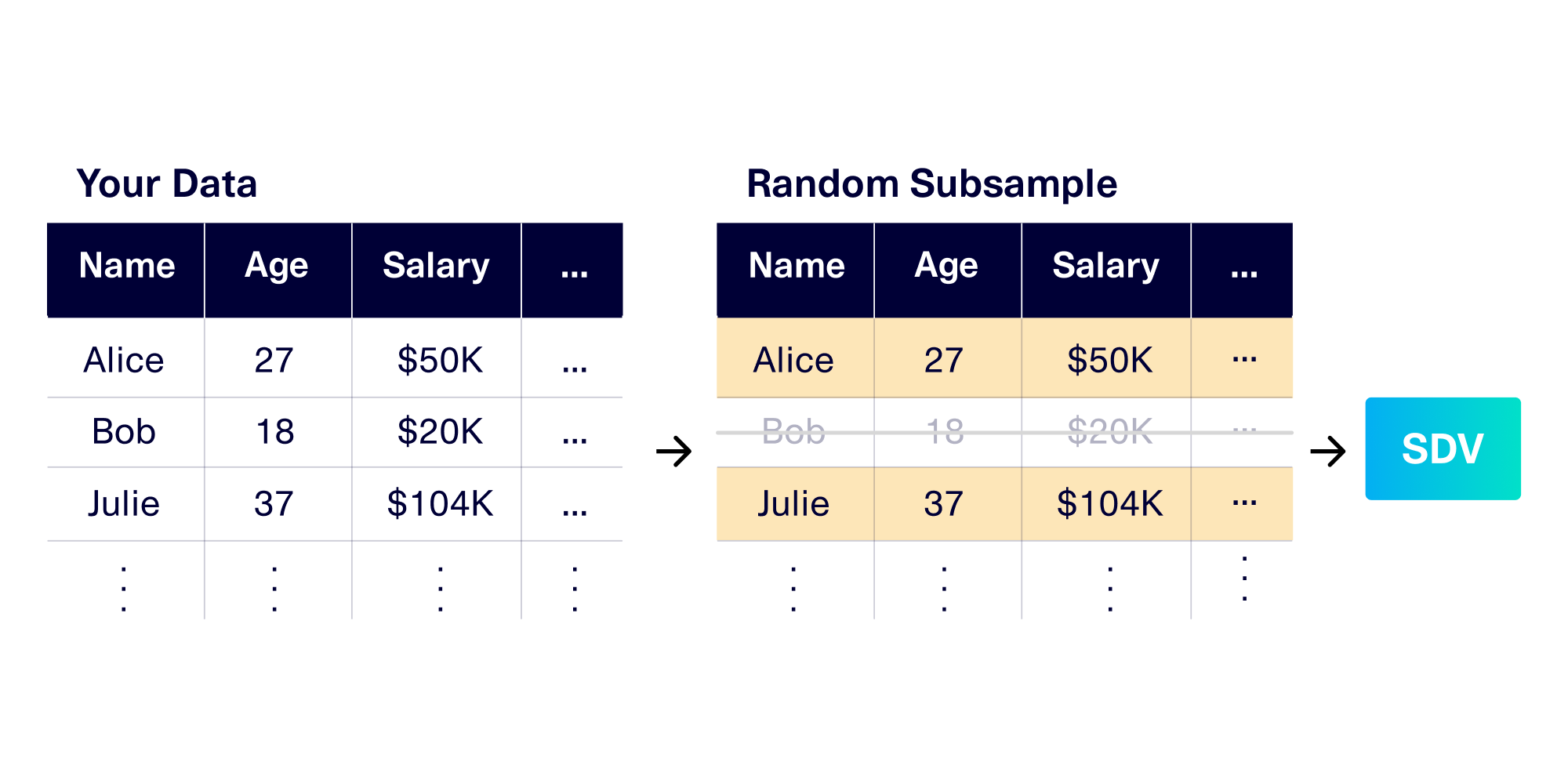
Why is a random subset strategy so appealing? Many of the SDV's customers have large amounts of data stored in database warehouses or data lakes. Most database management systems make it extremely easy to select a random number of records out of a database. This is especially the case for single table data. (The SDV team is also working on ways to create training sets for multi-table data, for customers of SDV Enterprise.)
Experimental Setup
Once we create a smaller sample of data, we can use this to create an SDV model and then compare it against the original SDV model trained with the full dataset. We then test whether models made with random subsets are equally effective at generating synthetic data.
Which dataset should we use? No experiment is complete with just 1 dataset. For our experiment, we use 3 publicly available datasets from Kaggle (Income, Bank and Airline) to gain more confidence in our results. More information about the datasets is shown in the table below.
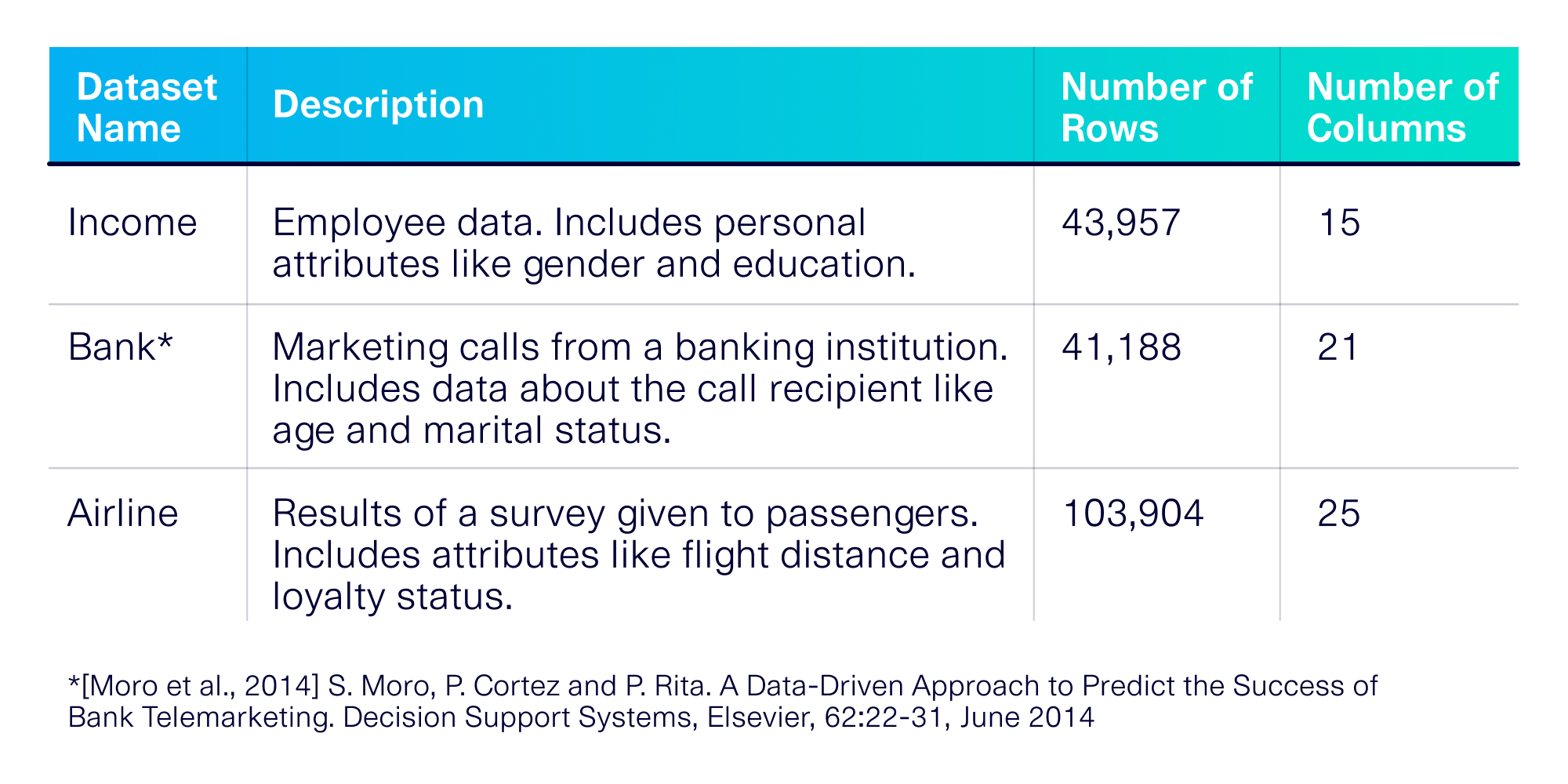
How do we evaluate the trained SDV model? Once we create our SDV model, we use it to generate synthetic data and then evaluate the data's quality. There are many ways to evaluate synthetic data quality (see the variety of options available in the SDMetrics library). For the purposes of our experiment, we measured the synthetic data's effectiveness by using it in an ML prediction task, as was intended by Kaggle. The intended prediction task is presented in the table below.

To accomplish the ML prediction task, we use the synthetic data to train an additional ML classifier model, and then test it on a holdout dataset. This is known as TSTR (train synthetic, test real), as illustrated in the diagram below.
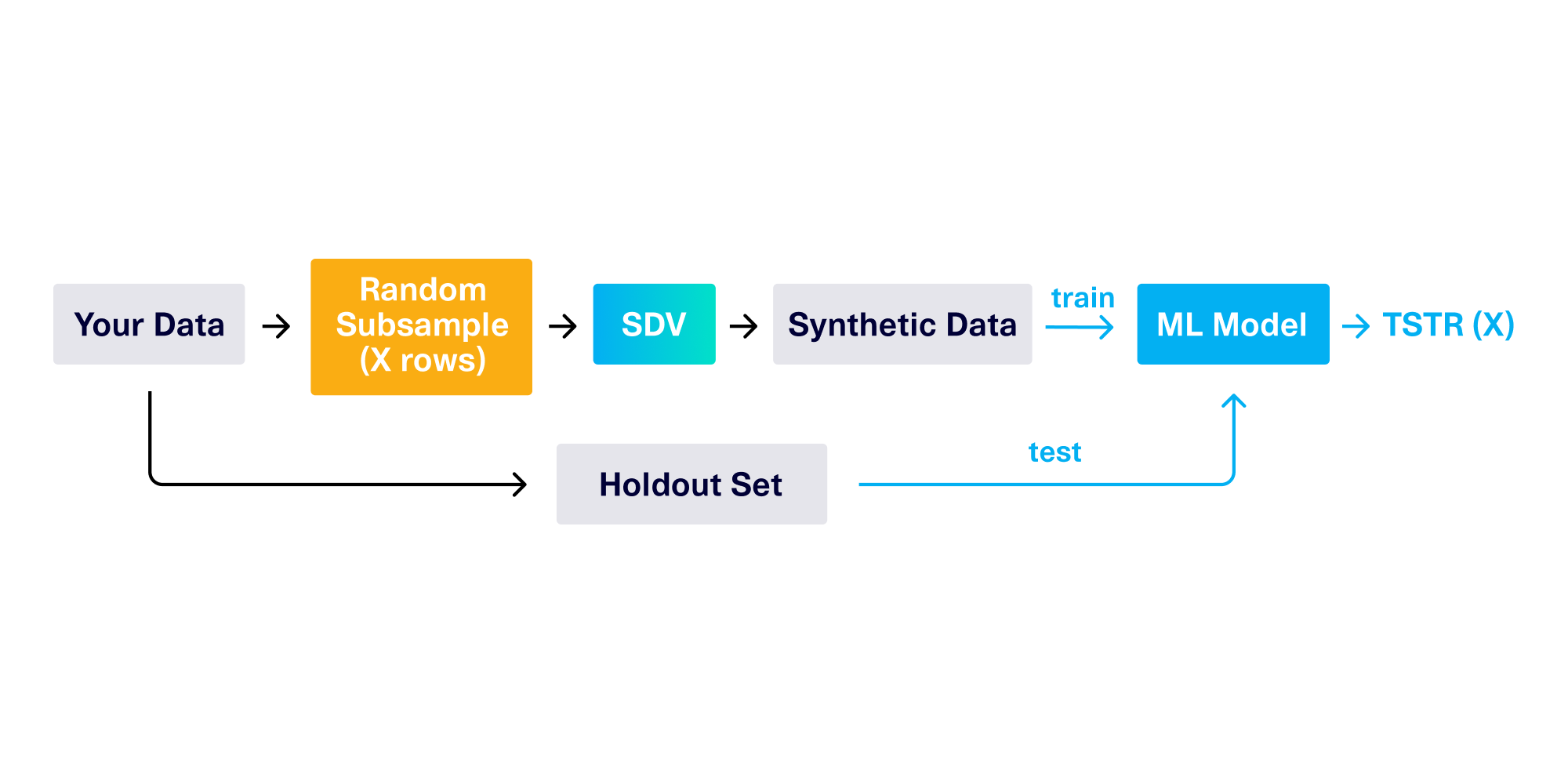
In our experiment, we'll take multiple random subsamples of the real data with different numbers of rows, leading to many different TSTR scores. We'll annotate these with the # of rows used. For example TSTR(10K) refers to a subsample of 10K rows. Meanwhile, TSTR(all) refers to a synthetic data model trained on all rows.
The relative effectiveness of each subsample is its score compared to the score of TSTR(all). The formula below will tell us the effectiveness of sub-sampling x rows:
TSTR(x)/TSTR(all)For more detailed, step-by-step instructions on replicating our experiment, please see our Colab Notebook.
The results: 2.5K rows is enough for this task
Our results showed that our trained SDV models can generally tolerate smaller training set sizes up to a certain point. The graph below shows the average results for each training set size, across 3 iterations.
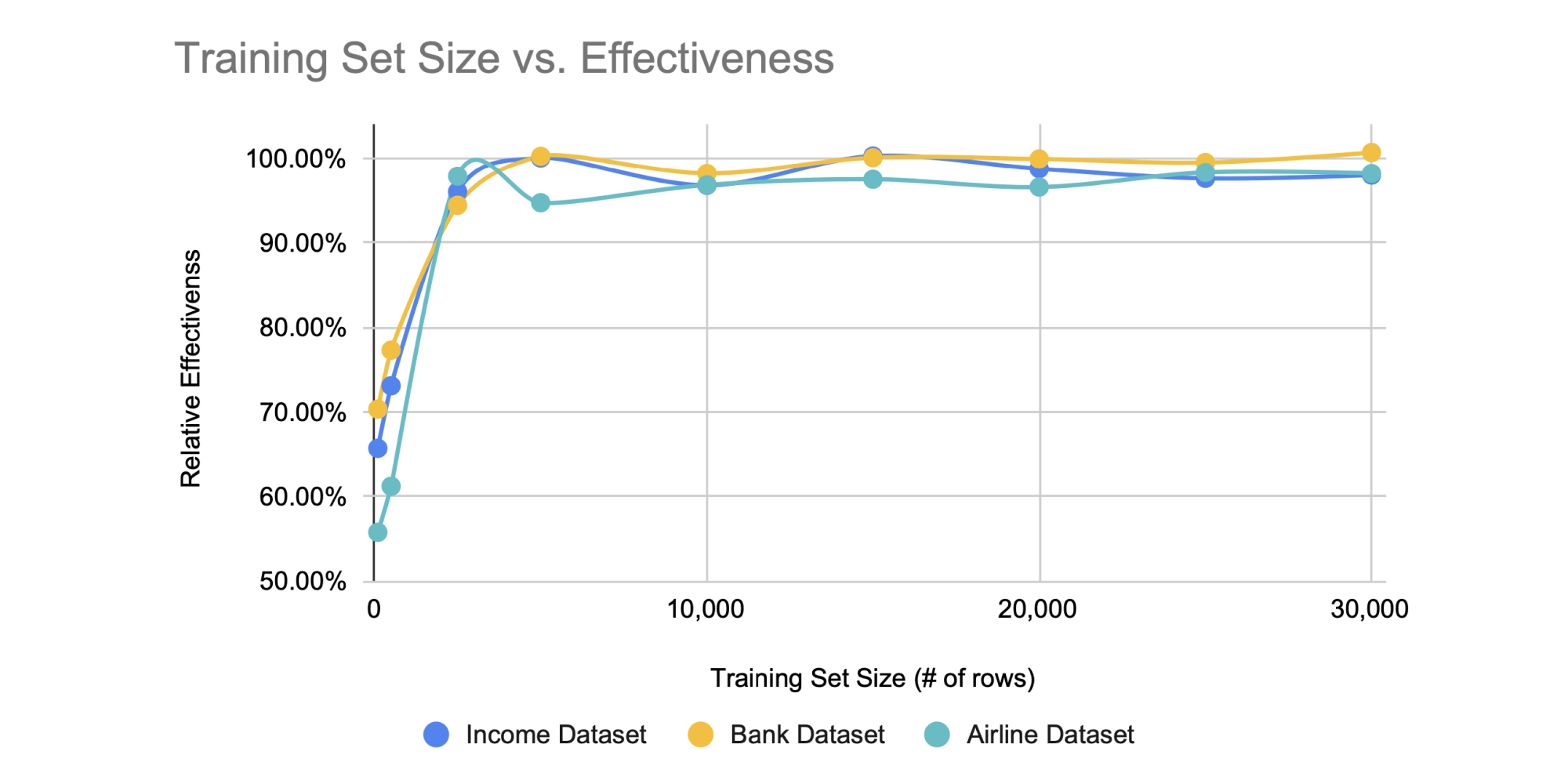
On the x-axis, we show the size of the training set, ranging from a small number of rows (left) to a larger number of rows (right). On the y-axis, we show the relative effectiveness of an SDV model trained on each set, compared to the effectiveness of the model trained on all the data — that is TSTR(# of rows)/TSTR(all).
As expected, larger training sets generally lead to better SDV models. However, this is only true until we reach a certain, critical size. After this, inputting more training data does not contribute meaningfully to the SDV model. Our best explanation is that the SDV learns all the underlying mathematical properties from this critical training size. After this critical size is surpassed, adding more training data only reinforces the same patterns and does not teach the generative AI anything new.
Surprisingly, this critical training size was static – at around 2,500 rows – for all 3 datasets we tested. This was true even though our datasets had different original sizes; for example, the airline dataset has over twice as many rows (~100K) as the other datasets (~40K). This leads us to believe that the original number of rows in your dataset does not matter. This makes sense because you may always be collecting more data, leading to larger and larger dataset sizes. However, the critical size you need for the SDV does not change.
At this time, we don't know if 2.5K rows is the correct size for every dataset. We suspect a few factors will have an effect on this value.
- The number of columns. All our tested datasets had between 15 and 25 columns. More columns will likely mean that the SDV needs more information to learn the patterns.
- The number of tables. All our datasets were single-table. A multi-table application will likely require more data for the SDV to learn the relationships.
- The general complexity of the data. Is there complicated logic? Are there only a handful of important edge cases? The SDV will need more rows to ensure proper coverage.
So if you're using the SDV to create synthetic data, then to be on the safe side, we recommend training it with at least 5K rows on a dataset of 25 columns. As the number of columns increases, you can increase the number of rows at a faster rate. For example, a dataset with 50 columns may need closer to 20K rows to safely learn patterns.
The Takeaway
Our experiments show that you can still build an effective generative AI model for ML tasks by training it with a smaller amount of data. This has important implications for synthetic data projects.
Rather than looking for scalable solutions or increased computing power upfront, we recommend building an initial synthetic data solution from a random subsample of your data. Having synthetic data sooner will allow you to validate whether it's sufficient for your downstream use. If you determine that more training is necessary to capture the patterns, you can then iterate to add more data. This approach can save you upfront costs and help align your team faster on the desired usage of your synthetic data.
Are you up for experimenting with your own datasets? We'd love to hear more about your experiments and what kinds of issues you face when creating synthetic data. Leave a comment below if you think subsampling will be useful for your projects – or join us on Slack to discuss.